Refine search
Actions for selected content:
52671 results in Statistics and Probability
Tree limits and limits of random trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 31 March 2021, pp. 849-893
-
- Article
-
- You have access
- Open access
- Export citation
The effect of ultrafiltration transmembrane permeation on the flow field in a surrogate system of an artificial kidney
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 30 March 2021, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Renal Replacement Therapies generally associated to the Artificial Kidney (AK) are membrane-based treatments that assure the separation functions of the failing kidney in extracorporeal blood circulation. Their progress from conventional hemodialysis towards high-flux hemodialysis (HFHD) through the introduction of ultrafiltration membranes characterized by high convective permeation fluxes intensified the need of elucidating the effect of the membrane fluid removal rates on the increase of the potentially blood-traumatizing shear stresses developed adjacently to the membrane. The AK surrogate consisting of two-compartments separated by an ultrafiltration membrane is set to have water circulation in the upper chamber mimicking the blood flow rates and the membrane fluid removal rates typical of HFHD. Pressure drop mirrors the shear stresses quantification and the modification of the velocities profiles. The increase on pressure drop when comparing flows in slits with a permeable membrane and an impermeable wall is ca. 512% and 576% for
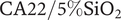 $ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and
$ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and 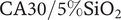 $ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.
$ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.
DYNAMIC ASSET ALLOCATION FOR TARGET DATE FUNDS UNDER THE BENCHMARK APPROACH
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. 449-474
- Print publication:
- May 2021
-
- Article
- Export citation
Relationship between changes in the course of COVID-19 and ratio of neutrophils-to-lymphocytes and related parameters in patients with severe vs. common disease
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 March 2021, e81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
OPTIMAL INCENTIVE-COMPATIBLE INSURANCE WITH BACKGROUND RISK
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. 661-688
- Print publication:
- May 2021
-
- Article
- Export citation
PES volume 35 issue 2 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. f1-f2
-
- Article
-
- You have access
- Export citation
OPTIMAL REINSURANCE DESIGN WITH DISTORTION RISK MEASURES AND ASYMMETRIC INFORMATION
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. 607-629
- Print publication:
- May 2021
-
- Article
- Export citation
PES volume 35 issue 2 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation
SARS-CoV-2 re-infection: development of an epidemiological definition from India
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 26 March 2021, e82
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Index
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 687-690
-
- Chapter
- Export citation
References
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 667-682
-
- Chapter
- Export citation
Contents
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp vii-x
-
- Chapter
- Export citation
5 - Linear Nonparametric Estimators
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 389-466
-
- Chapter
- Export citation
Epidemiological analysis of a COVID-19 outbreak associated with an infected surgeon
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 25 March 2021, e77
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A simple model for the total number of SARS-CoV-2 infections on a national level
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 25 March 2021, e80
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp xi-xiv
-
- Chapter
- Export citation
7 - Likelihood-Based Procedures
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 541-606
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp i-iv
-
- Chapter
- Export citation
8 - Adaptive Inference
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 607-666
-
- Chapter
- Export citation
Dedication
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp v-vi
-
- Chapter
- Export citation
