Refine search
Actions for selected content:
52675 results in Statistics and Probability
9 - Distance Metrics and Data Transformations
- from Part III - Classifiers and Tools
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp 196-218
-
- Chapter
- Export citation
Part V - Advanced Topics
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp 291-292
-
- Chapter
- Export citation
7 - Classifiers and Tools
- from Part III - Classifiers and Tools
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp 143-172
-
- Chapter
- Export citation
Part III - Classifiers and Tools
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp 141-142
-
- Chapter
- Export citation
Preface
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp xiii-xv
-
- Chapter
- Export citation
10 - Information Theory and Decision Trees
- from Part III - Classifiers and Tools
-
- Book:
- Essentials of Pattern Recognition
- Published online:
- 08 December 2020
- Print publication:
- 19 November 2020, pp 219-242
-
- Chapter
- Export citation

Foundations of Probabilistic Programming
-
- Published online:
- 18 November 2020
- Print publication:
- 03 December 2020
-
- Book
-
- You have access
- Open access
- Export citation
Evaluation of the Point of Care Molecular Diagnostic Genedrive HCV ID Kit for the detection of HCV RNA in clinical samples
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 18 November 2020, pp. 1-23
-
- Article
-
- You have access
- Export citation
Risk factors associated with outbreaks of seasonal infectious disease in school settings, England, UK
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 18 November 2020, e287
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Numerical simulation, clustering, and prediction of multicomponent polymer precipitation
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 17 November 2020, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hodge Representations
- Part of
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 17 November 2020, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Green–Griffiths–Kerr introduced Hodge representations to classify the Hodge groups of polarized Hodge structures, and the corresponding Mumford–Tate subdomains. We summarize how, given a fixed period domain
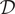 $ \mathcal{D} $, to enumerate the Hodge representations and corresponding Mumford–Tate subdomains
$ \mathcal{D} $, to enumerate the Hodge representations and corresponding Mumford–Tate subdomains 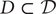 $ D \subset\mathcal{D} $. The procedure is illustrated in two examples: (i) weight two Hodge structures with
$ D \subset\mathcal{D} $. The procedure is illustrated in two examples: (i) weight two Hodge structures with 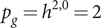 $ {p}_g={h}^{2,0}=2 $; and (ii) weight three CY-type Hodge structures.
$ {p}_g={h}^{2,0}=2 $; and (ii) weight three CY-type Hodge structures.
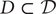
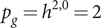
Uninterruptible Power Supply Improves Precision and External Validity of Telomere Length Measurement via qPCR
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 16 November 2020, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence of pertussis in Madagascar and implications for vaccination
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 16 November 2020, e283
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lipschitz bijections between boolean functions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 16 November 2020, pp. 513-525
-
- Article
- Export citation
-
We answer four questions from a recent paper of Rao and Shinkar [17] on Lipschitz bijections between functions from {0, 1}n to {0, 1}. (1) We show that there is no O(1)-bi-Lipschitz bijection from Dictator to XOR such that each output bit depends on O(1) input bits. (2) We give a construction for a mapping from XOR to Majority which has average stretch
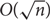 $O(\sqrt{n})$, matching a previously known lower bound. (3) We give a 3-Lipschitz embedding
$O(\sqrt{n})$, matching a previously known lower bound. (3) We give a 3-Lipschitz embedding 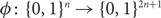 $\phi \colon\{0,1\}^n \to \{0,1\}^{2n+1}$ such that
$\phi \colon\{0,1\}^n \to \{0,1\}^{2n+1}$ such that 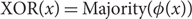 $${\rm{XOR }}(x) = {\rm{ Majority }}(\phi (x))$$ for all
$${\rm{XOR }}(x) = {\rm{ Majority }}(\phi (x))$$ for all 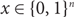 $x \in \{0,1\}^n$. (4) We show that with high probability there is an O(1)-bi-Lipschitz mapping from Dictator to a uniformly random balanced function.
$x \in \{0,1\}^n$. (4) We show that with high probability there is an O(1)-bi-Lipschitz mapping from Dictator to a uniformly random balanced function.
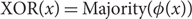
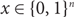
Factors associated with typical enteropathogenic Escherichia coli infection among children <5 years old with moderate-to-severe diarrhoea in rural western Kenya, 2008–2012
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 16 November 2020, e281
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A simple differential geometry for complex networks
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 16 November 2020, pp. S106-S133
-
- Article
- Export citation
Prevalence of asymptomatic COVID-19 infection using a seroepidemiological survey
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e300
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ANALYTICAL RESULTS ON THE SERVICE PERFORMANCE OF STOCHASTIC CLEARING SYSTEMS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 13 November 2020, pp. 217-236
-
- Article
- Export citation
-
Stochastic clearing theory has wide-spread applications in the context of supply chain and service operations management. Historical application domains include bulk service queues, inventory control, and transportation planning (e.g., vehicle dispatching and shipment consolidation). In this paper, motivated by a fundamental application in shipment consolidation, we revisit the notion of service performance for stochastic clearing system operation. More specifically, our goal is to evaluate and compare service performance of alternative operational policies for clearing decisions, as quantified by a measure of timely service referred to as Average Order Delay (
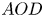 $AOD$). All stochastic clearing systems are subject to service delay due to the inherent clearing practice, and
$AOD$). All stochastic clearing systems are subject to service delay due to the inherent clearing practice, and  $\textrm {AOD}$ can be thought of as a benchmark for evaluating timely service. Although stochastic clearing theory has a long history, the existing literature on the analysis of
$\textrm {AOD}$ can be thought of as a benchmark for evaluating timely service. Although stochastic clearing theory has a long history, the existing literature on the analysis of 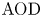 $\textrm {AOD}$ as a service measure has several limitations. Hence, we extend the previous analysis by proposing a more general method for a generic analytical derivation of
$\textrm {AOD}$ as a service measure has several limitations. Hence, we extend the previous analysis by proposing a more general method for a generic analytical derivation of 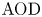 $\textrm {AOD}$ for any renewal-type clearing policy, including but not limited to alternative shipment consolidation policies in the previous literature. Our proposed method utilizes a new martingale point of view and lends itself for a generic analytical characterization of
$\textrm {AOD}$ for any renewal-type clearing policy, including but not limited to alternative shipment consolidation policies in the previous literature. Our proposed method utilizes a new martingale point of view and lends itself for a generic analytical characterization of 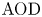 $\textrm {AOD}$, leading to a complete comparative analysis of alternative renewal-type clearing policies. Hence, we also close the gaps in the literature on shipment consolidation via a complete set of analytically provable results regarding
$\textrm {AOD}$, leading to a complete comparative analysis of alternative renewal-type clearing policies. Hence, we also close the gaps in the literature on shipment consolidation via a complete set of analytically provable results regarding 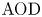 $\textrm {AOD}$ which were only illustrated through numerical tests previously.
$\textrm {AOD}$ which were only illustrated through numerical tests previously.
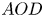
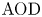
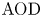
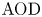
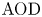
AVERAGE DERIVATIVE ESTIMATION UNDER MEASUREMENT ERROR
-
- Journal:
- Econometric Theory / Volume 37 / Issue 5 / October 2021
- Published online by Cambridge University Press:
- 13 November 2020, pp. 1004-1033
-
- Article
- Export citation
-
In this paper, we derive the asymptotic properties of the density-weighted average derivative estimator when a regressor is contaminated with classical measurement error and the density of this error must be estimated. Average derivatives of conditional mean functions are used extensively in economics and statistics, most notably in semiparametric index models. As well as ordinary smooth measurement error, we provide results for supersmooth error distributions. This is a particularly important class of error distribution as it includes the Gaussian density. We show that under either type of measurement error, despite using nonparametric deconvolution techniques and an estimated error characteristic function, we are able to achieve a
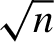 $\sqrt {n}$-rate of convergence for the average derivative estimator. Interestingly, if the measurement error density is symmetric, the asymptotic variance of the average derivative estimator is the same irrespective of whether the error density is estimated or not. The promising finite sample performance of the estimator is shown through a Monte Carlo simulation.
$\sqrt {n}$-rate of convergence for the average derivative estimator. Interestingly, if the measurement error density is symmetric, the asymptotic variance of the average derivative estimator is the same irrespective of whether the error density is estimated or not. The promising finite sample performance of the estimator is shown through a Monte Carlo simulation.
Community movement and COVID-19: a global study using Google's Community Mobility Reports
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e284
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
