Refine search
Actions for selected content:
49493 results in Computer Science
Social impact evaluation analysis: a systematic qualitative method for assessing engineered products
- Part of
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 11 December 2024, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ChatGPT in foreign language lesson plan creation: Trends, variability, and historical biases
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tight bound for the Erdős–Pósa property of tree minors
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 11 December 2024, pp. 321-325
-
- Article
- Export citation
-
Let
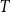 $T$ be a tree on
$T$ be a tree on  $t$ vertices. We prove that for every positive integer
$t$ vertices. We prove that for every positive integer 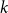 $k$ and every graph
$k$ and every graph 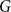 $G$, either
$G$, either 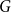 $G$ contains
$G$ contains 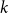 $k$ pairwise vertex-disjoint subgraphs each having a
$k$ pairwise vertex-disjoint subgraphs each having a 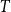 $T$ minor, or there exists a set
$T$ minor, or there exists a set 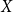 $X$ of at most
$X$ of at most 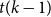 $t(k-1)$ vertices of
$t(k-1)$ vertices of 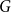 $G$ such that
$G$ such that 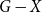 $G-X$ has no
$G-X$ has no 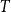 $T$ minor. The bound on the size of
$T$ minor. The bound on the size of 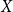 $X$ is best possible and improves on an earlier
$X$ is best possible and improves on an earlier 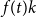 $f(t)k$ bound proved by Fiorini, Joret, and Wood (2013) with some fast-growing function
$f(t)k$ bound proved by Fiorini, Joret, and Wood (2013) with some fast-growing function 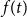 $f(t)$. Moreover, our proof is short and simple.
$f(t)$. Moreover, our proof is short and simple.

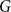
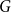
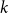
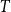
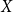
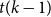
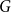
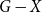
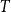
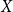
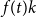
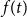
Affective Matter: designing human-material interactions to enhance health and wellbeing
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research on the path planning algorithm and obstacle-crossing motion planning strategy for a cable trench inspection robot
-
- Article
- Export citation
-
The path planning and obstacle-crossing motion planning of cable trench inspection robots are essential for achieving automated inspection. To improve path planning efficiency and obstacle navigation in complex environments, an enhanced global path planning algorithm based on the A* algorithm has been developed, combined with an improved Dynamic Window Approach (DWA) for local path planning. For unavoidable obstacles, a specific obstacle-crossing motion planning strategy has been formulated. The enhanced A* algorithm improves efficiency and safety through adaptive neighborhood expansion and the elimination of redundant path points. The improved DWA algorithm enables real-time dynamic obstacle avoidance in local path planning. The simulation results on a
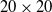 $20 \times 20$ grid map indicate that the improved A* algorithm reduces the number of nodes by 58.4% and shortens the path length by 6.1% compared to the traditional A* algorithm, demonstrating significant advantages over other conventional path planning algorithms. In the simulation experiments integrating global and local path planning, the enhanced A* algorithm combined with the improved DWA algorithm reduces the path length by 3.2% on the
$20 \times 20$ grid map indicate that the improved A* algorithm reduces the number of nodes by 58.4% and shortens the path length by 6.1% compared to the traditional A* algorithm, demonstrating significant advantages over other conventional path planning algorithms. In the simulation experiments integrating global and local path planning, the enhanced A* algorithm combined with the improved DWA algorithm reduces the path length by 3.2% on the 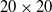 $20 \times 20$ grid map compared to the integration with the traditional DWA algorithm. On the
$20 \times 20$ grid map compared to the integration with the traditional DWA algorithm. On the 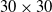 $30 \times 30$ grid maps with different obstacle configurations, the path lengths are reduced by 3.5% and 3.6%, respectively. In the obstacle-crossing experiments, the robot successfully overcame obstacles of 10 cm and 20 cm in height. The proposed path planning algorithm and obstacle-crossing motion planning strategy hold substantial application potential in complex environments, offering reliable technical support for cable trench inspection robots.
$30 \times 30$ grid maps with different obstacle configurations, the path lengths are reduced by 3.5% and 3.6%, respectively. In the obstacle-crossing experiments, the robot successfully overcame obstacles of 10 cm and 20 cm in height. The proposed path planning algorithm and obstacle-crossing motion planning strategy hold substantial application potential in complex environments, offering reliable technical support for cable trench inspection robots.
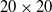
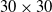
AI for peace: mitigating the risks and enhancing opportunities – ERRATUM
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The radical innovation design comparator to evaluate the effectiveness of design solutions according to usage contexts
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Representations in design computing through 3-D deep generative models
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI innovation in healthcare and state platforms under a rights-based perspective: the case of Brazillian RNDS
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decoder decomposition for the analysis of the latent space of nonlinear autoencoders with wind-tunnel experimental data
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring national infrastructures to support impact analyses of publicly accessible research: a need for trust, transparency, and collaboration at scale
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sampling from the random cluster model on random regular graphs at all temperatures via Glauber dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 359-391
-
- Article
- Export citation
-
We consider the performance of Glauber dynamics for the random cluster model with real parameter
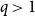 $q\gt 1$ and temperature
$q\gt 1$ and temperature 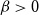 $\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random
$\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random 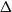 $\Delta$-regular graphs for all sufficiently large
$\Delta$-regular graphs for all sufficiently large 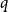 $q$ and obtained an efficient sampling algorithm for all temperatures
$q$ and obtained an efficient sampling algorithm for all temperatures 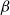 $\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large
$\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large 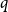 $q$ (with respect to
$q$ (with respect to 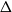 $\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures
$\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures 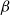 $\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
$\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
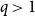
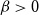
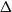
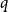
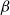
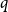
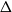
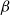
Barlow and Proschan principle for coherent systems with statistically dependent component and redundancy lifetimes
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 141-155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trust norms for generative AI data gathering in the African context
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Universal algebra in UniMath
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 8 / September 2024
- Published online by Cambridge University Press:
- 09 December 2024, pp. 869-891
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Responsible artificial intelligence in Africa: towards policy learning
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The Cambridge Handbook of the Law, Policy, and Regulation for Human–Robot Interaction
-
- Published online:
- 07 December 2024
- Print publication:
- 21 November 2024
