Refine listing
Actions for selected content:
144680 results in Open Access
White Hat, Black Hat, Slouch Hat: Could Australia’s Military Cyber Capability be Deployed Under Commonwealth Call-Out Powers?
-
- Journal:
- Federal Law Review / Volume 51 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 182-204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Role of Conditional Likelihoods in Latent Variable Modeling
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 799-834
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Khomeini Kitsch: Material Cultures of the Iran Hostage Crisis
-
- Journal:
- Iranian Studies / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 12 February 2025, pp. 125-151
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From Unfulled Rag to New Cloak: Lukan Clarifications on a Markan Theme
-
- Journal:
- New Testament Studies / Volume 71 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 07 August 2025, pp. 19-28
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ordinal Outcome State-Space Models for Intensive Longitudinal Data
-
- Journal:
- Psychometrika / Volume 89 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1203-1229
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Possible Futures for Network Psychometrics
-
- Journal:
- Psychometrika / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 253-265
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sparse and Simple Structure Estimation via Prenet Penalization
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1381-1406
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transnational Peer Review for Regulating Financial Stability
-
- Journal:
- Federal Law Review / Volume 51 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 442-465
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Correction to: Generalized Structured Component Analysis Accommodating Convex Components: A Knowledge-Based Multivariate Method with Interpretable Composite Indexes
-
- Journal:
- Psychometrika / Volume 89 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, p. 1366
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factor Analysis Procedures Revisited from the Comprehensive Model with Unique Factors Decomposed into Specific Factors and Errors
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 967-991
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond the Mean: A Flexible Framework for Studying Causal Effects Using Linear Models
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 868-901
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Graph-based causal models are a flexible tool for causal inference from observational data. In this paper, we develop a comprehensive framework to define, identify, and estimate a broad class of causal quantities in linearly parametrized graph-based models. The proposed method extends the literature, which mainly focuses on causal effects on the mean level and the variance of an outcome variable. For example, we show how to compute the probability that an outcome variable realizes within a target range of values given an intervention, a causal quantity we refer to as the probability of treatment success. We link graph-based causal quantities defined via the do-operator to parameters of the model implied distribution of the observed variables using so-called causal effect functions. Based on these causal effect functions, we propose estimators for causal quantities and show that these estimators are consistent and converge at a rate of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N^{-1/2}$$\end{document}
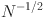 under standard assumptions. Thus, causal quantities can be estimated based on sample sizes that are typically available in the social and behavioral sciences. In case of maximum likelihood estimation, the estimators are asymptotically efficient. We illustrate the proposed method with an example based on empirical data, placing special emphasis on the difference between the interventional and conditional distribution.
under standard assumptions. Thus, causal quantities can be estimated based on sample sizes that are typically available in the social and behavioral sciences. In case of maximum likelihood estimation, the estimators are asymptotically efficient. We illustrate the proposed method with an example based on empirical data, placing special emphasis on the difference between the interventional and conditional distribution.
Offline volunteering during COVID-19: a survey experiment with prior and prospective blood donors
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 415-427
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic Posterior Normality of Multivariate Latent Traits in an IRT Model
-
- Journal:
- Psychometrika / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1146-1172
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forecasting Intra-individual Changes of Affective States Taking into Account Inter-individual Differences Using Intensive Longitudinal Data from a University Student Dropout Study in Math
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 533-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The longitudinal process that leads to university student dropout in STEM subjects can be described by referring to (a) inter-individual differences (e.g., cognitive abilities) as well as (b) intra-individual changes (e.g., affective states), (c) (unobserved) heterogeneity of trajectories, and d) time-dependent variables. Large dynamic latent variable model frameworks for intensive longitudinal data (ILD) have been proposed which are (partially) capable of simultaneously separating the complex data structures (e.g., DLCA; Asparouhov et al. in Struct Equ Model 24:257–269, 2017; DSEM; Asparouhov et al. in Struct Equ Model 25:359–388, 2018; NDLC-SEM, Kelava and Brandt in Struct Equ Model 26:509–528, 2019). From a methodological perspective, forecasting in dynamic frameworks allowing for real-time inferences on latent or observed variables based on ongoing data collection has not been an extensive research topic. From a practical perspective, there has been no empirical study on student dropout in math that integrates ILD, dynamic frameworks, and forecasting of critical states of the individuals allowing for real-time interventions. In this paper, we show how Bayesian forecasting of multivariate intra-individual variables and time-dependent class membership of individuals (affective states) can be performed in these dynamic frameworks using a Forward Filtering Backward Sampling method. To illustrate our approach, we use an empirical example where we apply the proposed forecasting method to ILD from a large university student dropout study in math with multivariate observations collected over 50 measurement occasions from multiple students (\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N = 122$$\end{document}
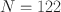 ). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
MTVE: Magdeburg tool for video experiments
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 609-619
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Proof of Reliability Convergence to 1 at Rate of Spearman–Brown Formula for Random Test Forms and Irrespective of Item Pool Dimensionality
-
- Journal:
- Psychometrika / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 774-795
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Bradley–Terry Regression Trunk approach for Modeling Preference Data with Small Trees
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1443-1465
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Incomplete Tests of Conditional Association for the Assessment of Model Assumptions
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1214-1237
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Shadow-Test Approach to Adaptive Item Calibration
-
- Journal:
- Psychometrika / Volume 85 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 301-321
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A shadow-test approach to the calibration of field-test items embedded in adaptive testing is presented. The objective function used in the shadow-test model selects both the operational and field-test items adaptively using a Bayesian version of the criterion of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$D_{\mathrm{s}}$$\end{document}
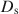 -optimality. The constraint set for the model can be used to hide the field-test items completely in the content of the test as well as to deal with such practical issues as random control of their exposure rates. The approach runs on efficient implementations of the Gibbs sampler for the real-time updating of the ability and field-test parameters. Optimal settings for the proposed algorithms were found and used to demonstrate item calibration with smaller than traditional sample sizes in runtimes fully comparable with conventional adaptive testing.
-optimality. The constraint set for the model can be used to hide the field-test items completely in the content of the test as well as to deal with such practical issues as random control of their exposure rates. The approach runs on efficient implementations of the Gibbs sampler for the real-time updating of the ability and field-test parameters. Optimal settings for the proposed algorithms were found and used to demonstrate item calibration with smaller than traditional sample sizes in runtimes fully comparable with conventional adaptive testing.
The Australia’s Foreign Relations Act and Australia’s Relationship with International Law
-
- Journal:
- Federal Law Review / Volume 51 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 257-281
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
