Refine search
Actions for selected content:
49493 results in Computer Science

Mundania
- How and Where Technologies Are Made Ordinary
-
- Published by:
- Bristol University Press
- Published online:
- 17 December 2024
- Print publication:
- 24 January 2024
-
- Book
- Export citation
Supporting early robust design for different levels of specific design knowledge: an adaptive method for modeling with the Embodiment Function Relation and Tolerance model
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 16 December 2024, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reasoning about physical processes in buildings through component stereotypes
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 16 December 2024, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Essential covers of the hypercube require many hyperplanes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 16 December 2024, pp. 326-337
-
- Article
- Export citation
-
We prove a new lower bound for the almost 20-year-old problem of determining the smallest possible size of an essential cover of the
 $n$-dimensional hypercube
$n$-dimensional hypercube 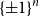 $\{\pm 1\}^n$, that is, the smallest possible size of a collection of hyperplanes that forms a minimal cover of
$\{\pm 1\}^n$, that is, the smallest possible size of a collection of hyperplanes that forms a minimal cover of 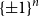 $\{\pm 1\}^n$ and such that, furthermore, every variable appears with a non-zero coefficient in at least one of the hyperplane equations. We show that such an essential cover must consist of at least
$\{\pm 1\}^n$ and such that, furthermore, every variable appears with a non-zero coefficient in at least one of the hyperplane equations. We show that such an essential cover must consist of at least 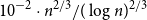 $10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$ hyperplanes, improving previous lower bounds of Linial–Radhakrishnan, of Yehuda–Yehudayoff, and of Araujo–Balogh–Mattos.
$10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$ hyperplanes, improving previous lower bounds of Linial–Radhakrishnan, of Yehuda–Yehudayoff, and of Araujo–Balogh–Mattos.

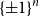
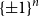
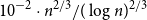

Algorithmic Rule By Law
- How Algorithmic Regulation in the Public Sector Erodes the Rule of Law
-
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024
-
- Book
-
- You have access
- Open access
- Export citation

Introduction to Probability and Statistics for Data Science
- with R
-
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024
-
- Textbook
- Export citation
SATISFACTION CLASSES WITH APPROXIMATE DISJUNCTIVE CORRECTNESS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 13 December 2024, pp. 545-562
- Print publication:
- June 2025
-
- Article
- Export citation
-
The seminal Krajewski–Kotlarski–Lachlan theorem (1981) states that every countable recursively saturated model of
 $\mathsf {PA}$ (Peano arithmetic) carries a full satisfaction class. This result implies that the compositional theory of truth over
$\mathsf {PA}$ (Peano arithmetic) carries a full satisfaction class. This result implies that the compositional theory of truth over  $\mathsf {PA}$ commonly known as
$\mathsf {PA}$ commonly known as  $\mathsf {CT}^{-}[\mathsf {PA}]$ is conservative over
$\mathsf {CT}^{-}[\mathsf {PA}]$ is conservative over  $\mathsf {PA}$. In contrast, Pakhomov and Enayat (2019) showed that the addition of the so-called axiom of disjunctive correctness (that asserts that a finite disjunction is true iff one of its disjuncts is true) to
$\mathsf {PA}$. In contrast, Pakhomov and Enayat (2019) showed that the addition of the so-called axiom of disjunctive correctness (that asserts that a finite disjunction is true iff one of its disjuncts is true) to  $\mathsf {CT}^{-}[\mathsf {PA}]$ axiomatizes the theory of truth
$\mathsf {CT}^{-}[\mathsf {PA}]$ axiomatizes the theory of truth  $\mathsf {CT}_{0}[\mathsf {PA}]$ that was shown by Wcisło and Łełyk (2017) to be nonconservative over
$\mathsf {CT}_{0}[\mathsf {PA}]$ that was shown by Wcisło and Łełyk (2017) to be nonconservative over  $\mathsf {PA}$. The main result of this paper (Theorem 3.12) provides a foil to the Pakhomov–Enayat theorem by constructing full satisfaction classes over arbitrary countable recursively saturated models of
$\mathsf {PA}$. The main result of this paper (Theorem 3.12) provides a foil to the Pakhomov–Enayat theorem by constructing full satisfaction classes over arbitrary countable recursively saturated models of  $\mathsf {PA}$ that satisfy arbitrarily large approximations of disjunctive correctness. This shows that in the Pakhomov–Enayat theorem the assumption of disjunctive correctness cannot be replaced with any of its approximations.
$\mathsf {PA}$ that satisfy arbitrarily large approximations of disjunctive correctness. This shows that in the Pakhomov–Enayat theorem the assumption of disjunctive correctness cannot be replaced with any of its approximations.








The transfer learning of uncertainty quantification for industrial plant fault diagnosis system design
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing resilience in IoT cybersecurity: the roles of obfuscation and diversification techniques for improving the multilayered cybersecurity of IoT systems
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the seasonal performance and electricity consumption of retrofitted heat pumps
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tree universality in positional games
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 13 December 2024, pp. 338-358
-
- Article
- Export citation
-
In this paper we consider positional games where the winning sets are edge sets of tree-universal graphs. Specifically, we show that in the unbiased Maker-Breaker game on the edges of the complete graph
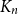 $K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most
$K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most 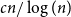 $cn/\log (n)$, for a suitable constant
$cn/\log (n)$, for a suitable constant  $c$ and
$c$ and  $n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
$n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
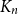
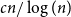


QuantiVA: quantitative verification of autonomous driving
-
- Journal:
- Research Directions: Cyber-Physical Systems / Volume 3 / 2025
- Published online by Cambridge University Press:
- 13 December 2024, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transfer learning for predicting source terms of principal component transport in chemically reactive flow
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Index
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 345-356
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
2 - Algorithmic Regulation
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 26-94
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
6 - Conclusions
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 297-310
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
1 - Introduction
-
- Book:
- Algorithmic Rule By Law
- Published online:
- 14 December 2024
- Print publication:
- 12 December 2024, pp 1-25
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
