Refine search
Actions for selected content:
49426 results in Computer Science
References
-
- Book:
- The Mathematics of Origami
- Published online:
- 28 November 2025
- Print publication:
- 18 December 2025, pp 186-189
-
- Chapter
- Export citation
8 - Curved-Crease Origami
-
- Book:
- The Mathematics of Origami
- Published online:
- 28 November 2025
- Print publication:
- 18 December 2025, pp 121-140
-
- Chapter
- Export citation
9 - Higher-Order Quantification
-
- Book:
- Proof Theory and Logic Programming
- Published online:
- 01 December 2025
- Print publication:
- 18 December 2025, pp 187-215
-
- Chapter
- Export citation
Part II - Regression
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 111-208
-
- Chapter
- Export citation
8 - Gaussian Process Regression and Classification
- from Part II - Regression
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 183-208
-
- Chapter
- Export citation
Dedication
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp v-vi
-
- Chapter
- Export citation
Part III - Feature Extraction
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 209-290
-
- Chapter
- Export citation
2 - Stamp Folding
-
- Book:
- The Mathematics of Origami
- Published online:
- 28 November 2025
- Print publication:
- 18 December 2025, pp 6-18
-
- Chapter
- Export citation
20 - Introduction to Reinforcement Learning
- from Part VI - Reinforcement Learning
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 471-520
-
- Chapter
- Export citation
17 - Biologically Inspired Networks
- from Part V - Neural Networks
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 405-415
-
- Chapter
- Export citation

Linear Cryptanalysis
-
- Published online:
- 17 December 2025
- Print publication:
- 20 November 2025
Displayed type theory and semi-simplicial types
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 17 December 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce Displayed Type Theory (dTT), a multi-modal homotopy type theory with discrete and simplicial modes. In the intended semantics, the discrete mode is interpreted by a model for an arbitrary
 $\infty$-topos, while the simplicial mode is interpreted by Reedy fibrant augmented semi-simplicial diagrams in that model. This simplicial structure is represented inside the theory by a primitive notion of display or dependency, guarded by modalities, yielding a partially-internal form of unary parametricity. Using the display primitive, we then give a coinductive definition, at the simplicial mode, of a type
$\infty$-topos, while the simplicial mode is interpreted by Reedy fibrant augmented semi-simplicial diagrams in that model. This simplicial structure is represented inside the theory by a primitive notion of display or dependency, guarded by modalities, yielding a partially-internal form of unary parametricity. Using the display primitive, we then give a coinductive definition, at the simplicial mode, of a type  of semi-simplicial types. Roughly speaking, a semi-simplicial type
of semi-simplicial types. Roughly speaking, a semi-simplicial type  consists of a type
consists of a type  together with, for each
together with, for each  , a displayed semi-simplicial type over
, a displayed semi-simplicial type over  . This mimics how simplices can be generated geometrically through repeated cones, and is made possible by the display primitive at the simplicial mode. The discrete part of
. This mimics how simplices can be generated geometrically through repeated cones, and is made possible by the display primitive at the simplicial mode. The discrete part of  then yields the usual infinite indexed definition of semi-simplicial types, both semantically and syntactically. Thus, dTT enables working with semi-simplicial types in full semantic generality.
then yields the usual infinite indexed definition of semi-simplicial types, both semantically and syntactically. Thus, dTT enables working with semi-simplicial types in full semantic generality.

 of semi-simplicial types. Roughly speaking, a semi-simplicial type
of semi-simplicial types. Roughly speaking, a semi-simplicial type  consists of a type
consists of a type  together with, for each
together with, for each  , a displayed semi-simplicial type over
, a displayed semi-simplicial type over  . This mimics how simplices can be generated geometrically through repeated cones, and is made possible by the display primitive at the simplicial mode. The discrete part of
. This mimics how simplices can be generated geometrically through repeated cones, and is made possible by the display primitive at the simplicial mode. The discrete part of  then yields the usual infinite indexed definition of semi-simplicial types, both semantically and syntactically. Thus, dTT enables working with semi-simplicial types in full semantic generality.
then yields the usual infinite indexed definition of semi-simplicial types, both semantically and syntactically. Thus, dTT enables working with semi-simplicial types in full semantic generality.Uncertainty quantification for deep learning
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 17 December 2025, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hypergraphs with uniform Turán density equal to 8/27
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 17 December 2025, pp. 280-289
-
- Article
- Export citation
-
In the 1980s, Erdős and Sós initiated the study of Turán problems with a uniformity condition on the distribution of edges: the uniform Turán density of a hypergraph
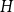 $H$ is the infimum over all
$H$ is the infimum over all 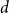 $d$ for which any sufficiently large hypergraph with the property that all its linear-size subhypergraphs have density at least
$d$ for which any sufficiently large hypergraph with the property that all its linear-size subhypergraphs have density at least 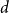 $d$ contains
$d$ contains 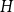 $H$. In particular, they asked to determine the uniform Turán densities of
$H$. In particular, they asked to determine the uniform Turán densities of 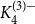 $K_4^{(3)-}$ and
$K_4^{(3)-}$ and 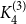 $K_4^{(3)}$. After more than 30 years, the former was solved in [Israel J. Math. 211 (2016), 349 – 366] and [J. Eur. Math. Soc. 20 (2018), 1139 – 1159], while the latter still remains open. Till today, there are known constructions of
$K_4^{(3)}$. After more than 30 years, the former was solved in [Israel J. Math. 211 (2016), 349 – 366] and [J. Eur. Math. Soc. 20 (2018), 1139 – 1159], while the latter still remains open. Till today, there are known constructions of 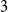 $3$-uniform hypergraphs with uniform Turán density equal to
$3$-uniform hypergraphs with uniform Turán density equal to 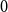 $0$,
$0$, 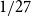 $1/27$,
$1/27$, 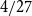 $4/27$, and
$4/27$, and 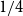 $1/4$ only. We extend this list by a fifth value: we prove an easy to verify sufficient condition for the uniform Turán density to be equal to
$1/4$ only. We extend this list by a fifth value: we prove an easy to verify sufficient condition for the uniform Turán density to be equal to 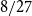 $8/27$ and identify hypergraphs satisfying this condition.
$8/27$ and identify hypergraphs satisfying this condition.
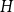
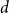
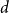
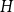
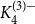
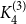
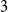
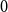
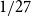
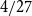
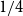
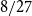
The impact of institutions on blockchain adoption in the European public sector: a qualitative comparative analysis
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 December 2025, e84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unsettling Memories: Practice, Platforms, and Possibilities. Closing Reflections on the Communicating Memory Matters Collection
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 15 December 2025, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluation of the relationship between studies of design research and design process in the field of architecture: a systematic review
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 15 December 2025, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Human–Computer Interaction and U.S. Law
-
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026
Trustworthy, responsible and ethical artificial intelligence in manufacturing and supply chains: synthesis and emerging research questions
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 12 December 2025, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Network games with local correlation and clustering
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 12 December 2025, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
