Refine search
Actions for selected content:
48284 results in Computer Science

The Lexicon
-
- Published online:
- 19 March 2019
- Print publication:
- 17 January 2019
-
- Textbook
- Export citation

Artificial Intelligence and Conservation
-
- Published online:
- 18 March 2019
- Print publication:
- 28 March 2019

Analyzing Network Data in Biology and Medicine
- An Interdisciplinary Textbook for Biological, Medical and Computational Scientists
-
- Published online:
- 18 March 2019
- Print publication:
- 28 March 2019
Modeling traveler experience for designing urban mobility systems
- Part of
-
- Journal:
- Design Science / Volume 5 / 2019
- Published online by Cambridge University Press:
- 18 March 2019, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Jargon of Hadoop MapReduce scheduling techniques: a scientific categorization
-
- Journal:
- The Knowledge Engineering Review / Volume 34 / 2019
- Published online by Cambridge University Press:
- 15 March 2019, e4
-
- Article
- Export citation
An asymptotic bound for the strong chromatic number
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 5 / September 2019
- Published online by Cambridge University Press:
- 15 March 2019, pp. 768-776
-
- Article
- Export citation
-
The strong chromatic number χs(G) of a graph G on n vertices is the least number r with the following property: after adding
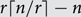 $r\lceil n/r\rceil-n$ isolated vertices to G and taking the union with any collection of spanning disjoint copies of Kr in the same vertex set, the resulting graph has a proper vertex colouring with r colours. We show that for every c > 0 and every graph G on n vertices with Δ(G) ≥ cn, χs(G) ≤ (2+o(1))Δ(G), which is asymptotically best possible.
$r\lceil n/r\rceil-n$ isolated vertices to G and taking the union with any collection of spanning disjoint copies of Kr in the same vertex set, the resulting graph has a proper vertex colouring with r colours. We show that for every c > 0 and every graph G on n vertices with Δ(G) ≥ cn, χs(G) ≤ (2+o(1))Δ(G), which is asymptotically best possible.
PES volume 33 issue 2 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 2 / April 2019
- Published online by Cambridge University Press:
- 15 March 2019, pp. b1-b2
-
- Article
-
- You have access
- Export citation
PES volume 33 issue 2 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 2 / April 2019
- Published online by Cambridge University Press:
- 15 March 2019, pp. f1-f2
-
- Article
-
- You have access
- Export citation

Adversarial Machine Learning
-
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019
DEGREE-BASED GINI INDEX FOR GRAPHS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 2 / April 2020
- Published online by Cambridge University Press:
- 14 March 2019, pp. 157-171
-
- Article
- Export citation
Investigating prototyping approaches of Ghanaian novice designers
-
- Journal:
- Design Science / Volume 5 / 2019
- Published online by Cambridge University Press:
- 14 March 2019, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decomposing Graphs into Edges and Triangles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 13 March 2019, pp. 465-472
-
- Article
- Export citation
Abelian Logic Gates
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 13 March 2019, pp. 388-422
-
- Article
- Export citation
Syllogistic logic with “Most”
-
- Journal:
- Mathematical Structures in Computer Science / Volume 29 / Issue 6 / June 2019
- Published online by Cambridge University Press:
- 13 March 2019, pp. 763-782
-
- Article
- Export citation
