Refine search
Actions for selected content:
48274 results in Computer Science
Community interaction in open business models: how IoT companies can handle community-generated innovation
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 15 March 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing with biobased composites: understanding digital material perception through semiotic attributes
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 15 March 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic linearized generalized alternating direction method of multipliers: Expected convergence rates and large deviation properties
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 3 / March 2024
- Published online by Cambridge University Press:
- 14 March 2023, pp. 162-179
-
- Article
- Export citation
-
Alternating direction method of multipliers (ADMM) receives much attention in the field of optimization and computer science, etc. The generalized ADMM (G-ADMM) proposed by Eckstein and Bertsekas incorporates an acceleration factor and is more efficient than the original ADMM. However, G-ADMM is not applicable in some models where the objective function value (or its gradient) is computationally costly or even impossible to compute. In this paper, we consider the two-block separable convex optimization problem with linear constraints, where only noisy estimations of the gradient of the objective function are accessible. Under this setting, we propose a stochastic linearized generalized ADMM (called SLG-ADMM) where two subproblems are approximated by some linearization strategies. And in theory, we analyze the expected convergence rates and large deviation properties of SLG-ADMM. In particular, we show that the worst-case expected convergence rates of SLG-ADMM are
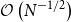 $\mathcal{O}\left( {{N}^{-1/2}}\right)$ and
$\mathcal{O}\left( {{N}^{-1/2}}\right)$ and 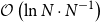 $\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has
$\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has 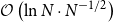 $\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and
$\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and 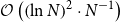 $\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
$\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
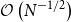
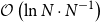
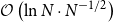
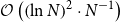
AN ALGORITHMIC IMPOSSIBLE-WORLDS MODEL OF BELIEF AND KNOWLEDGE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 13 March 2023, pp. 586-610
- Print publication:
- June 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, I develop an algorithmic impossible-worlds model of belief and knowledge that provides a middle ground between models that entail that everyone is logically omniscient and those that are compatible with even the most egregious kinds of logical incompetence. In outline, the model entails that an agent believes (knows)
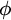 $\phi $ just in case she can easily (and correctly) compute that
$\phi $ just in case she can easily (and correctly) compute that 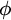 $\phi $ is true and thus has the capacity to make her actions depend on whether
$\phi $ is true and thus has the capacity to make her actions depend on whether 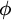 $\phi $. The model thereby captures the standard view that belief and knowledge ground are constitutively connected to dispositions to act. As I explain, the model improves upon standard algorithmic models developed by Parikh, Halpern, Moses, Vardi, and Duc, among other ways, by integrating them into an impossible-worlds framework. The model also avoids some important disadvantages of recent candidate middle-ground models based on dynamic epistemic logic or step logic, and it can subsume their most important advantages.
$\phi $. The model thereby captures the standard view that belief and knowledge ground are constitutively connected to dispositions to act. As I explain, the model improves upon standard algorithmic models developed by Parikh, Halpern, Moses, Vardi, and Duc, among other ways, by integrating them into an impossible-worlds framework. The model also avoids some important disadvantages of recent candidate middle-ground models based on dynamic epistemic logic or step logic, and it can subsume their most important advantages.
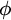
Time-optimal path following for non-redundant serial manipulators using an adaptive path-discretization
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A few-shot semantic segmentation method based on adaptively mining correlation network
-
- Article
- Export citation
-
The goal of few-shot semantic segmentation is to learn a segmentation model that can segment novel classes in queries when only a few annotated support examples are available. Due to large intra-class variations, the building of accurate semantic correlation remains a challenging job. Current methods typically use 4D kernels to learn the semantic correlation of feature maps. However, they still face the challenge of reducing the consumption of computation and memory while keeping the availability of correlations mined by their methods. In this paper, we propose the adaptively mining correlation network (AMCNet) to alleviate the aforementioned issues. The key points of AMCNet are the proposed adaptive separable 4D kernel and the learnable pyramid correlation module, which form the basic block for correlation encoder and provide a learnable concatenation operation over pyramid correlation tensors, respectively. Experiments on the PASCAL VOC 2012 dataset show that our AMCNet surpasses the state-of-the-art method by
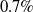 $0.7\%$ and
$0.7\%$ and 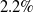 $2.2\%$ on 1-shot and 5-shot segmentation scenarios, respectively.
$2.2\%$ on 1-shot and 5-shot segmentation scenarios, respectively.
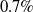
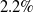
A new measure of inaccuracy for record statistics based on extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 207-225
-
- Article
-
- You have access
- HTML
- Export citation
Phase transitions in biased opinion dynamics with 2-choices rule
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 227-244
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a model of binary opinion dynamics where one opinion is inherently “superior” than the other, and social agents exhibit a “bias” toward the superior alternative. Specifically, it is assumed that an agent updates its choice to the superior alternative with probability α > 0 irrespective of its current opinion and opinions of other agents. With probability
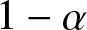 $1-\alpha$, it adopts majority opinion among two randomly sampled neighbors and itself. We are interested in the time it takes for the network to converge to a consensus on the superior alternative. In a complete graph of size n, we show that irrespective of the initial configuration of the network, the average time to reach consensus scales as
$1-\alpha$, it adopts majority opinion among two randomly sampled neighbors and itself. We are interested in the time it takes for the network to converge to a consensus on the superior alternative. In a complete graph of size n, we show that irrespective of the initial configuration of the network, the average time to reach consensus scales as 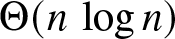 $\Theta(n\,\log n)$ when the bias parameter α is sufficiently high, that is,
$\Theta(n\,\log n)$ when the bias parameter α is sufficiently high, that is,  $\alpha \gt \alpha_c$ where αc is a threshold parameter that is uniquely characterized. When the bias is low, that is, when
$\alpha \gt \alpha_c$ where αc is a threshold parameter that is uniquely characterized. When the bias is low, that is, when 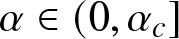 $\alpha \in (0,\alpha_c]$, we show that the same rate of convergence can only be achieved if the initial proportion of agents with the superior opinion is above certain threshold
$\alpha \in (0,\alpha_c]$, we show that the same rate of convergence can only be achieved if the initial proportion of agents with the superior opinion is above certain threshold 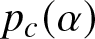 $p_c(\alpha)$. If this is not the case, then we show that the network takes
$p_c(\alpha)$. If this is not the case, then we show that the network takes 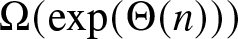 $\Omega(\exp(\Theta(n)))$ time on average to reach consensus.
$\Omega(\exp(\Theta(n)))$ time on average to reach consensus.
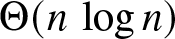

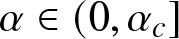
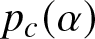
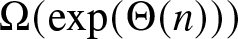
Analytical expression of motion profiles with elliptic jerk
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Basic Tools
- from Part I - Preliminaries
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 8-26
-
- Chapter
- Export citation
Conventions/Notations
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xi-xiv
-
- Chapter
- Export citation
Author Index
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 216-217
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp x-x
-
- Chapter
- Export citation
7 - Small Subgraphs
- from Part II - Erdős–Rényi–Gilbert Model
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 85-92
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 218-218
-
- Chapter
- Export citation
5 - Vertex Degrees
- from Part II - Erdős–Rényi–Gilbert Model
-
- Book:
- Random Graphs and Networks: A First Course
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 64-77
-
- Chapter
- Export citation
