Refine listing
Actions for selected content:
556 results in 90Bxx
Reliability analysis of k-out-of-n systems based on a grouping of components
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 07 August 2019, pp. 339-357
- Print publication:
- June 2019
-
- Article
- Export citation
Abelian Logic Gates
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 13 March 2019, pp. 388-422
-
- Article
- Export citation
New perspectives on the Erlang-A queue
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 22 July 2019, pp. 268-299
- Print publication:
- March 2019
-
- Article
- Export citation
The economic average cost Brownian control problem
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 22 July 2019, pp. 300-337
- Print publication:
- March 2019
-
- Article
- Export citation
Diffusion approximations for load balancing mechanisms in cloud storage systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 22 July 2019, pp. 41-86
- Print publication:
- March 2019
-
- Article
- Export citation
Relational exchangeability
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 12 July 2019, pp. 192-208
- Print publication:
- March 2019
-
- Article
- Export citation
A SPECTRUM OF SERIES–PARALLEL GRAPHS WITH MULTIPLE EDGE EVOLUTION
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 26 January 2019, pp. 487-499
-
- Article
- Export citation
-
We discuss a rich family of directed series–parallel (SP) graphs grown by the simultaneous random series or parallel development of multiple edges. The family portrays a spectrum that spans a wide range of SP graphs: from simple models, where only as few as one edge is chosen for evolution at each discrete point in time, to complex hierarchical lattice networks grown by a take-all strategy, where all the edges in the existing network are developed.
The family of SP graphs we discuss is grown from an initial seed graph with τ0 edges under an arbitrary building sequence,
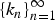 $\{k_{n}\}_{n=1}^{\infty}$, of nonnegative integers (with
$\{k_{n}\}_{n=1}^{\infty}$, of nonnegative integers (with 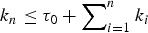 $k_n \le \tau _0 + \sum\nolimits_{i = 1}^n {k_i} $, for arbitrary τ0 ≥ 1), that specifies the number of edges subjected to evolution at time n. We study the average north polar degree and show that we can go beyond averages to strong laws. We also find the exact average number of critical edges. The asymptotics of the critical edges are facilitated under the regularity condition that
$k_n \le \tau _0 + \sum\nolimits_{i = 1}^n {k_i} $, for arbitrary τ0 ≥ 1), that specifies the number of edges subjected to evolution at time n. We study the average north polar degree and show that we can go beyond averages to strong laws. We also find the exact average number of critical edges. The asymptotics of the critical edges are facilitated under the regularity condition that 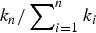 $k_n/\sum\nolimits_{i = 1}^n {k_i} $ converges to a constant (as n → ∞), a natural condition easily met by practical strategies, such as single-edge evolution and take-all choice, and much in between.
$k_n/\sum\nolimits_{i = 1}^n {k_i} $ converges to a constant (as n → ∞), a natural condition easily met by practical strategies, such as single-edge evolution and take-all choice, and much in between.
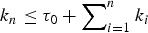
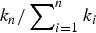
A NEW APPROACH TO SELECT THE BEST SUBSET OF PREDICTORS IN LINEAR REGRESSION MODELLING: BI-OBJECTIVE MIXED INTEGER LINEAR PROGRAMMING
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 61 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 11 January 2019, pp. 64-75
-
- Article
-
- You have access
- Export citation
-
We study the problem of choosing the best subset of
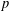 $p$ features in linear regression, given
$p$ features in linear regression, given  $n$ observations. This problem naturally contains two objective functions including minimizing the amount of bias and minimizing the number of predictors. The existing approaches transform the problem into a single-objective optimization problem. We explain the main weaknesses of existing approaches and, to overcome their drawbacks, we propose a bi-objective mixed integer linear programming approach. A computational study shows the efficacy of the proposed approach.
$n$ observations. This problem naturally contains two objective functions including minimizing the amount of bias and minimizing the number of predictors. The existing approaches transform the problem into a single-objective optimization problem. We explain the main weaknesses of existing approaches and, to overcome their drawbacks, we propose a bi-objective mixed integer linear programming approach. A computational study shows the efficacy of the proposed approach.

New nonparametric classes of distributions in terms of mean time to failure in age replacement
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 16 January 2019, pp. 1238-1248
- Print publication:
- December 2018
-
- Article
- Export citation
Occupation times of alternating renewal processes with Lévy applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 16 January 2019, pp. 1287-1308
- Print publication:
- December 2018
-
- Article
- Export citation
On optimal operational sequence of components in a warm standby system
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 16 January 2019, pp. 1014-1024
- Print publication:
- December 2018
-
- Article
- Export citation
A weak convergence approach to inventory control using a long-term average criterion
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 50 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 29 November 2018, pp. 1032-1074
- Print publication:
- December 2018
-
- Article
- Export citation
A threshold policy in a Markov-modulated production system with server vacation: the case of continuous and batch supplies
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 50 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 29 November 2018, pp. 1246-1274
- Print publication:
- December 2018
-
- Article
- Export citation
Univariate and multivariate stochastic orderings of residual lifetimes of live components in sequential (𝑛-𝑟+ 1)-out-of-𝑛 systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 16 November 2018, pp. 834-844
- Print publication:
- September 2018
-
- Article
- Export citation
Compound Poisson approximation of subgraph counts in stochastic block models with multiple edges
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 50 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 16 November 2018, pp. 759-782
- Print publication:
- September 2018
-
- Article
- Export citation
Speeding up non-Markovian first-passage percolation with a few extra edges
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 50 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 16 November 2018, pp. 858-886
- Print publication:
- September 2018
-
- Article
- Export citation
Optimal routeing in two-queue polling systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 16 November 2018, pp. 944-967
- Print publication:
- September 2018
-
- Article
- Export citation
Reliability modeling of coherent systems with shared components based on sequential order statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 16 November 2018, pp. 845-861
- Print publication:
- September 2018
-
- Article
- Export citation
NETWORKS OF INTERACTING STOCHASTIC FLUID MODELS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 30 August 2018, pp. 516-517
- Print publication:
- December 2018
-
- Article
-
- You have access
- Export citation
REACTIVE OPERATING THEATRE SCHEDULING
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 15 August 2018, pp. 520-521
- Print publication:
- December 2018
-
- Article
-
- You have access
- Export citation
