Refine search
Actions for selected content:
53197 results in Statistics and Probability
Plasma glucose levels and diabetes are independent predictors for mortality in patients with COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 16 May 2022, e106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Network analysis of England's single parent household COVID-19 control policy impact: a proof-of-concept study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 16 May 2022, e104
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exact calculation of corrosion rates by the weight-loss method
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 16 May 2022, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiphase flow applications of nonintrusive reduced-order models with Gaussian process emulation
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 16 May 2022, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hospital capacity influencing factors at COVID-19 pandemic in the United States
-
- Journal:
- Experimental Results / Accepted manuscript
- Published online by Cambridge University Press:
- 16 May 2022, pp. 1-11
-
- Article
-
- You have access
- Open access
- Export citation
The diameter of the uniform spanning tree of dense graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 13 May 2022, pp. 1010-1030
-
- Article
- Export citation
-
We show that the diameter of a uniformly drawn spanning tree of a simple connected graph on n vertices with minimal degree linear in n is typically of order
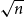 $\sqrt{n}$. A byproduct of our proof, which is of independent interest, is that on such graphs the Cheeger constant and the spectral gap are comparable.
$\sqrt{n}$. A byproduct of our proof, which is of independent interest, is that on such graphs the Cheeger constant and the spectral gap are comparable.
Workplace exposures associated with COVID-19: evidence from a case-control study with multiple sampling periods in England, August–October 2020
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 May 2022, e99
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
10 - Poisson Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 212-232
-
- Chapter
- Export citation
Assessing the role of imported cases on the establishment of SARS-CoV-2 Delta variant of concern in Bolton, UK
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 May 2022, e100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acknowledgments
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp xv-xvi
-
- Chapter
- Export citation
4 - Assessing the Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 84-100
-
- Chapter
- Export citation
2 - Principles of Statistics
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 21-63
-
- Chapter
- Export citation
Appendix Statistical Distributions
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 263-265
-
- Chapter
- Export citation
12 - Proportional Hazards Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 245-255
-
- Chapter
- Export citation
13 - Review of Methods
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 256-262
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 1-20
-
- Chapter
- Export citation
Index
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 274-278
-
- Chapter
- Export citation
References
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 272-273
-
- Chapter
- Export citation
The Importance of Biodiversity Risks: Biodiversity & Natural Capital Working Party (discussion)
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 12 May 2022, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Diagnostics for Logistic Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 195-211
-
- Chapter
- Export citation
