Refine search
Actions for selected content:
52669 results in Statistics and Probability
6 - Bayesian Networks
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 139-168
-
- Chapter
- Export citation
9 - p-Values of Likelihood Ratios
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 254-282
-
- Chapter
- Export citation
2 - Evidence and the Likelihood Ratio
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 30-60
-
- Chapter
- Export citation
5 - The Bayesian Framework in Legal Cases
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 109-138
-
- Chapter
- Export citation
Contents
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp v-viii
-
- Chapter
- Export citation
10 - From Evidence to Decision
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 283-309
-
- Chapter
- Export citation
Index
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 440-442
-
- Chapter
- Export citation
13 - Belief Functions and their Applications
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 364-402
-
- Chapter
- Export citation
SEMIPARAMETRIC IDENTIFICATION AND FISHER INFORMATION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 08 April 2021, pp. 301-338
-
- Article
- Export citation
12 - Familial Searching
-
- Book:
- Probability and Forensic Evidence
- Published online:
- 09 April 2021
- Print publication:
- 08 April 2021, pp 342-363
-
- Chapter
- Export citation
On the size-Ramsey number of grid graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 06 April 2021, pp. 670-685
-
- Article
- Export citation
THE NEAREST UNVISITED VERTEX WALK ON RANDOM GRAPHS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 05 April 2021, pp. 851-867
-
- Article
-
- You have access
- Open access
- Export citation
Immunogenicity and safety of a quadrivalent meningococcal tetanus toxoid-conjugate vaccine administered concomitantly with other paediatric vaccines in toddlers: a phase III randomised study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 April 2021, e90
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COVID-19 research priorities for non-pharmaceutical public health and social measures
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 April 2021, e87
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the effects of reopening of schools on the course of the epidemic of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 April 2021, e86
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
mvClaim: an R package for multivariate general insurance claims severity modelling
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 05 April 2021, pp. 441-457
-
- Article
- Export citation
Identifying COVID-19 cases in outpatient settings
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 April 2021, e92
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A PROBABILISTIC ℓ1 METHOD FOR CLUSTERING HIGH-DIMENSIONAL DATA
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 05 April 2021, pp. 433-448
-
- Article
- Export citation
Tree limits and limits of random trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 31 March 2021, pp. 849-893
-
- Article
-
- You have access
- Open access
- Export citation
The effect of ultrafiltration transmembrane permeation on the flow field in a surrogate system of an artificial kidney
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 30 March 2021, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Renal Replacement Therapies generally associated to the Artificial Kidney (AK) are membrane-based treatments that assure the separation functions of the failing kidney in extracorporeal blood circulation. Their progress from conventional hemodialysis towards high-flux hemodialysis (HFHD) through the introduction of ultrafiltration membranes characterized by high convective permeation fluxes intensified the need of elucidating the effect of the membrane fluid removal rates on the increase of the potentially blood-traumatizing shear stresses developed adjacently to the membrane. The AK surrogate consisting of two-compartments separated by an ultrafiltration membrane is set to have water circulation in the upper chamber mimicking the blood flow rates and the membrane fluid removal rates typical of HFHD. Pressure drop mirrors the shear stresses quantification and the modification of the velocities profiles. The increase on pressure drop when comparing flows in slits with a permeable membrane and an impermeable wall is ca. 512% and 576% for
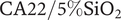 $ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and
$ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and 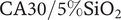 $ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.
$ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.