Refine search
Actions for selected content:
53197 results in Statistics and Probability
Frontmatter
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp i-iv
-
- Chapter
- Export citation
5 - Multiple Regression and Diagnostics
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 101-129
-
- Chapter
- Export citation
8 - Logistic Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 178-194
-
- Chapter
- Export citation
6 - Indicators, Interactions, and Transformations
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 130-159
-
- Chapter
- Export citation
11 - Survival Analysis
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 233-244
-
- Chapter
- Export citation
3 - Introduction to Linear Regression
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 64-83
-
- Chapter
- Export citation
Contents
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp v-x
-
- Chapter
- Export citation
Selected Solutions and Hints
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 266-271
-
- Chapter
- Export citation
7 - Nonparametric Statistics
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp 160-177
-
- Chapter
- Export citation
Preface
-
- Book:
- Regression for Health and Social Science
- Published online:
- 20 May 2022
- Print publication:
- 12 May 2022, pp xi-xiv
-
- Chapter
- Export citation
The critical mean-field Chayes–Machta dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 11 May 2022, pp. 924-975
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The random-cluster model is a unifying framework for studying random graphs, spin systems and electrical networks that plays a fundamental role in designing efficient Markov Chain Monte Carlo (MCMC) sampling algorithms for the classical ferromagnetic Ising and Potts models. In this paper, we study a natural non-local Markov chain known as the Chayes–Machta (CM) dynamics for the mean-field case of the random-cluster model, where the underlying graph is the complete graph on n vertices. The random-cluster model is parametrised by an edge probability p and a cluster weight q. Our focus is on the critical regime:
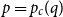 $p = p_c(q)$ and
$p = p_c(q)$ and 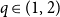 $q \in (1,2)$, where
$q \in (1,2)$, where 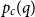 $p_c(q)$ is the threshold corresponding to the order–disorder phase transition of the model. We show that the mixing time of the CM dynamics is
$p_c(q)$ is the threshold corresponding to the order–disorder phase transition of the model. We show that the mixing time of the CM dynamics is 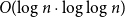 $O({\log}\ n \cdot \log \log n)$ in this parameter regime, which reveals that the dynamics does not undergo an exponential slowdown at criticality, a surprising fact that had been predicted (but not proved) by statistical physicists. This also provides a nearly optimal bound (up to the
$O({\log}\ n \cdot \log \log n)$ in this parameter regime, which reveals that the dynamics does not undergo an exponential slowdown at criticality, a surprising fact that had been predicted (but not proved) by statistical physicists. This also provides a nearly optimal bound (up to the 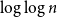 $\log\log n$ factor) for the mixing time of the mean-field CM dynamics in the only regime of parameters where no non-trivial bound was previously known. Our proof consists of a multi-phased coupling argument that combines several key ingredients, including a new local limit theorem, a precise bound on the maximum of symmetric random walks with varying step sizes and tailored estimates for critical random graphs. In addition, we derive an improved comparison inequality between the mixing time of the CM dynamics and that of the local Glauber dynamics on general graphs; this results in better mixing time bounds for the local dynamics in the mean-field setting.
$\log\log n$ factor) for the mixing time of the mean-field CM dynamics in the only regime of parameters where no non-trivial bound was previously known. Our proof consists of a multi-phased coupling argument that combines several key ingredients, including a new local limit theorem, a precise bound on the maximum of symmetric random walks with varying step sizes and tailored estimates for critical random graphs. In addition, we derive an improved comparison inequality between the mixing time of the CM dynamics and that of the local Glauber dynamics on general graphs; this results in better mixing time bounds for the local dynamics in the mean-field setting.
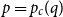
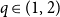
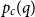
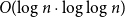
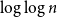
Comorbid conditions as risk factors for West Nile neuroinvasive disease in Ontario, Canada: a population-based cohort study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 11 May 2022, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction to biodiversity valuation tools
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The importance of biodiversity risks: Link to zoonotic diseases
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The importance of biodiversity risks
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Your reserves may be best estimate, but are they valid? (Discussion)
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Plasmid profile analysis of Escherichia coli and Salmonella enterica isolated from pigs, pork and humans
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e110
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The chromatic profile of locally colourable graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 10 May 2022, pp. 976-1009
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The classical Andrásfai-Erdős-Sós theorem considers the chromatic number of
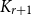 $K_{r + 1}$-free graphs with large minimum degree, and in the case,
$K_{r + 1}$-free graphs with large minimum degree, and in the case, 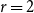 $r = 2$ says that any n-vertex triangle-free graph with minimum degree greater than
$r = 2$ says that any n-vertex triangle-free graph with minimum degree greater than 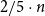 $2/5 \cdot n$ is bipartite. This began the study of the chromatic profile of triangle-free graphs: for each k, what minimum degree guarantees that a triangle-free graph is k-colourable? The chromatic profile has been extensively studied and was finally determined by Brandt and Thomassé. Triangle-free graphs are exactly those in which each neighbourhood is one-colourable. As a natural variant, Luczak and Thomassé introduced the notion of a locally bipartite graph in which each neighbourhood is 2-colourable. Here we study the chromatic profile of the family of graphs in which every neighbourhood is b-colourable (locally b-partite graphs) as well as the family where the common neighbourhood of every a-clique is b-colourable. Our results include the chromatic thresholds of these families (extending a result of Allen, Böttcher, Griffiths, Kohayakawa and Morris) as well as showing that every n-vertex locally b-partite graph with minimum degree greater than
$2/5 \cdot n$ is bipartite. This began the study of the chromatic profile of triangle-free graphs: for each k, what minimum degree guarantees that a triangle-free graph is k-colourable? The chromatic profile has been extensively studied and was finally determined by Brandt and Thomassé. Triangle-free graphs are exactly those in which each neighbourhood is one-colourable. As a natural variant, Luczak and Thomassé introduced the notion of a locally bipartite graph in which each neighbourhood is 2-colourable. Here we study the chromatic profile of the family of graphs in which every neighbourhood is b-colourable (locally b-partite graphs) as well as the family where the common neighbourhood of every a-clique is b-colourable. Our results include the chromatic thresholds of these families (extending a result of Allen, Böttcher, Griffiths, Kohayakawa and Morris) as well as showing that every n-vertex locally b-partite graph with minimum degree greater than 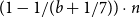 $(1 - 1/(b + 1/7)) \cdot n$ is
$(1 - 1/(b + 1/7)) \cdot n$ is 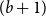 $(b + 1)$-colourable. Understanding these locally colourable graphs is crucial for extending the Andrásfai-Erdős-Sós theorem to non-complete graphs, which we develop elsewhere.
$(b + 1)$-colourable. Understanding these locally colourable graphs is crucial for extending the Andrásfai-Erdős-Sós theorem to non-complete graphs, which we develop elsewhere.
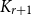
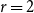
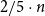
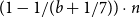
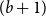
The impact of mortality shocks on modelling and insurance valuation as exemplified by COVID-19
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 3 / November 2022
- Published online by Cambridge University Press:
- 10 May 2022, pp. 498-526
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rainfall anomalies and typhoid fever in Blantyre, Malawi
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 10 May 2022, e122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
