Refine search
Actions for selected content:
52675 results in Statistics and Probability
The insignificant structural break in the relationship between improved observed hand hygiene on methicillin-resistant Staphylococcus aureus bloodstream infection rates in Ireland: a data-driven re-analysis
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e297
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development and validation of a simple risk score for diagnosing COVID-19 in the emergency room
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e273
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WHY DOES A HUMAN DIE? A STRUCTURAL APPROACH TO COHORT-WISE MORTALITY PREDICTION UNDER SURVIVAL ENERGY HYPOTHESIS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 13 November 2020, pp. 191-219
- Print publication:
- January 2021
-
- Article
-
- You have access
- Open access
- Export citation
Understanding the influence of the COVID-19 pandemic on hospital-based mortality in Burundi: a cross-sectional study comparing two time periods
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e280
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chasing the ghost of infection past: identifying thresholds of change during the COVID-19 infection in Spain
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 November 2020, e282
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A MEAN FIELD GAME ANALYSIS OF SIR DYNAMICS WITH VACCINATION
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 13 November 2020, pp. 482-499
-
- Article
- Export citation
-
We analyze a mean field game model of SIR dynamics (Susceptible, Infected, and Recovered) where players choose when to vaccinate. We show that this game admits a unique mean field equilibrium (MFE) that consists in vaccinating at a maximal rate until a given time and then not vaccinating. The vaccination strategy that minimizes the total cost has the same structure as the MFE. We prove that the vaccination period of the MFE is always smaller than the one minimizing the total cost. This implies that, to encourage optimal vaccination behavior, vaccination should always be subsidized. Finally, we provide numerical experiments to study the convergence of the equilibrium when the system is composed by a finite number of agents (
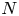 $N$) to the MFE. These experiments show that the convergence rate of the cost is
$N$) to the MFE. These experiments show that the convergence rate of the cost is 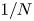 $1/N$ and the convergence of the switching curve is monotone.
$1/N$ and the convergence of the switching curve is monotone.
The effect of a nighttime zoo event on spider monkey (Ateles geoffroyi) behavior
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 10 November 2020, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Making Kr+1-free graphs r-partite
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 10 November 2020, pp. 609-618
-
- Article
-
- You have access
- Open access
- Export citation
A spatial machine learning model for analysing customers’ lapse behaviour in life insurance
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 10 November 2020, pp. 367-393
-
- Article
- Export citation
LIMIT THEOREMS FOR FACTOR MODELS
-
- Journal:
- Econometric Theory / Volume 37 / Issue 5 / October 2021
- Published online by Cambridge University Press:
- 09 November 2020, pp. 1034-1074
-
- Article
- Export citation
A MULTIPLEX INTERDEPENDENT DURATIONS MODEL
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 09 November 2020, pp. 1238-1266
-
- Article
- Export citation
SUBGEOMETRICALLY ERGODIC AUTOREGRESSIONS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 09 November 2020, pp. 959-985
-
- Article
- Export citation
-
In this paper, we discuss how the notion of subgeometric ergodicity in Markov chain theory can be exploited to study stationarity and ergodicity of nonlinear time series models. Subgeometric ergodicity means that the transition probability measures converge to the stationary measure at a rate slower than geometric. Specifically, we consider suitably defined higher-order nonlinear autoregressions that behave similarly to a unit root process for large values of the observed series but we place almost no restrictions on their dynamics for moderate values of the observed series. Results on the subgeometric ergodicity of nonlinear autoregressions have previously appeared only in the first-order case. We provide an extension to the higher-order case and show that the autoregressions we consider are, under appropriate conditions, subgeometrically ergodic. As useful implications, we also obtain stationarity and
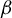 $\beta $-mixing with subgeometrically decaying mixing coefficients.
$\beta $-mixing with subgeometrically decaying mixing coefficients.

Statistics and the Quest for Quality Journalism
- A Study in Quantitative Reporting
-
- Published by:
- Anthem Press
- Published online:
- 07 November 2020
- Print publication:
- 29 October 2020

Statistics Using Stata
- An Integrative Approach
-
- Published online:
- 06 November 2020
- Print publication:
- 27 February 2020
-
- Book
- Export citation
Trends of seroprevalence of Chagas diseases in healthy blood donors, solid organ donors and heart transplant recipients: experience of a single health care centre in Colombia
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 06 November 2020, e277
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence of invasive aspergillosis in suspected pulmonary tuberculosis at a referral tuberculosis hospital in Shandong, China
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 05 November 2020, e275
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tail bounds on hitting times of randomized search heuristics using variable drift analysis
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 05 November 2020, pp. 550-569
-
- Article
-
- You have access
- Export citation
Pneumococcal serotypes in children, clinical presentation and antimicrobial susceptibility in the PCV13 era
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 05 November 2020, e279
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Subgraph counts for dense random graphs with specified degrees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 05 November 2020, pp. 460-497
-
- Article
- Export citation
Association between season of vaccination and antibody levels against infectious diseases
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 05 November 2020, e276
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
