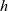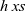Refine search
Actions for selected content:
49493 results in Computer Science
4 - From Rule of Law to Algorithmic Rule by Law
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 151-229
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Contents
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp v-vi
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Figures
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xi-xii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Emerging trends: evaluating general purpose foundation models
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 12 December 2024, pp. 1323-1335
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Legal Safeguards in the EU Legal Order
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 230-296
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Abbreviations
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xxiii-xxiv
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Preface
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xv-xvi
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Illustrations of Algorithmic Regulation
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xiii-xiv
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Table of Cases
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xix-xxii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
3 - The Rule of Law
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 95-150
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Bibliography
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 311-344
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
A review of methods for mapping 3D rotations to one-dimensional planar rotations: analysis, comparison, and a novel efficient Quaternion-based approach
- Part of
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Copyright page
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp iv-iv
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
 $\gamma $-ADMISSIBILITY IN FIRST-ORDER RELEVANT LOGICS: PROOF USING NORMAL MODELS IN THE MARES–GOLDBLATT SETTING
$\gamma $-ADMISSIBILITY IN FIRST-ORDER RELEVANT LOGICS: PROOF USING NORMAL MODELS IN THE MARES–GOLDBLATT SETTING
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 12 December 2024, pp. 398-419
- Print publication:
- June 2025
-
- Article
- Export citation
-
For relevant logics, the admissibility of the rule of proof
 $\gamma $ has played a significant historical role in the development of relevant logics. For first-order logics, however, there have been only a handful of
$\gamma $ has played a significant historical role in the development of relevant logics. For first-order logics, however, there have been only a handful of  $\gamma $-admissibility proofs for a select few logics. Here we show that, for each logic L
$\gamma $-admissibility proofs for a select few logics. Here we show that, for each logic L of a wide range of propositional relevant logics for which excluded middle is valid (with fusion and the Ackermann truth constant), the first-order extensions QL
of a wide range of propositional relevant logics for which excluded middle is valid (with fusion and the Ackermann truth constant), the first-order extensions QL and LQ
and LQ admit
admit  $\gamma $. Specifically, these are particular “conventionally normal” extensions of the logic
$\gamma $. Specifically, these are particular “conventionally normal” extensions of the logic  $\mathbf {G}^{g,d}$, which is the least propositional relevant logic (with the usual relational semantics) that admits
$\mathbf {G}^{g,d}$, which is the least propositional relevant logic (with the usual relational semantics) that admits  $\gamma $ by the method of normal models. We also note the circumstances in which our results apply to logics without fusion and the Ackermann truth constant.
$\gamma $ by the method of normal models. We also note the circumstances in which our results apply to logics without fusion and the Ackermann truth constant.



 of a wide range of propositional relevant logics for which excluded middle is valid (with fusion and the Ackermann truth constant), the first-order extensions
of a wide range of propositional relevant logics for which excluded middle is valid (with fusion and the Ackermann truth constant), the first-order extensions  and
and  admit
admit 


Detailed Contents
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp vii-x
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Acknowledgements
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp xvii-xviii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
An example of goal-directed, calculational proof
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 11 December 2024, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Twin-width of sparse random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 11 December 2024, pp. 401-420
-
- Article
- Export citation
-
We show that the twin-width of every
 $n$-vertex
$n$-vertex 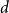 $d$-regular graph is at most
$d$-regular graph is at most 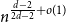 $n^{\frac{d-2}{2d-2}+o(1)}$ for any fixed integer
$n^{\frac{d-2}{2d-2}+o(1)}$ for any fixed integer 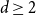 $d \geq 2$ and that almost all
$d \geq 2$ and that almost all 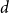 $d$-regular graphs attain this bound. More generally, we obtain bounds on the twin-width of sparse Erdős–Renyi and regular random graphs, complementing the bounds in the denser regime due to Ahn, Chakraborti, Hendrey, Kim, and Oum.
$d$-regular graphs attain this bound. More generally, we obtain bounds on the twin-width of sparse Erdős–Renyi and regular random graphs, complementing the bounds in the denser regime due to Ahn, Chakraborti, Hendrey, Kim, and Oum.

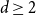
Bottom-up computation using trees of sublists
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 11 December 2024, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Some top-down problem specifications, if executed, may compute sub-problems repeatedly. Instead, we may want a bottom-up algorithm that stores solutions of sub-problems in a table to be reused. How the table can be represented and efficiently maintained, however, can be tricky. We study a special case: computing a function
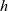 ${\mathit{h}}$ taking lists as inputs such that
${\mathit{h}}$ taking lists as inputs such that 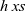 ${\mathit{h}\;\mathit{xs}}$ is defined in terms of all immediate sublists of
${\mathit{h}\;\mathit{xs}}$ is defined in terms of all immediate sublists of  ${\mathit{xs}}$. Richard Bird studied this problem in 2008 and presented a concise but cryptic algorithm without much explanation. We give this algorithm a proper derivation and discovered a key property that allows it to work. The algorithm builds trees that have certain shapes—the sizes along the left spine is a prefix of a diagonal in Pascal’s triangle. The crucial function we derive transforms one diagonal to the next.
${\mathit{xs}}$. Richard Bird studied this problem in 2008 and presented a concise but cryptic algorithm without much explanation. We give this algorithm a proper derivation and discovered a key property that allows it to work. The algorithm builds trees that have certain shapes—the sizes along the left spine is a prefix of a diagonal in Pascal’s triangle. The crucial function we derive transforms one diagonal to the next.