Refine search
Actions for selected content:
48584 results in Computer Science
Total unfolding: theory and applications
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 4 / Issue 4 / October 1994
- Published online by Cambridge University Press:
- 07 November 2008, pp. 479-498
-
- Article
-
- You have access
- Export citation
Sparse matrix representations in a functional language
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 1 / January 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. 143-170
-
- Article
-
- You have access
- Export citation
JFP volume 2 issue 1 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 2 / Issue 1 / January 1992
- Published online by Cambridge University Press:
- 07 November 2008, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Quantifier elimination and parametric polymorphism in programming languages
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 2 / Issue 2 / April 1992
- Published online by Cambridge University Press:
- 07 November 2008, pp. 213-226
-
- Article
-
- You have access
- Export citation
A practical functional program for the CRAY X-MP*
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 2 / Issue 1 / January 1992
- Published online by Cambridge University Press:
- 07 November 2008, pp. 81-126
-
- Article
-
- You have access
- Export citation
Functional Pearls: The Minout problem
-
- Journal:
- Journal of Functional Programming / Volume 1 / Issue 1 / January 1991
- Published online by Cambridge University Press:
- 07 November 2008, pp. 121-124
-
- Article
-
- You have access
- Export citation
π-RED+ An interactive compiling graph reduction system for an applied λ-calculus
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 5 / September 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. 723-756
-
- Article
-
- You have access
- Export citation
Partially strict non-recursive data types
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 3 / Issue 2 / April 1993
- Published online by Cambridge University Press:
- 07 November 2008, pp. 191-215
-
- Article
-
- You have access
- Export citation
JFP volume 5 issue 3 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 5 / Issue 3 / July 1995
- Published online by Cambridge University Press:
- 07 November 2008, pp. b1-b4
-
- Article
-
- You have access
- Export citation
Deciding type isomorphisms in a type-assignment framework†
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 3 / Issue 4 / October 1993
- Published online by Cambridge University Press:
- 07 November 2008, pp. 485-525
-
- Article
-
- You have access
- Export citation
Simple type-theoretic foundations for object-oriented programming
-
- Journal:
- Journal of Functional Programming / Volume 4 / Issue 2 / April 1994
- Published online by Cambridge University Press:
- 07 November 2008, pp. 207-247
-
- Article
-
- You have access
- Export citation
JFP volume 5 issue 4 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 5 / Issue 4 / October 1995
- Published online by Cambridge University Press:
- 07 November 2008, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Semantics directed program execution monitoring†
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 5 / Issue 4 / October 1995
- Published online by Cambridge University Press:
- 07 November 2008, pp. 501-547
-
- Article
-
- You have access
- Export citation
JFP volume 6 issue 5 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 5 / September 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. b1-b3
-
- Article
-
- You have access
- Export citation
Functional Pearl: Back to basics: Deriving representation changers functionally
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 1 / January 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. 181-188
-
- Article
-
- You have access
- Export citation
Combinators for parsing expressions
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 3 / May 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. 445-464
-
- Article
-
- You have access
- Export citation
Theoretical Pearls: Representing ‘undefined’ in lambda calculus
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 2 / Issue 3 / July 1992
- Published online by Cambridge University Press:
- 07 November 2008, pp. 367-374
-
- Article
-
- You have access
- Export citation
-
Let ψ be a partial recursive function (of one argument) with λ-defining term F∈Λ°. This means
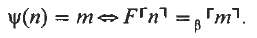 There are several proposals for what F⌜n⌝ should be in case ψ(n) is undefined: (1) a term without a normal form (Church); (2) an unsolvable term (Barendregt); (3) an easy term (Visser); (4) a term of order 0 (Statman).
There are several proposals for what F⌜n⌝ should be in case ψ(n) is undefined: (1) a term without a normal form (Church); (2) an unsolvable term (Barendregt); (3) an easy term (Visser); (4) a term of order 0 (Statman).These four possibilities will be covered by one ‘master’ result of Statman which is based on the ‘Anti Diagonal Normalization Theorem’ of Visser (1980). That ingenious theorem about precomplete numerations of Ershov is a powerful tool with applications in recursion theory, metamathematics of arithmetic and lambda calculus.
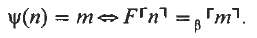
Erratum
-
- Journal:
- Journal of Functional Programming / Volume 3 / Issue 4 / October 1993
- Published online by Cambridge University Press:
- 07 November 2008, p. 389
-
- Article
-
- You have access
- Export citation
Reference counting as a computational interpretation of linear logic
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 6 / Issue 2 / March 1996
- Published online by Cambridge University Press:
- 07 November 2008, pp. 195-244
-
- Article
-
- You have access
- Export citation
Implementing the evaluation transformer model of reduction on parallel machines
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 1 / Issue 3 / July 1991
- Published online by Cambridge University Press:
- 07 November 2008, pp. 329-366
-
- Article
-
- You have access
- Export citation
