Refine search
Actions for selected content:
49494 results in Computer Science

The Cambridge Handbook of the Law, Policy, and Regulation for Human–Robot Interaction
-
- Published online:
- 07 December 2024
- Print publication:
- 21 November 2024
1 - Introduction
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 1-21
-
- Chapter
- Export citation
Preface
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp v-x
-
- Chapter
- Export citation
6 - Asymmetric Graph TSP
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 114-133
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp i-iv
-
- Chapter
- Export citation
10 - Parity Correction of Random Trees
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 212-230
-
- Chapter
- Export citation
Contents
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp xi-xiv
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 407-422
-
- Chapter
- Export citation
Three-dimensional optical microrobot orientation estimation and tracking using deep learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Optical microrobots are activated by a laser in a liquid medium using optical tweezers. To create visual control loops for robotic automation, this work describes a deep learning-based method for orientation estimation of optical microrobots, focusing on detecting 3-D rotational movements and localizing microrobots and trapping points (TPs). We integrated and fine-tuned You Only Look Once (YOLOv7) and Deep Simple Online Real-time Tracking (DeepSORT) algorithms, improving microrobot and TP detection accuracy by
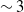 $\sim 3$% and
$\sim 3$% and 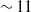 $\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of
$\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of 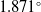 $1.871^\circ$,
$1.871^\circ$, 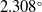 $2.308^\circ$, and
$2.308^\circ$, and 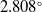 $2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
$2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
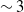
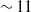
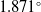
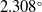
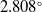
Index
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 423-428
-
- Chapter
- Export citation
16 - Path TSP by Dynamic Programming
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 351-380
-
- Chapter
- Export citation
12 - Removable Pairings
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 265-279
-
- Chapter
- Export citation
18 - State of the Art, Open Problems
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 400-406
-
- Chapter
- Export citation
17 - Further Results, Related Problems
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 381-399
-
- Chapter
- Export citation
9 - Asymmetric Path TSP
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 183-211
-
- Chapter
- Export citation
14 - Symmetric Path TSP and T-Tours
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 303-323
-
- Chapter
- Export citation
Are certain African ethical values at risk from artificial intelligence?
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 05 December 2024, e68
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Linear Programming Relaxations of the Asymmetric TSP
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 47-65
-
- Chapter
- Export citation
