Refine search
Actions for selected content:
48572 results in Computer Science
A Matroid Reconstruction Result
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 3 / September 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. 371-373
-
- Article
- Export citation
NLE volume 1 issue 1 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. f1-f2
-
- Article
- Export citation
Shortcutting Planar Digraphs*
-
- Journal:
- Combinatorics, Probability and Computing / Volume 4 / Issue 3 / September 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 287-315
-
- Article
- Export citation
Precoloring Extension III: Classes of Perfect Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 5 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 12 September 2008, pp. 35-56
-
- Article
- Export citation
Natural language interfaces to databases – an introduction
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 29-81
-
- Article
- Export citation
Small Submatroids in Random Matroids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 5 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 12 September 2008, pp. 257-266
-
- Article
- Export citation
CPC volume 3 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 3 / September 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. f1-f2
-
- Article
-
- You have access
- Export citation
A Probabilistic Analysis of a String Editing Problem and its Variations†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 4 / Issue 2 / June 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 143-166
-
- Article
- Export citation
On the Number of Convex Lattice Polygons
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 295-302
-
- Article
- Export citation
On Subgraph Sizes in Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 2 / June 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 123-134
-
- Article
- Export citation
On a Random Instance of a ‘Stable Roommates’ Problem: Likely Behavior of the Proposal Algorithm
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 1 / March 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 53-92
-
- Article
- Export citation
NLE volume 1 issue 1 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. b1-b3
-
- Article
- Export citation
POETIC: A system for gathering and disseminating traffic information†
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 4 / December 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 363-388
-
- Article
- Export citation
On the Thickness of Sparse Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 303-309
-
- Article
- Export citation
CPC volume 2 issue 1 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 1 / March 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Threshold Functions for H-factors
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 2 / June 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 137-144
-
- Article
- Export citation
-
Let H be a graph on h vertices, and G be a graph on n vertices. An H-factor of G is a spanning subgraph of G consisting of n/h vertex disjoint copies of H. The fractional arboricity of H is
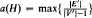 , where the maximum is taken over all subgraphs (V′, E′) of H with |V′| > 1. Let δ(H) denote the minimum degree of a vertex of H. It is shown that if δ(H) < a(H), then n−1/a(H) is a sharp threshold function for the property that the random graph G(n, p) contains an H-factor. That is, there are two positive constants c and C so that for p(n) = cn−1/a(H) almost surely G(n, p(n)) does not have an H-factor, whereas for p(n) = Cn−1/a(H), almost surely G(n, p(n)) contains an H-factor (provided h divides n). A special case of this answers a problem of Erdős.
, where the maximum is taken over all subgraphs (V′, E′) of H with |V′| > 1. Let δ(H) denote the minimum degree of a vertex of H. It is shown that if δ(H) < a(H), then n−1/a(H) is a sharp threshold function for the property that the random graph G(n, p) contains an H-factor. That is, there are two positive constants c and C so that for p(n) = cn−1/a(H) almost surely G(n, p(n)) does not have an H-factor, whereas for p(n) = Cn−1/a(H), almost surely G(n, p(n)) contains an H-factor (provided h divides n). A special case of this answers a problem of Erdős.
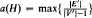 , where the maximum is taken over all subgraphs (
, where the maximum is taken over all subgraphs (Turán-Ramsey Theorems and Kp-Independence Numbers
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 3 / September 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. 297-325
-
- Article
- Export citation
-
Let the Kp-independence number αp (G) of a graph G be the maximum order of an induced subgraph in G that contains no Kp. (So K2-independence number is just the maximum size of an independent set.) For given integers r, p, m > 0 and graphs L1,…,Lr, we define the corresponding Turán-Ramsey function RTp(n, L1,…,Lr, m) to be the maximum number of edges in a graph Gn of order n such that αp(Gn) ≤ m and there is an edge-colouring of G with r colours such that the jth colour class contains no copy of Lj, for j = 1,…, r. In this continuation of [11] and [12], we will investigate the problem where, instead of α(Gn) = o(n), we assume (for some fixed p > 2) the stronger condition that αp(Gn) = o(n). The first part of the paper contains multicoloured Turán-Ramsey theorems for graphs Gn of order n with small Kp-independence number αp(Gn). Some structure theorems are given for the case αp(Gn) = o(n), showing that there are graphs with fairly simple structure that are within o(n2) of the extremal size; the structure is described in terms of the edge densities between certain sets of vertices.
The second part of the paper is devoted to the case r = 1, i.e., to the problem of determining the asymptotic value of
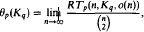
for p < q. Several results are proved, and some other problems and conjectures are stated.
CPC volume 4 issue 2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 4 / Issue 2 / June 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. f1-f2
-
- Article
-
- You have access
- Export citation
The Induced Size-Ramsey Number of Cycles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 4 / Issue 3 / September 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 217-239
-
- Article
- Export citation
Natural language processing in an operational clinical information system
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 83-108
-
- Article
- Export citation
