Refine search
Actions for selected content:
48462 results in Computer Science
7 - How to Test Your Program
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 68-82
-
- Chapter
- Export citation
8 - How to Make Your Program Clear
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 83-100
-
- Chapter
- Export citation
5 - How to Use the Best Tools
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 48-54
-
- Chapter
- Export citation
10 - How to Improve Your Program
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 134-155
-
- Chapter
- Export citation
3 - Regulating Algorithms
-
-
- Book:
- Algorithms and Law
- Published online:
- 04 July 2020
- Print publication:
- 23 July 2020, pp 100-135
-
- Chapter
- Export citation
9 - How to Debug Your Program
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 101-133
-
- Chapter
- Export citation
11 - How to Get Help (without Cheating)
-
- Book:
- How to Write Good Programs
- Published online:
- 10 July 2020
- Print publication:
- 23 July 2020, pp 156-169
-
- Chapter
- Export citation
5 - Robot Machines and Civil Liability
-
-
- Book:
- Algorithms and Law
- Published online:
- 04 July 2020
- Print publication:
- 23 July 2020, pp 157-173
-
- Chapter
- Export citation
ON THE INVARIANCE OF GÖDEL’S SECOND THEOREM WITH REGARD TO NUMBERINGS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 22 July 2020, pp. 51-84
- Print publication:
- March 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large triangle packings and Tuza’s conjecture in sparse random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 22 July 2020, pp. 757-779
-
- Article
- Export citation
Pseudorandom hypergraph matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 22 July 2020, pp. 868-885
-
- Article
- Export citation
COMPLEXITY OF THE INFINITARY LAMBEK CALCULUS WITH KLEENE STAR
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 July 2020, pp. 946-972
- Print publication:
- December 2021
-
- Article
- Export citation
-
We consider the Lambek calculus, or noncommutative multiplicative intuitionistic linear logic, extended with iteration, or Kleene star, axiomatised by means of an
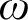 $\omega $-rule, and prove that the derivability problem in this calculus is
$\omega $-rule, and prove that the derivability problem in this calculus is 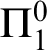 $\Pi _1^0$-hard. This solves a problem left open by Buszkowski (2007), who obtained the same complexity bound for infinitary action logic, which additionally includes additive conjunction and disjunction. As a by-product, we prove that any context-free language without the empty word can be generated by a Lambek grammar with unique type assignment, without Lambek’s nonemptiness restriction imposed (cf. Safiullin, 2007).
$\Pi _1^0$-hard. This solves a problem left open by Buszkowski (2007), who obtained the same complexity bound for infinitary action logic, which additionally includes additive conjunction and disjunction. As a by-product, we prove that any context-free language without the empty word can be generated by a Lambek grammar with unique type assignment, without Lambek’s nonemptiness restriction imposed (cf. Safiullin, 2007).
THE LOGIC OF SEQUENCE FRAMES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 21 July 2020, pp. 101-132
- Print publication:
- March 2022
-
- Article
- Export citation
TRANSMISSION OF VERIFICATION
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 21 July 2020, pp. 866-881
- Print publication:
- December 2021
-
- Article
- Export citation
THE MODAL LOGIC OF STEPWISE REMOVAL
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 21 July 2020, pp. 36-63
- Print publication:
- March 2022
-
- Article
- Export citation
UNIVERSISM AND EXTENSIONS OF V
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 21 July 2020, pp. 112-154
- Print publication:
- March 2021
-
- Article
- Export citation
EXCEPTIONAL LOGIC
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 21 July 2020, pp. 85-111
- Print publication:
- March 2021
-
- Article
- Export citation
