Refine search
Actions for selected content:
49426 results in Computer Science
Using Gaussian processes for spatial prediction of PM2.5 concentration based on calibrated data from distributed low-cost sensor networks
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 12 December 2025, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Air pollution is a major environmental and public health risk globally leading to millions of premature deaths annually and negative economic effects. One of the key challenges in managing air quality is the availability of actionable spatial air quality data. The sparse networks or absence of air quality monitoring stations in many places means that there are limited data and information on air pollution in places without coverage. The spatial prediction of air quality can contribute to increasing data access for locations without air quality monitoring, ultimately improving awareness of the risk of air pollution exposure for vulnerable people. In this study, we investigated the air quality prediction task in two cities in Uganda (i.e., Jinja and Kampala), with unique geographic and economic contexts. Primarily, we used Gaussian processes to predict the PM
 $ {}_{2.5} $ levels in the two cities, selected because of their relative importance in the country and their varying characteristics. We achieved promising results with an average root-mean-square error (RMSE) of 18.32 μg/m3 and 16.88 μg/m3 in Kampala and Jinja, respectively. These results provide valuable insights into the air quality profiles of two urban sub-Saharan cities with different demographics, which can in turn aid in decision-making for targeted actions at different levels.
$ {}_{2.5} $ levels in the two cities, selected because of their relative importance in the country and their varying characteristics. We achieved promising results with an average root-mean-square error (RMSE) of 18.32 μg/m3 and 16.88 μg/m3 in Kampala and Jinja, respectively. These results provide valuable insights into the air quality profiles of two urban sub-Saharan cities with different demographics, which can in turn aid in decision-making for targeted actions at different levels.

Language models for the analysis of and interaction with climate change documents
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 12 December 2025, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A hybrid optimization algorithm combining A* and the dynamic window approach for automated guided vehicle control in static and dynamic environments
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 12 December 2025, pp. 1-63
-
- Article
- Export citation
Digital oratory: a multi-data analysis of L2 speakers’ public speaking anxiety and nonverbal speech performance in digital contexts
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 12 December 2025, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards equitable governance of human genomic data sharing: guided by genomic contextualism
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Temporal configuration model: Statistical inference and spreading processes
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robustness with adaptation. Ownership networks of multinationals through COVID-19
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Experimental iterative learning control of a quadrotor in flight: A derivation of the state-dependent Riccati equation method
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HIF: The hypergraph interchange format for higher-order networks
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 11 December 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hypergraphs without complete partite subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 11 December 2025, pp. 1-4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fix integers
 $r \ge 2$ and
$r \ge 2$ and  $1\le s_1\le \cdots \le s_{r-1}\le t$ and set
$1\le s_1\le \cdots \le s_{r-1}\le t$ and set  $s=\prod _{i=1}^{r-1}s_i$. Let
$s=\prod _{i=1}^{r-1}s_i$. Let  $K=K(s_1, \ldots , s_{r-1}, t)$ denote the complete
$K=K(s_1, \ldots , s_{r-1}, t)$ denote the complete  $r$-partite
$r$-partite  $r$-uniform hypergraph with parts of size
$r$-uniform hypergraph with parts of size  $s_1, \ldots , s_{r-1}, t$. We prove that the Zarankiewicz number
$s_1, \ldots , s_{r-1}, t$. We prove that the Zarankiewicz number  $z(n, K)= n^{r-1/s-o(1)}$ provided
$z(n, K)= n^{r-1/s-o(1)}$ provided  $t\gt 3^{s+o(s)}$. Previously this was known only for
$t\gt 3^{s+o(s)}$. Previously this was known only for  $t \gt ((r-1)(s-1))!$ due to Pohoata and Zakharov. Our novel approach, which uses Behrend’s construction of sets with no 3-term arithmetic progression, also applies for small values of
$t \gt ((r-1)(s-1))!$ due to Pohoata and Zakharov. Our novel approach, which uses Behrend’s construction of sets with no 3-term arithmetic progression, also applies for small values of  $s_i$, for example, it gives
$s_i$, for example, it gives  $z(n, K(2,2,7))=n^{11/4-o(1)}$ where the exponent 11/4 is optimal, whereas previously this was only known with 7 replaced by 721.
$z(n, K(2,2,7))=n^{11/4-o(1)}$ where the exponent 11/4 is optimal, whereas previously this was only known with 7 replaced by 721.












Sidorenko’s conjecture for subdivisions and theta substitutions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 269-279
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The famous Sidorenko’s conjecture asserts that for every bipartite graph
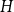 $H$, the number of homomorphisms from
$H$, the number of homomorphisms from 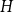 $H$ to a graph
$H$ to a graph 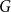 $G$ with given edge density is minimised when
$G$ with given edge density is minimised when 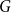 $G$ is pseudorandom. We prove that for any graph
$G$ is pseudorandom. We prove that for any graph 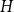 $H$, a graph obtained from replacing edges of
$H$, a graph obtained from replacing edges of 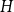 $H$ by generalised theta graphs consisting of even paths satisfies Sidorenko’s conjecture, provided a certain divisibility condition on the number of paths. To achieve this, we prove unconditionally that bipartite graphs obtained from replacing each edge of a complete graph with a generalised theta graph satisfy Sidorenko’s conjecture, which extends a result of Conlon, Kim, Lee and Lee [J. Lond. Math. Soc., 2018].
$H$ by generalised theta graphs consisting of even paths satisfies Sidorenko’s conjecture, provided a certain divisibility condition on the number of paths. To achieve this, we prove unconditionally that bipartite graphs obtained from replacing each edge of a complete graph with a generalised theta graph satisfy Sidorenko’s conjecture, which extends a result of Conlon, Kim, Lee and Lee [J. Lond. Math. Soc., 2018].
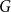
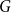
Virtual design context: a VR-driven approach to contextual architectural design; a preliminary taxonomy for developing immersive contexts
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 10 December 2025, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing design concept diversity: multi-persona prompting strategies for large language models
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 10 December 2025, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Kock–Mikkelsen factorisation
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 09 December 2025, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On stability of rainbow matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 09 December 2025, pp. 255-268
-
- Article
- Export citation
-
We show that for any integer
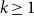 $k\ge 1$ there exists an integer
$k\ge 1$ there exists an integer 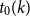 $t_0(k)$ such that, for integers
$t_0(k)$ such that, for integers 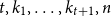 $t, k_1, \ldots , k_{t+1}, n$ with
$t, k_1, \ldots , k_{t+1}, n$ with 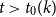 $t\gt t_0(k)$,
$t\gt t_0(k)$, 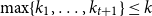 $\max \{k_1, \ldots , k_{t+1}\}\le k$, and
$\max \{k_1, \ldots , k_{t+1}\}\le k$, and 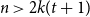 $n \gt 2k(t+1)$, the following holds: If
$n \gt 2k(t+1)$, the following holds: If 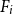 $F_i$ is a
$F_i$ is a 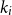 $k_i$-uniform hypergraph with vertex set
$k_i$-uniform hypergraph with vertex set 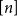 $[n]$ and more than
$[n]$ and more than 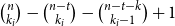 $ \binom{n}{k_i}-\binom{n-t}{k_i} - \binom{n-t-k}{k_i-1} + 1$ edges for all
$ \binom{n}{k_i}-\binom{n-t}{k_i} - \binom{n-t-k}{k_i-1} + 1$ edges for all 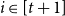 $i \in [t+1]$, then either
$i \in [t+1]$, then either 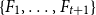 $\{F_1,\ldots , F_{t+1}\}$ admits a rainbow matching of size
$\{F_1,\ldots , F_{t+1}\}$ admits a rainbow matching of size 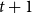 $t+1$ or there exists
$t+1$ or there exists 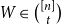 $W\in \binom{[n]}{t}$ such that
$W\in \binom{[n]}{t}$ such that 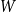 $W$ intersects
$W$ intersects 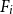 $F_i$ for all
$F_i$ for all 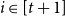 $i\in [t+1]$. This may be viewed as a rainbow non-uniform extension of the classical Hilton-Milner theorem. We also show that the same holds for every
$i\in [t+1]$. This may be viewed as a rainbow non-uniform extension of the classical Hilton-Milner theorem. We also show that the same holds for every  $t$ and
$t$ and 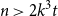 $n \gt 2k^3t$, generalizing a recent stability result of Frankl and Kupavskii on matchings to rainbow matchings.
$n \gt 2k^3t$, generalizing a recent stability result of Frankl and Kupavskii on matchings to rainbow matchings.
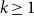
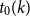
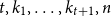
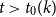
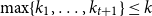
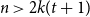
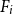
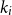
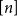
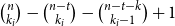
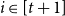
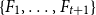
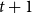
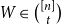
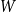
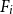
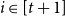

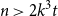
Controlling unfolding in type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 09 December 2025, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present a new way to control the unfolding of definitions in dependent type theory. Traditionally, proof assistants require users to fix whether each definition will or will not be unfolded in the remainder of a development; unfolding definitions is often necessary in order to reason about them, but an excess of unfolding can result in brittle proofs and intractably large proof goals. In our system, definitions are by default not unfolded, but users can selectively unfold them in a local manner. We justify our mechanism by means of elaboration to a core theory with extension types – a connective first introduced in the context of homotopy type theory – and by establishing a normalization theorem for our core calculus. We have implemented controlled unfolding in the
 proof assistant, inspiring an independent implementation in Agda.
proof assistant, inspiring an independent implementation in Agda.
 proof assistant, inspiring an independent implementation in Agda.
proof assistant, inspiring an independent implementation in Agda.Characterizations of
 $\omega$-Rudin spaces via sequence convergence
$\omega$-Rudin spaces via sequence convergence
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 09 December 2025, e37
-
- Article
- Export citation
-
The author’s primary goal in this paper is to characterize
 $\omega$-Rudin sets and
$\omega$-Rudin sets and  $\omega$-Rudin spaces via sequence convergence and give some important applications of such characterizations. For an irreducible closed set
$\omega$-Rudin spaces via sequence convergence and give some important applications of such characterizations. For an irreducible closed set  $A$ of a
$A$ of a  $T_0$-space
$T_0$-space  $X$, we prove that the following four conditions are equivalent: (1)
$X$, we prove that the following four conditions are equivalent: (1)  $A$ is an
$A$ is an  $\omega$-Rudin set; (2) there is
$\omega$-Rudin set; (2) there is  $\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence
$\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence  $(a_n)_{n\in \mathbb{N}}$ simultaneously converges to all points of
$(a_n)_{n\in \mathbb{N}}$ simultaneously converges to all points of  $A$; (3) there is
$A$; (3) there is  $\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence
$\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence  $(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to
$(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to  $A$ in the Hoare power space of
$A$ in the Hoare power space of  $X$; (4) there is
$X$; (4) there is  $\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence
$\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence  $(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to
$(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to  $A$ in the sobrification of
$A$ in the sobrification of  $X$. Based on these characterizations, we obtain some characterizations of
$X$. Based on these characterizations, we obtain some characterizations of  $\omega$-Rudin spaces and sober spaces. In particular, we show that for a complete lattice
$\omega$-Rudin spaces and sober spaces. In particular, we show that for a complete lattice  $L$, its Scott space
$L$, its Scott space  $\Sigma L$ is sober iff for any nonempty Scott irreducible closed set
$\Sigma L$ is sober iff for any nonempty Scott irreducible closed set  $A$ of
$A$ of  $L$, there is
$L$, there is  $\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence
$\{a_n : n\in \mathbb{N}\}\subseteq A$ such that the sequence  $(a_n)_{n\in \mathbb{N}}$ simultaneously Scott converges to all points of
$(a_n)_{n\in \mathbb{N}}$ simultaneously Scott converges to all points of  $A$ or, equivalently, the sequence
$A$ or, equivalently, the sequence  $(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to
$(\overline {\{a_n\}})_{n\in \mathbb{N}}$ converges to  $A$ in the sobrification of
$A$ in the sobrification of  $\Sigma L$. Several related examples are presented. We also investigate some basic properties of
$\Sigma L$. Several related examples are presented. We also investigate some basic properties of  $\omega$-Rudin spaces. It is proved that the property of being an
$\omega$-Rudin spaces. It is proved that the property of being an  $\omega$-Rudin space is retractive, productive, and closed-hereditary. We give two examples to show that it is not saturated-hereditary and the category
$\omega$-Rudin space is retractive, productive, and closed-hereditary. We give two examples to show that it is not saturated-hereditary and the category  $\boldsymbol{\omega }$-
$\boldsymbol{\omega }$- $\mathbf{Rud}$ of
$\mathbf{Rud}$ of  $\omega$-Rudin spaces does not have equalizers, and hence,
$\omega$-Rudin spaces does not have equalizers, and hence,  $\boldsymbol{\omega }$-
$\boldsymbol{\omega }$- $\mathbf{Rud}$ is not reflective in the category
$\mathbf{Rud}$ is not reflective in the category  $\mathbf{Top}_{0}$ of all
$\mathbf{Top}_{0}$ of all  $T_0$-spaces. Finally, we discuss the Smyth power spaces of
$T_0$-spaces. Finally, we discuss the Smyth power spaces of  $\omega$-Rudin spaces. It is shown that if the Smyth power space of a
$\omega$-Rudin spaces. It is shown that if the Smyth power space of a  $T_0$-space
$T_0$-space  $X$ is an
$X$ is an  $\omega$-Rudin space, then
$\omega$-Rudin space, then  $X$ is an
$X$ is an  $\omega$-Rudin space. The question naturally arises whether the Smyth power space of an
$\omega$-Rudin space. The question naturally arises whether the Smyth power space of an  $\omega$-Rudin space is still an
$\omega$-Rudin space is still an  $\omega$-Rudin space.
$\omega$-Rudin space.















































Automata and coalgebras in categories of species
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 09 December 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study generalised automata (in the sense of Adámek and Trnková) in Joyal’s category of (set-valued) combinatorial species, and as an important preliminary step, we study coalgebras for its derivative endofunctor
 $\partial$ and for the ‘Euler homogeneity operator’
$\partial$ and for the ‘Euler homogeneity operator’  $L\circ \partial$ arising from the adjunction
$L\circ \partial$ arising from the adjunction  $L\dashv \partial \dashv R$. The theory is connected with, and in fact provides relatively nontrivial examples of, differential 2-rigs, a notion recently introduced by the author putting combinatorial species on the same relation a generic (differential) semiring
$L\dashv \partial \dashv R$. The theory is connected with, and in fact provides relatively nontrivial examples of, differential 2-rigs, a notion recently introduced by the author putting combinatorial species on the same relation a generic (differential) semiring  $(R,d)$ has with the (differential) semiring
$(R,d)$ has with the (differential) semiring  $\mathbb{N}[\![ X]\!]$ of power series with natural coefficients. The desire to study categories of ‘state machines’ valued in an ambient monoidal category
$\mathbb{N}[\![ X]\!]$ of power series with natural coefficients. The desire to study categories of ‘state machines’ valued in an ambient monoidal category  $(\mathcal{K},\otimes )$ gives a pretext to further develop the abstract theory of differential 2-rigs, proving lifting theorems of a differential 2-rig structure from
$(\mathcal{K},\otimes )$ gives a pretext to further develop the abstract theory of differential 2-rigs, proving lifting theorems of a differential 2-rig structure from  $(\mathcal{R},\partial )$ to the category of
$(\mathcal{R},\partial )$ to the category of  $\partial$-algebras on objects of
$\partial$-algebras on objects of  $\mathcal{R}$ and to categories of Mealy automata valued in
$\mathcal{R}$ and to categories of Mealy automata valued in  $(\mathcal{R},\otimes )$, as well as various constructions inspired by differential algebra such as jet spaces and modules of differential operators. These theorems adapt to various ‘species-like’ categories such as coloured species,
$(\mathcal{R},\otimes )$, as well as various constructions inspired by differential algebra such as jet spaces and modules of differential operators. These theorems adapt to various ‘species-like’ categories such as coloured species,  $k$-vector species (both used in operad theory), linear species (introduced by Leroux to study combinatorial differential equations), Möbius species and others.
$k$-vector species (both used in operad theory), linear species (introduced by Leroux to study combinatorial differential equations), Möbius species and others.











