Refine search
Actions for selected content:
48284 results in Computer Science
6 - The Privacy Phoenix
- from Part II - Who Are the Choice-Makers?
-
- Book:
- Unwired
- Published online:
- 29 April 2023
- Print publication:
- 28 March 2023, pp 80-94
-
- Chapter
- Export citation
12 - Acupuncture for Change
- from Part III - Fighting for Choice
-
- Book:
- Unwired
- Published online:
- 29 April 2023
- Print publication:
- 28 March 2023, pp 164-176
-
- Chapter
- Export citation
10 - The Ground Is Burning
- from Part III - Fighting for Choice
-
- Book:
- Unwired
- Published online:
- 29 April 2023
- Print publication:
- 28 March 2023, pp 135-147
-
- Chapter
- Export citation
5 - The Food Wars
- from Part II - Who Are the Choice-Makers?
-
- Book:
- Unwired
- Published online:
- 29 April 2023
- Print publication:
- 28 March 2023, pp 62-79
-
- Chapter
- Export citation
An EEG-based method to decode cognitive factors in creative processes
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tangential-force detection ability of three-axis fingernail-color sensor aided by CNN
-
- Article
- Export citation
-
We create a new tactile recording system with which we develop a three-axis fingernail-color sensor that can measure a three-dimensional force applied to fingertips by observing the change of the fingernail’s color. Since the color change is complicated, the relationships between images and three-dimensional forces were assessed using convolution neural network (CNN) models. The success of this method depends on the input data size because the CNN model learning requires big data. Thus, to efficiently obtain big data, we developed a novel measuring device, which was composed of an electronic scale and a load cell, to obtain fingernail images with 0
 $^\circ$ to 360
$^\circ$ to 360 $^\circ$ directional tangential force. We performed a series of evaluation experiments to obtain movies of the color changes caused by the three-axis forces and created a data set for the CNN models by transforming the movies to still images. Although we produced a generalized CNN model that can evaluate the images of any person’s fingernails, its root means square error (RMSE) exceeded both the whole and individual models, and the individual models showed the smallest RMSE. Therefore, we adopted the individual models, which precisely evaluated the tangential-force direction of the test data in an
$^\circ$ directional tangential force. We performed a series of evaluation experiments to obtain movies of the color changes caused by the three-axis forces and created a data set for the CNN models by transforming the movies to still images. Although we produced a generalized CNN model that can evaluate the images of any person’s fingernails, its root means square error (RMSE) exceeded both the whole and individual models, and the individual models showed the smallest RMSE. Therefore, we adopted the individual models, which precisely evaluated the tangential-force direction of the test data in an 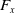 $F_x$-
$F_x$-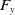 $F_y$ plane within around
$F_y$ plane within around 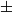 $\pm$2.5
$\pm$2.5 $^\circ$ error at the peak points of the applied force. Although the fingernail-color sensor possessed almost the same level of accuracy as previous sensors for normal-force tests, the present fingernail-color sensor acts as the best tangential sensor because the RMSE obtained from tangential-force tests was around 1/3 that of previous studies.
$^\circ$ error at the peak points of the applied force. Although the fingernail-color sensor possessed almost the same level of accuracy as previous sensors for normal-force tests, the present fingernail-color sensor acts as the best tangential sensor because the RMSE obtained from tangential-force tests was around 1/3 that of previous studies.


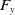
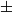

Responding to the coronavirus disease-2019 pandemic with innovative data use: The role of data challenges
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 27 March 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local Yoneda completions of quasi-metric spaces
-
- Journal:
- Mathematical Structures in Computer Science / Volume 33 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 24 March 2023, pp. 33-45
-
- Article
- Export citation
-
In this paper, we study quasi-metric spaces using domain theory. Given a quasi-metric space (X,d), we use
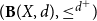 $({\bf B}(X,d),\leq^{d^{+}}\!)$ to denote the poset of formal balls of the associated quasi-metric space (X,d). We introduce the notion of local Yoneda-complete quasi-metric spaces in terms of domain-theoretic properties of
$({\bf B}(X,d),\leq^{d^{+}}\!)$ to denote the poset of formal balls of the associated quasi-metric space (X,d). We introduce the notion of local Yoneda-complete quasi-metric spaces in terms of domain-theoretic properties of 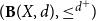 $({\bf B}(X,d),\leq^{d^{+}}\!)$. The manner in which this definition is obtained is inspired by Romaguera–Valero theorem and Kostanek–Waszkiewicz theorem. Furthermore, we obtain characterizations of local Yoneda-complete quasi-metric spaces via local nets in quasi-metric spaces. More precisely, we prove that a quasi-metric space is local Yoneda-complete if and only if every local net has a d-limit. Finally, we prove that every quasi-metric space has a local Yoneda completion.
$({\bf B}(X,d),\leq^{d^{+}}\!)$. The manner in which this definition is obtained is inspired by Romaguera–Valero theorem and Kostanek–Waszkiewicz theorem. Furthermore, we obtain characterizations of local Yoneda-complete quasi-metric spaces via local nets in quasi-metric spaces. More precisely, we prove that a quasi-metric space is local Yoneda-complete if and only if every local net has a d-limit. Finally, we prove that every quasi-metric space has a local Yoneda completion.
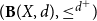
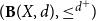
A network-based discrete choice model for decision-based design
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 24 March 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Information-theoretic Cryptography
-
- Published online:
- 23 March 2023
- Print publication:
- 13 April 2023

Introduction to Environmental Data Science
-
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023
17 - Merging of Machine Learning and Physics
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 549-568
-
- Chapter
- Export citation
8 - Learning and Generalization
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 245-282
-
- Chapter
- Export citation
13 - Kernel Methods
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 440-472
-
- Chapter
- Export citation
10 - Unsupervised Learning
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 330-371
-
- Chapter
- Export citation
15 - Deep Learning
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 494-517
-
- Chapter
- Export citation
9 - Principal Components and Canonical Correlation
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 283-329
-
- Chapter
- Export citation
16 - Forecast Verification and Post-processing
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 518-548
-
- Chapter
- Export citation
Index
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 613-628
-
- Chapter
- Export citation
