Refine search
Actions for selected content:
53197 results in Statistics and Probability
ECT volume 38 issue 3 Cover and Front matter
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 10 June 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
ECT volume 38 issue 3 Cover and Back matter
-
- Journal:
- Econometric Theory / Volume 38 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 10 June 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Hypergraphs without non-trivial intersecting subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 09 June 2022, pp. 1076-1091
-
- Article
- Export citation
-
A hypergraph
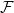 $\mathcal{F}$ is non-trivial intersecting if every pair of edges in it have a nonempty intersection, but no vertex is contained in all edges of
$\mathcal{F}$ is non-trivial intersecting if every pair of edges in it have a nonempty intersection, but no vertex is contained in all edges of 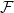 $\mathcal{F}$. Mubayi and Verstraëte showed that for every
$\mathcal{F}$. Mubayi and Verstraëte showed that for every 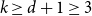 $k \ge d+1 \ge 3$ and
$k \ge d+1 \ge 3$ and 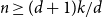 $n \ge (d+1)k/d$ every
$n \ge (d+1)k/d$ every 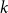 $k$-graph
$k$-graph 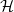 $\mathcal{H}$ on
$\mathcal{H}$ on  $n$ vertices without a non-trivial intersecting subgraph of size
$n$ vertices without a non-trivial intersecting subgraph of size 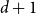 $d+1$ contains at most
$d+1$ contains at most 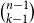 $\binom{n-1}{k-1}$ edges. They conjectured that the same conclusion holds for all
$\binom{n-1}{k-1}$ edges. They conjectured that the same conclusion holds for all 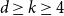 $d \ge k \ge 4$ and sufficiently large
$d \ge k \ge 4$ and sufficiently large  $n$. We confirm their conjecture by proving a stronger statement.
$n$. We confirm their conjecture by proving a stronger statement.They also conjectured that for
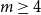 $m \ge 4$ and sufficiently large
$m \ge 4$ and sufficiently large  $n$ the maximum size of a
$n$ the maximum size of a 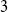 $3$-graph on
$3$-graph on  $n$ vertices without a non-trivial intersecting subgraph of size
$n$ vertices without a non-trivial intersecting subgraph of size 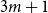 $3m+1$ is achieved by certain Steiner triple systems. We give a construction with more edges showing that their conjecture is not true in general.
$3m+1$ is achieved by certain Steiner triple systems. We give a construction with more edges showing that their conjecture is not true in general.
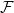
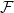
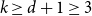
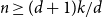
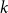
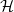

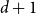
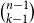
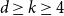

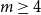

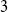

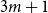
Frontmatter
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp i-iv
-
- Chapter
- Export citation
Part I - Properties
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 27-28
-
- Chapter
- Export citation
Part III - Estimation
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 175-176
-
- Chapter
- Export citation
7 - Extremal Processes
- from Part II - Emergence
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 148-174
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 1-26
-
- Chapter
- Export citation
References
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 240-248
-
- Chapter
- Export citation
2 - Scale Invariance, Power Laws, and Regular Variation
- from Part I - Properties
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 29-55
-
- Chapter
- Export citation
6 - Multiplicative Processes
- from Part II - Emergence
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 127-147
-
- Chapter
- Export citation
Part II - Emergence
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 105-106
-
- Chapter
- Export citation
9 - Estimating Power-Law Tails: Let the Tail Do the Talking
- from Part III - Estimation
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 197-237
-
- Chapter
- Export citation
On the peel number and the leaf-height of Galton–Watson trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 09 June 2022, pp. 68-90
-
- Article
- Export citation
-
We study several parameters of a random Bienaymé–Galton–Watson tree
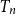 $T_n$ of size
$T_n$ of size  $n$ defined in terms of an offspring distribution
$n$ defined in terms of an offspring distribution 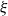 $\xi$ with mean
$\xi$ with mean 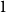 $1$ and nonzero finite variance
$1$ and nonzero finite variance 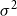 $\sigma ^2$. Let
$\sigma ^2$. Let 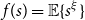 $f(s)=\mathbb{E}\{s^\xi \}$ be the generating function of the random variable
$f(s)=\mathbb{E}\{s^\xi \}$ be the generating function of the random variable 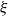 $\xi$. We show that the independence number is in probability asymptotic to
$\xi$. We show that the independence number is in probability asymptotic to 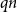 $qn$, where
$qn$, where 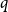 $q$ is the unique solution to
$q$ is the unique solution to 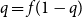 $q = f(1-q)$. One of the many algorithms for finding the largest independent set of nodes uses a notion of repeated peeling away of all leaves and their parents. The number of rounds of peeling is shown to be in probability asymptotic to
$q = f(1-q)$. One of the many algorithms for finding the largest independent set of nodes uses a notion of repeated peeling away of all leaves and their parents. The number of rounds of peeling is shown to be in probability asymptotic to 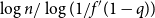 $\log n/\log (1/f'(1-q))$. Finally, we study a related parameter which we call the leaf-height. Also sometimes called the protection number, this is the maximal shortest path length between any node and a leaf in its subtree. If
$\log n/\log (1/f'(1-q))$. Finally, we study a related parameter which we call the leaf-height. Also sometimes called the protection number, this is the maximal shortest path length between any node and a leaf in its subtree. If 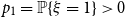 $p_1 = \mathbb{P}\{\xi =1\}\gt 0$, then we show that the maximum leaf-height over all nodes in
$p_1 = \mathbb{P}\{\xi =1\}\gt 0$, then we show that the maximum leaf-height over all nodes in 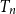 $T_n$ is in probability asymptotic to
$T_n$ is in probability asymptotic to 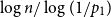 $\log n/\log (1/p_1)$. If
$\log n/\log (1/p_1)$. If 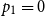 $p_1 = 0$ and
$p_1 = 0$ and  $\kappa$ is the first integer
$\kappa$ is the first integer 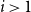 $i\gt 1$ with
$i\gt 1$ with 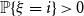 $\mathbb{P}\{\xi =i\}\gt 0$, then the leaf-height is in probability asymptotic to
$\mathbb{P}\{\xi =i\}\gt 0$, then the leaf-height is in probability asymptotic to 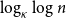 $\log _\kappa \log n$.
$\log _\kappa \log n$.
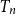

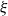
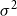
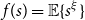
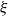
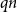
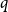
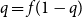
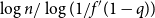
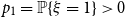
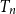
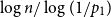
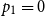

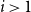
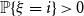
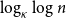
AAS Thematic issue: “Mortality: from Lee–Carter to AI”
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 June 2022, pp. 212-214
-
- Article
-
- You have access
- HTML
- Export citation
Acknowledgments
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp xiii-xiv
-
- Chapter
- Export citation
4 - Residual Lives, Hazard Rates, and Long Tails
- from Part I - Properties
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 85-104
-
- Chapter
- Export citation
8 - Estimating Power-Law Distributions: Listen to the Body
- from Part III - Estimation
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp 177-196
-
- Chapter
- Export citation
Contents
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp v-viii
-
- Chapter
- Export citation
Preface
-
- Book:
- The Fundamentals of Heavy Tails
- Published online:
- 17 May 2022
- Print publication:
- 09 June 2022, pp ix-xii
-
- Chapter
- Export citation
