Refine search
Actions for selected content:
49448 results in Computer Science
Exploring the effects of (un)familiar environments on MALL task writing performance, EFL writing proficiency, and learner perceptions
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 28 November 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of the creative potential of design problems via novelty and usefulness
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 28 November 2025, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing taxpayer registration with inter-institutional data sharing—evidence from Uganda
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 28 November 2025, e81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Making global sensitivity analysis feasible using neural network surrogates
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 28 November 2025, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond the classification theorem of Cameron, Goethals, Seidel, and Shult
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 28 November 2025, pp. 207-229
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In 1976, Cameron, Goethals, Seidel, and Shult classified all the graphs whose smallest eigenvalue is at least
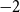 $-2$ by relating such graphs to root systems that appear in the classification of semisimple Lie algebras. In this paper, extending their beautiful theorem, we give a complete classification of all connected graphs whose smallest eigenvalue lies in
$-2$ by relating such graphs to root systems that appear in the classification of semisimple Lie algebras. In this paper, extending their beautiful theorem, we give a complete classification of all connected graphs whose smallest eigenvalue lies in 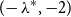 $(\! -\lambda ^*, -2)$, where
$(\! -\lambda ^*, -2)$, where 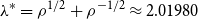 $\lambda ^* = ho ^{1/2} + ho ^{-1/2} \approx 2.01980$, and
$\lambda ^* = ho ^{1/2} + ho ^{-1/2} \approx 2.01980$, and 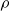 $ho$ is the unique real root of
$ho$ is the unique real root of 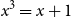 $x^3 = x + 1$. Our result is the first classification of infinitely many connected graphs with their smallest eigenvalue in
$x^3 = x + 1$. Our result is the first classification of infinitely many connected graphs with their smallest eigenvalue in 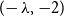 $(\! -\lambda , -2)$ for any constant
$(\! -\lambda , -2)$ for any constant 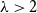 $\lambda \gt 2$.
$\lambda \gt 2$.
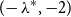
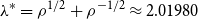
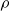
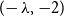
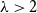
Real-time slip detection with friction-scaled vibrotactile feedback for robotic sixth-finger-assisted manipulation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The integration of extra-robotic limbs or fingers to enhance and extend motor capabilities, particularly for grasping and manipulation, remains a major challenge. In contrast to the natural human hand, which achieves highly dexterous and adaptive grasping, the performance of current extra-robotic limbs or fingers is still markedly limited. Human hands can detect the onset of slip through tactile feedback originating from tactile receptors during the grasping process, enabling precise and automatic regulation of grip force. This grip force is scaled by the coefficient of friction between the contacting surface and the fingers. The frictional information is perceived by humans depending upon the slip happening between the finger and the object. This ability to perceive friction allows humans to apply just the right amount of force needed to maintain a secure grip, adjusting based on the weight of the object and the friction of the contact surface. Enhancing this capability in extra-robotic limbs or fingers used by humans is challenging. To address this challenge, this paper introduces a novel approach to communicate frictional information to users through encoded vibrotactile cues. These cues are conveyed on the onset of incipient slip, thus allowing the users to perceive the friction and ultimately use this information to increase the force to avoid dropping the object. In a 2-alternative forced-choice protocol, participants gripped and lifted a glass under three different frictional conditions, applying a normal force of 3.5 N. After reaching this force, the glass was gradually released to induce slip. During this slipping phase, vibrations scaled according to the static coefficient of friction were presented to users, reflecting the frictional conditions. The results suggested an accuracy of
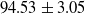 $94.53\pm 3.05$ (
$94.53\pm 3.05$ (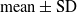 $\text{mean}\pm \text{SD}$) in perceiving frictional information upon lifting objects with varying friction. The results indicate the effectiveness of using vibrotactile feedback for sensory feedback, allowing users of extra-robotic limbs or fingers to perceive frictional information. This enables them to assess surface properties and adjust grip force according to the frictional conditions, enhancing their ability to grasp and manipulate objects more effectively.
$\text{mean}\pm \text{SD}$) in perceiving frictional information upon lifting objects with varying friction. The results indicate the effectiveness of using vibrotactile feedback for sensory feedback, allowing users of extra-robotic limbs or fingers to perceive frictional information. This enables them to assess surface properties and adjust grip force according to the frictional conditions, enhancing their ability to grasp and manipulate objects more effectively.
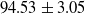
Supporting design for additive manufacturing: insights from product development practices in the aerospace industry
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 28 November 2025, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Pseudolimits for tangent categories with applications to equivariant algebraic and differential geometry
- Part of
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 27 November 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we show that if
 $\mathscr{C}$ is a category and if
$\mathscr{C}$ is a category and if  $F\colon \mathscr{C}^{\;\textrm {op}} \to \mathfrak{Cat}$ is a pseudofunctor such that for each object
$F\colon \mathscr{C}^{\;\textrm {op}} \to \mathfrak{Cat}$ is a pseudofunctor such that for each object  $X$ of
$X$ of  $\mathscr{C}$ the category
$\mathscr{C}$ the category  $F(X)$ is a tangent category and for each morphism
$F(X)$ is a tangent category and for each morphism  $f$ of
$f$ of  $\mathscr{C}$ the functor
$\mathscr{C}$ the functor  $F(\,f)$ is part of a strong tangent morphism
$F(\,f)$ is part of a strong tangent morphism  $(F(\,f),\!\,_{f}{\alpha })$ and that furthermore the natural transformations
$(F(\,f),\!\,_{f}{\alpha })$ and that furthermore the natural transformations  $\!\,_{f}{\alpha }$ vary pseudonaturally in
$\!\,_{f}{\alpha }$ vary pseudonaturally in  $\mathscr{C}^{\;\textrm {op}}$, then there is a tangent structure on the pseudolimit
$\mathscr{C}^{\;\textrm {op}}$, then there is a tangent structure on the pseudolimit  $\mathbf{PC}(F)$ which is induced by the tangent structures on the categories
$\mathbf{PC}(F)$ which is induced by the tangent structures on the categories  $F(X)$ together with how they vary through the functors
$F(X)$ together with how they vary through the functors  $F(\,f)$. We use this observation to show that the forgetful
$F(\,f)$. We use this observation to show that the forgetful  $2$-functor
$2$-functor  $\operatorname {Forget}:\mathfrak{Tan} \to \mathfrak{Cat}$ creates and preserves pseudolimits indexed by
$\operatorname {Forget}:\mathfrak{Tan} \to \mathfrak{Cat}$ creates and preserves pseudolimits indexed by  $1$-categories. As an application, this allows us to describe how equivariant descent interacts with the tangent structures on the category of smooth (real) manifolds and on various categories of (algebraic) varieties over a field.
$1$-categories. As an application, this allows us to describe how equivariant descent interacts with the tangent structures on the category of smooth (real) manifolds and on various categories of (algebraic) varieties over a field.

















Enhancing intercultural competence through self-efficacy, grit, and informal digital learning of English
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 27 November 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Objective Mackey and Tambara functors via parametrized categories
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 27 November 2025, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The first word in the title is intended in a sense suggested by Lawvere and Schanuel whereby finite sets are objective natural numbers. At the objective level, the axioms defining abstract Mackey and Tambara functors are categorically familiar. The first step was taken by Harald Lindner in 1976 when he recognized that Mackey functors, defined as pairs of functors, were equivalently single functors with domain a category of spans. In 1993, Tambara recognized that TNR-functors (that is, functors designed to have abstract trace, norm and restriction operations, and now called Tambara functors) were equivalently certain functors out of a category of polynomials. We define objective Mackey and objective Tambara functors as parametrized categories that have local finite products and satisfy some parametrized completeness and cocompleteness restriction. However, we can replace the original parametrizing base for objective Mackey functors by a bicategory of spans while the replacement for objective Tambara functors is a bicategory obtained by iterating the span construction; these iterated spans are polynomials. There is an objective Mackey functor of ordinary Mackey functors. We show that there is a distributive law relating objective Mackey functors to objective Tambara functors analogous to the distributive law relating abelian groups to commutative rings. We remark on hom enrichment matters involving the 2-category
 $\textrm{Cat}_{+}$ of categories admitting finite coproducts and functors preserving them, both as a closed base and as a skew-closed base.
$\textrm{Cat}_{+}$ of categories admitting finite coproducts and functors preserving them, both as a closed base and as a skew-closed base.

Canonization of a random circulant graph by counting walks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 26 November 2025, pp. 178-206
-
- Article
- Export citation
-
It is well known that almost all graphs are canonizable by a simple combinatorial routine known as colour refinement, also referred to as the 1-dimensional Weisfeiler–Leman algorithm. With high probability, this method assigns a unique label to each vertex of a random input graph and, hence, it is applicable only to asymmetric graphs. The strength of combinatorial refinement techniques becomes a subtle issue if the input graphs are highly symmetric. We prove that the combination of colour refinement and vertex individualization yields a canonical labelling for almost all circulant digraphs (i.e., Cayley digraphs of a cyclic group). This result provides first evidence of good average-case performance of combinatorial refinement within the class of vertex-transitive graphs. Remarkably, we do not even need the full power of the colour refinement algorithm. We show that the canonical label of a vertex
 $v$ can be obtained just by counting walks of each length from
$v$ can be obtained just by counting walks of each length from  $v$ to an individualized vertex. Our analysis also implies that almost all circulant graphs are compact in the sense of Tinhofer, that is, their polytops of fractional automorphisms are integral. Finally, we show that a canonical Cayley representation can be constructed for almost all circulant graphs by the more powerful 2-dimensional Weisfeiler–Leman algorithm.
$v$ to an individualized vertex. Our analysis also implies that almost all circulant graphs are compact in the sense of Tinhofer, that is, their polytops of fractional automorphisms are integral. Finally, we show that a canonical Cayley representation can be constructed for almost all circulant graphs by the more powerful 2-dimensional Weisfeiler–Leman algorithm.


Optimally stable plan repair
-
- Journal:
- The Knowledge Engineering Review / Volume 40 / 2025
- Published online by Cambridge University Press:
- 26 November 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Plan repair is the problem of solving a given planning problem by using a solution plan of a similar problem. This paper presents the first approach where the repair has to be done optimally, that is, we aim at finding a minimum distance plan from an input plan; we do so by introducing a number of compilation schemes that convert a classical planning problem into another where optimal plans correspond to plans with the minimum distance from an input plan. We also address the problem of finding a minimum distance plan from a set of input plans, instead of just one plan. Our experiments using a number of planners show that such a simple approach can solve many problems optimally and more effectively than replanning from scratch for a large number of cases. Also, the approach proves competitive with
 ${\mathsf{LPG}\textrm{-}\mathsf{adapt}}$, a state-of-the-art approach for the plan repair problem.
${\mathsf{LPG}\textrm{-}\mathsf{adapt}}$, a state-of-the-art approach for the plan repair problem.

From ransoms to ruin: Are extortion payments by ransomware victims insurable?
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 26 November 2025, e80
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing adaptive feedback systems for managing cognitive load in augmented reality
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 26 November 2025, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward the effective 2-topos
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 26 November 2025, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Informal digital learning of English in teachers: development and validation of a scale – CORRIGENDUM
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 25 November 2025, p. 1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stereotypes as mnemonic frames: How journalism mediates collective memory in representations of foreign groups
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 25 November 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction and uncertainty quantification of drought in North Benin
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 24 November 2025, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Drought forecasting is a critical tool for mitigating the severe impacts of water scarcity, particularly in regions like North Benin, where agriculture is a cornerstone of livelihoods. Despite the vital importance of its accurate prediction in resource management, the ability to quantify uncertainties in forecasts is a significant pain point to enable more informed and trustworthy decision-making. So, this study aims to develop an uncertainty-aware prediction model for drought forecasting in six key localities within the Alibori department—Banikoara, Gogounou, Kandi, Karimama, Malanville, and Segbana—each facing unique challenges due to drought. To achieve this, we conducted a comprehensive experiment involving six machine learning models (linear regression, ridge regression, random forest, Xgboost, LightGBM, and SVM) and four deep learning models (Conv1D, LSTM, GRU, and Conv1D-LSTM) using the Standardized Precipitation Index at a 6-month scale. To address the uncertainty quantification challenge, we employed the Ensemble Batch Prediction Interval, a conformal prediction method specifically designed for time series data. Our comparative analysis, framed within the Borda count methodology, utilized performance metrics such as R2, RMSE, MSE, and carbon footprint, as well as uncertainty quantification metrics, including empirical coverage and the width of prediction intervals. The top-performing models achieved
 $ {R}^2 $ scores of 98.29, 97.84, 97.76, 97.42, 96.61, and 97.07%, and prediction interval coverages of 0.94, 0.79, 0.93, 0.77, 0.73, and 0.93, respectively, for Banikoara, Gogounou, Malanville, Kandi, Segbana, and Karimama. The Conv1D-LSTM model stood out as the most effective, offering an optimal balance between predictive accuracy and uncertainty coverage.
$ {R}^2 $ scores of 98.29, 97.84, 97.76, 97.42, 96.61, and 97.07%, and prediction interval coverages of 0.94, 0.79, 0.93, 0.77, 0.73, and 0.93, respectively, for Banikoara, Gogounou, Malanville, Kandi, Segbana, and Karimama. The Conv1D-LSTM model stood out as the most effective, offering an optimal balance between predictive accuracy and uncertainty coverage.

