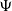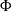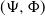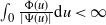Refine search
Actions for selected content:
53197 results in Statistics and Probability
Commonly Used Notation
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 238-239
-
- Chapter
- Export citation
5 - Additive Processes
- from Part II - Emergence
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 107-126
-
- Chapter
- Export citation
Index
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 249-250
-
- Chapter
- Export citation
3 - Catastrophes, Conspiracies, and Subexponential Distributions
- from Part I - Properties
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 56-84
-
- Chapter
- Export citation
Incidence and severity of SARS-CoV-2 infection in former Q fever patients as compared to the Dutch population, 2020–2021
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 08 June 2022, e116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Colouring graphs with forbidden bipartite subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 08 June 2022, pp. 45-67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A conjecture of Alon, Krivelevich and Sudakov states that, for any graph
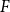 $F$, there is a constant
$F$, there is a constant 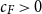 $c_F \gt 0$ such that if
$c_F \gt 0$ such that if 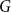 $G$ is an
$G$ is an 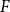 $F$-free graph of maximum degree
$F$-free graph of maximum degree 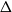 $\Delta$, then
$\Delta$, then 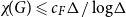 $\chi\!(G) \leqslant c_F \Delta/ \log\!\Delta$. Alon, Krivelevich and Sudakov verified this conjecture for a class of graphs
$\chi\!(G) \leqslant c_F \Delta/ \log\!\Delta$. Alon, Krivelevich and Sudakov verified this conjecture for a class of graphs 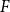 $F$ that includes all bipartite graphs. Moreover, it follows from recent work by Davies, Kang, Pirot and Sereni that if
$F$ that includes all bipartite graphs. Moreover, it follows from recent work by Davies, Kang, Pirot and Sereni that if 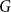 $G$ is
$G$ is 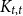 $K_{t,t}$-free, then
$K_{t,t}$-free, then 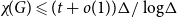 $\chi\!(G) \leqslant (t + o(1)) \Delta/ \log\!\Delta$ as
$\chi\!(G) \leqslant (t + o(1)) \Delta/ \log\!\Delta$ as 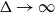 $\Delta \to \infty$. We improve this bound to
$\Delta \to \infty$. We improve this bound to 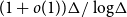 $(1+o(1)) \Delta/\log\!\Delta$, making the constant factor independent of
$(1+o(1)) \Delta/\log\!\Delta$, making the constant factor independent of 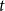 $t$. We further extend our result to the DP-colouring setting (also known as correspondence colouring), introduced by Dvořák and Postle.
$t$. We further extend our result to the DP-colouring setting (also known as correspondence colouring), introduced by Dvořák and Postle.
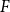
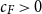
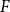
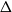
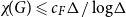
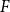
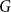
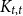
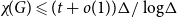
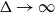
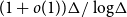
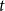
Structural health monitoring of 52-meter wind turbine blade: Detection of damage propagation during fatigue testing
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 07 June 2022, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sandwiching biregular random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 06 June 2022, pp. 1-44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
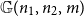 ${\mathbb{G}(n_1,n_2,m)}$ be a uniformly random m-edge subgraph of the complete bipartite graph
${\mathbb{G}(n_1,n_2,m)}$ be a uniformly random m-edge subgraph of the complete bipartite graph 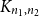 ${K_{n_1,n_2}}$ with bipartition
${K_{n_1,n_2}}$ with bipartition 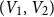 $(V_1, V_2)$, where
$(V_1, V_2)$, where 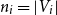 $n_i = |V_i|$,
$n_i = |V_i|$, 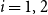 $i=1,2$. Given a real number
$i=1,2$. Given a real number 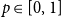 $p \in [0,1]$ such that
$p \in [0,1]$ such that 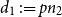 $d_1 \,{:\!=}\, pn_2$ and
$d_1 \,{:\!=}\, pn_2$ and 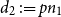 $d_2 \,{:\!=}\, pn_1$ are integers, let
$d_2 \,{:\!=}\, pn_1$ are integers, let 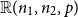 $\mathbb{R}(n_1,n_2,p)$ be a random subgraph of
$\mathbb{R}(n_1,n_2,p)$ be a random subgraph of 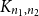 ${K_{n_1,n_2}}$ with every vertex
${K_{n_1,n_2}}$ with every vertex 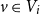 $v \in V_i$ of degree
$v \in V_i$ of degree 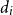 $d_i$,
$d_i$, 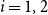 $i = 1, 2$. In this paper we determine sufficient conditions on
$i = 1, 2$. In this paper we determine sufficient conditions on 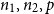 $n_1,n_2,p$ and m under which one can embed
$n_1,n_2,p$ and m under which one can embed 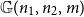 ${\mathbb{G}(n_1,n_2,m)}$ into
${\mathbb{G}(n_1,n_2,m)}$ into 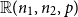 $\mathbb{R}(n_1,n_2,p)$ and vice versa with probability tending to 1. In particular, in the balanced case
$\mathbb{R}(n_1,n_2,p)$ and vice versa with probability tending to 1. In particular, in the balanced case 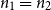 $n_1=n_2$, we show that if
$n_1=n_2$, we show that if 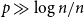 $p\gg\log n/n$ and
$p\gg\log n/n$ and 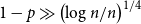 $1 - p \gg \left(\log n/n \right)^{1/4}$, then for some
$1 - p \gg \left(\log n/n \right)^{1/4}$, then for some 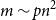 $m\sim pn^2$, asymptotically almost surely one can embed
$m\sim pn^2$, asymptotically almost surely one can embed 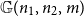 ${\mathbb{G}(n_1,n_2,m)}$ into
${\mathbb{G}(n_1,n_2,m)}$ into 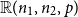 $\mathbb{R}(n_1,n_2,p)$, while for
$\mathbb{R}(n_1,n_2,p)$, while for 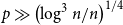 $p\gg\left(\log^{3} n/n\right)^{1/4}$ and
$p\gg\left(\log^{3} n/n\right)^{1/4}$ and 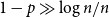 $1-p\gg\log n/n$ the opposite embedding holds. As an extension, we confirm the Kim–Vu Sandwich Conjecture for degrees growing faster than
$1-p\gg\log n/n$ the opposite embedding holds. As an extension, we confirm the Kim–Vu Sandwich Conjecture for degrees growing faster than 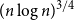 $(n \log n)^{3/4}$.
$(n \log n)^{3/4}$.
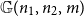
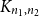
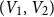
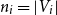
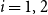
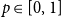
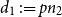
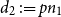
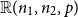
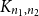
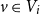
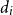
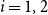
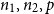
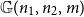
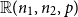
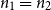
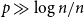
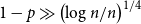
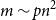
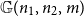
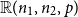
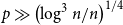
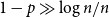
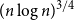
Improved bounds for the solutions of renewal equations
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 06 June 2022, pp. 740-777
-
- Article
- Export citation
Gerber-Shiu analysis in the compound Poisson model with constant inter-observation times
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 06 June 2022, pp. 324-356
-
- Article
- Export citation
Guiding principles to maintain public trust in the use of mobile operator data for policy purposes – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 06 June 2022, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HOW LARGE IS THE JUMP DISCONTINUITY IN THE DIFFUSION COEFFICIENT OF A TIME-HOMOGENEOUS DIFFUSION?
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 03 June 2022, pp. 848-880
-
- Article
- Export citation
-
We consider high-frequency observations from a one-dimensional time-homogeneous diffusion process Y. We assume that the diffusion coefficient
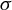 $\sigma $ is continuously differentiable in y, but with a jump discontinuity at some level y, say
$\sigma $ is continuously differentiable in y, but with a jump discontinuity at some level y, say 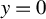 $y=0$. We first study sign-constrained kernel estimators of functions of the left and right limits of
$y=0$. We first study sign-constrained kernel estimators of functions of the left and right limits of 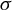 $\sigma $ at
$\sigma $ at 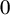 $0$. These functions intricately depend on both limits. We propose a method to extricate these functions by searching for bandwidths where the kernel estimators are stable by iteration. We finally provide an estimator of the discontinuity jump size. We prove its convergence in probability and discuss its rate of convergence. A Monte Carlo study shows the finite sample properties of this estimator.
$0$. These functions intricately depend on both limits. We propose a method to extricate these functions by searching for bandwidths where the kernel estimators are stable by iteration. We finally provide an estimator of the discontinuity jump size. We prove its convergence in probability and discuss its rate of convergence. A Monte Carlo study shows the finite sample properties of this estimator.
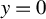
Guidance for Materials 4.0 to interact with a digital twin
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 02 June 2022, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The shape of a seed bank tree
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 June 2022, pp. 631-651
- Print publication:
- September 2022
-
- Article
- Export citation

Probabilistic Numerics
- Computation as Machine Learning
-
- Published online:
- 01 June 2022
- Print publication:
- 30 June 2022
APR volume 54 issue 2 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 06 June 2022, pp. b1-b2
- Print publication:
- June 2022
-
- Article
-
- You have access
- Export citation
APR volume 54 issue 2 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 06 June 2022, pp. f1-f2
- Print publication:
- June 2022
-
- Article
-
- You have access
- Export citation
A Dynamic Taylor’s law
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 24 June 2022, pp. 584-607
- Print publication:
- June 2022
-
- Article
- Export citation
On equal-input and monotone Markov matrices
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 06 June 2022, pp. 460-492
- Print publication:
- June 2022
-
- Article
- Export citation
Limit theorems for continuous-state branching processes with immigration
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 06 June 2022, pp. 599-624
- Print publication:
- June 2022
-
- Article
- Export citation
-
A continuous-state branching process with immigration having branching mechanism
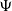 $\Psi$ and immigration mechanism
$\Psi$ and immigration mechanism 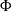 $\Phi$, a CBI
$\Phi$, a CBI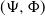 $(\Psi,\Phi)$ process for short, may have either of two different asymptotic regimes, depending on whether
$(\Psi,\Phi)$ process for short, may have either of two different asymptotic regimes, depending on whether 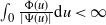 $\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u<\infty$ or
$\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u<\infty$ or 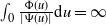 $\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u=\infty$. When
$\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u=\infty$. When 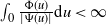 $\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u<\infty$, the CBI process has either a limit distribution or a growth rate dictated by the branching dynamics. When
$\int_{0}\frac{\Phi(u)}{|\Psi(u)|}\textrm{d} u<\infty$, the CBI process has either a limit distribution or a growth rate dictated by the branching dynamics. When 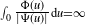 $\scriptstyle\int_{0}\tfrac{\Phi(u)}{|\Psi(u)|}\textrm{d} u=\infty$, immigration overwhelms branching dynamics. Asymptotics in the latter case are studied via a nonlinear time-dependent renormalization in law. Three regimes of weak convergence are exhibited. Processes with critical branching mechanisms subject to a regular variation assumption are studied. This article proves and extends results stated by M. Pinsky in ‘Limit theorems for continuous state branching processes with immigration’ (Bull. Amer. Math. Soc. 78, 1972).
$\scriptstyle\int_{0}\tfrac{\Phi(u)}{|\Psi(u)|}\textrm{d} u=\infty$, immigration overwhelms branching dynamics. Asymptotics in the latter case are studied via a nonlinear time-dependent renormalization in law. Three regimes of weak convergence are exhibited. Processes with critical branching mechanisms subject to a regular variation assumption are studied. This article proves and extends results stated by M. Pinsky in ‘Limit theorems for continuous state branching processes with immigration’ (Bull. Amer. Math. Soc. 78, 1972).