Refine search
Actions for selected content:
49426 results in Computer Science
Characterizing conflict-free and naive labellings—realizabiliy, uniqueness and patterns of redundancy
-
- Journal:
- The Knowledge Engineering Review / Volume 40 / 2025
- Published online by Cambridge University Press:
- 05 December 2025, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Finlandised electobots and the distortion of collective political memory
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 04 December 2025, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Conflict-free hypergraph matchings and coverings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 230-254
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent work showing the existence of conflict-free almost-perfect hypergraph matchings has found many applications. We show that, assuming certain simple degree and codegree conditions on the hypergraph
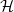 $ \mathcal{H}$ and the conflicts to be avoided, a conflict-free almost-perfect matching can be extended to one covering all vertices in a particular subset of
$ \mathcal{H}$ and the conflicts to be avoided, a conflict-free almost-perfect matching can be extended to one covering all vertices in a particular subset of 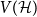 $ V(\mathcal{H})$, by using an additional set of edges; in particular, we ensure that our matching avoids all additional conflicts, which may consist of both old and new edges. This setup is useful for various applications in design theory and Ramsey theory. For example, our main result provides a crucial tool in the recent proof of the high-girth existence conjecture due to Delcourt and Postle. It also provides a black box which encapsulates many long and tedious calculations, greatly simplifying the proofs of results in generalised Ramsey theory.
$ V(\mathcal{H})$, by using an additional set of edges; in particular, we ensure that our matching avoids all additional conflicts, which may consist of both old and new edges. This setup is useful for various applications in design theory and Ramsey theory. For example, our main result provides a crucial tool in the recent proof of the high-girth existence conjecture due to Delcourt and Postle. It also provides a black box which encapsulates many long and tedious calculations, greatly simplifying the proofs of results in generalised Ramsey theory.
Inductive inference from weakly consistent belief bases
-
- Journal:
- The Knowledge Engineering Review / Volume 40 / 2025
- Published online by Cambridge University Press:
- 03 December 2025, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Category-Theoretic Perspective on Higher-Order Approximation Fixpoint Theory
-
- Journal:
- Theory and Practice of Logic Programming , First View
- Published online by Cambridge University Press:
- 02 December 2025, pp. 1-34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WoLLIC 2023 - 29th Workshop on Logic, Language, Information and Computation
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 02 December 2025, e35
-
- Article
-
- You have access
- HTML
- Export citation
A “broken egg” of U.S. Political Beliefs: Using response-item networks (ResIN) to measure ideological polarization
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 02 December 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Proof Theory and Logic Programming
- Computation as Proof Search
-
- Published online:
- 01 December 2025
- Print publication:
- 18 December 2025
Examining the effectiveness of integrating corpus-based and AI approaches for English speaking practice
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 01 December 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TO MAKE IT WHOLE: PARTS, FUSIONS, AND LOCATIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 19 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 01 December 2025, pp. 23-40
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A socio-technical perspective on digital twins as GovTech solutions: the case of WiseTown
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 01 December 2025, e82
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RSL volume 18 issue 4 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 06 January 2026, pp. b1-b6
- Print publication:
- December 2025
-
- Article
-
- You have access
- Export citation
RSL volume 18 issue 4 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 06 January 2026, pp. f1-f4
- Print publication:
- December 2025
-
- Article
-
- You have access
- Export citation

The Mathematics of Origami
-
- Published online:
- 28 November 2025
- Print publication:
- 18 December 2025
Exploring the effects of (un)familiar environments on MALL task writing performance, EFL writing proficiency, and learner perceptions
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 28 November 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of the creative potential of design problems via novelty and usefulness
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 28 November 2025, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
