Refine listing
Actions for selected content:
144680 results in Open Access
Nuclear Shibboleths: The Logics and Future of Nuclear Nonuse
-
- Journal:
- International Organization / Volume 79 / Issue 1 / Winter 2025
- Published online by Cambridge University Press:
- 10 January 2025, pp. 117-145
- Print publication:
- Winter 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Short Introduction to Wittgenstein’s Private Language Argument
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Latent Variable Mixed-Effects Location Scale Model with an Application to Daily Diary Data
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1548-1570
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Pioneering Turkish Muslim Actresses: Afife Jale and Bedia Muvahhit's Trajectories in the Turkish Stage
-
- Journal:
- Theatre Survey / Volume 66 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 16 January 2025, pp. 74-94
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reevaluating the Organization of Lapidary Production at Chaco Canyon
-
- Journal:
- American Antiquity / Volume 90 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 06 February 2025, pp. 90-112
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE ‘INNUMERABLE’ OF ZARAGOZA: A MARTYR CULT BETWEEN CITY AND MONASTERY
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Computation for Latent Variable Model Estimation: A Unified Stochastic Proximal Framework
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1473-1502
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the Non-Existence of Optimal Solutions and the Occurrence of “Degeneracy” in the CANDECOMP/PARAFAC Model
-
- Journal:
- Psychometrika / Volume 73 / Issue 3 / September 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 431-439
-
- Article
-
- You have access
- Open access
- Export citation
Human Rights and Equality Commissions in Kenya and Their Role in Tackling Poverty and Economic Inequality
-
- Journal:
- Federal Law Review / Volume 51 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 422-441
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An Attention-Based Diffusion Model for Psychometric Analyses
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 938-972
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generalized Structured Component Analysis Accommodating Convex Components: A Knowledge-Based Multivariate Method with Interpretable Composite Indexes
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 241-266
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Erratum to: Maximum Likelihood Estimation of a Social Relations Structural Equation Model
-
- Journal:
- Psychometrika / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 01 January 2025, p. 842
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the robustness of social norm elicitation
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 531-543
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Standardized Regression Coefficients and Newly Proposed Estimators for R2\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${R}^{{2}}$$\end{document}
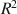 in Multiply Imputed Data
in Multiply Imputed Data
-
- Journal:
- Psychometrika / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 185-205
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Whenever statistical analyses are applied to multiply imputed datasets, specific formulas are needed to combine the results into one overall analysis, also called combination rules. In the context of regression analysis, combination rules for the unstandardized regression coefficients, the t-tests of the regression coefficients, and the F-tests for testing \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
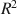 for significance have long been established. However, there is still no general agreement on how to combine the point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
for significance have long been established. However, there is still no general agreement on how to combine the point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}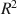 in multiple regression applied to multiply imputed datasets. Additionally, no combination rules for standardized regression coefficients and their confidence intervals seem to have been developed at all. In the current article, two sets of combination rules for the standardized regression coefficients and their confidence intervals are proposed, and their statistical properties are discussed. Additionally, two improved point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
in multiple regression applied to multiply imputed datasets. Additionally, no combination rules for standardized regression coefficients and their confidence intervals seem to have been developed at all. In the current article, two sets of combination rules for the standardized regression coefficients and their confidence intervals are proposed, and their statistical properties are discussed. Additionally, two improved point estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}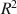 in multiply imputed data are proposed, which in their computation use the pooled standardized regression coefficients. Simulations show that the proposed pooled standardized coefficients produce only small bias and that their 95% confidence intervals produce coverage close to the theoretical 95%. Furthermore, the simulations show that the newly proposed pooled estimates for \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document}
in multiply imputed data are proposed, which in their computation use the pooled standardized regression coefficients. Simulations show that the proposed pooled standardized coefficients produce only small bias and that their 95% confidence intervals produce coverage close to the theoretical 95%. Furthermore, the simulations show that the newly proposed pooled estimates for \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^{2}$$\end{document} are less biased than two earlier proposed pooled estimates.
are less biased than two earlier proposed pooled estimates.
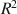
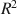
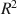
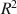

Computational Psychometrics: New Methodologies for a New Generation of Digital Learning and Assessment
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1571-1574
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sample Size Determination for Interval Estimation of the Prevalence of a Sensitive Attribute Under Randomized Response Models
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1361-1389
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reducing Attenuation Bias in Regression Analyses Involving Rating Scale Data via Psychometric Modeling
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 42-63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Conservation Crisis? Status of jaguars Panthera onca in Corcovado National Park, Costa Rica —CORRIGENDUM
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayes Factors for Evaluating Latent Monotonicity in Polytomous Item Response Theory Models
-
- Journal:
- Psychometrika / Volume 84 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 846-869
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hittite cultural conventions on hygiene
-
- Journal:
- Anatolian Studies / Volume 75 / 2025
- Published online by Cambridge University Press:
- 28 August 2025, pp. 29-45
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- Export citation
