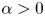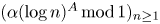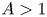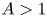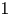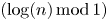Refine listing
Actions for selected content:
144876 results in Open Access
Estimating and Using Block Information in the Thurstonian IRT Model
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1556-1589
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Multidimensional forced-choice (MFC) tests are increasing in popularity but their construction is complex. The Thurstonian item response model (Thurstonian IRT model) is most often used to score MFC tests that contain dominance items. Currently, in a frequentist framework, information about the latent traits in the Thurstonian IRT model is computed for binary outcomes of pairwise comparisons, but this approach neglects stochastic dependencies. In this manuscript, it is shown how to estimate Fisher information on the block level. A simulation study showed that the observed and expected standard errors based on the block information were similarly accurate. When local dependencies for block sizes \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$>\,2$$\end{document}
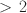 were neglected, the standard errors were underestimated, except with the maximum a posteriori estimator. It is shown how the multidimensional block information can be summarized for test construction. A simulation study and an empirical application showed small differences between the block information summaries depending on the outcome considered. Thus, block information can aid the construction of reliable MFC tests.
were neglected, the standard errors were underestimated, except with the maximum a posteriori estimator. It is shown how the multidimensional block information can be summarized for test construction. A simulation study and an empirical application showed small differences between the block information summaries depending on the outcome considered. Thus, block information can aid the construction of reliable MFC tests.
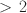
J. S. Mill on Harm Prevention
-
- Journal:
- Philosophy / Volume 100 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 154-164
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Psychometric Network Models from Time-Series and Panel Data
-
- Journal:
- Psychometrika / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 206-231
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Insensitivity of the Chi-Square Model Test to Nonlinear Misspecification in Structural Equation Models
-
- Journal:
- Psychometrika / Volume 74 / Issue 3 / September 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 443-455
-
- Article
-
- You have access
- Open access
- Export citation
Minding the Children: Carework, Empathy, and the Phinneas Gage Effect
-
- Journal:
- Philosophy / Volume 100 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 26-49
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Biclustering Models for Two-Mode Ordinal Data
-
- Journal:
- Psychometrika / Volume 81 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 611-624
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Time to Intervene: A Continuous-Time Approach to Network Analysis and Centrality
-
- Journal:
- Psychometrika / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 214-252
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A nonabelian Fourier transform for tempered unipotent representations
- Part of
-
- Journal:
- Compositio Mathematica / Volume 161 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 12 March 2025, pp. 13-73
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We define an involution on the elliptic space of tempered unipotent representations of inner twists of a split simple
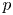 $p$-adic group
$p$-adic group 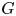 $G$ and investigate its behaviour with respect to restrictions to reductive quotients of maximal compact open subgroups. In particular, we formulate a precise conjecture about the relation with a version of Lusztig's nonabelian Fourier transform on the space of unipotent representations of the (possibly disconnected) reductive quotients of maximal compact subgroups. We give evidence for the conjecture, including proofs for
$G$ and investigate its behaviour with respect to restrictions to reductive quotients of maximal compact open subgroups. In particular, we formulate a precise conjecture about the relation with a version of Lusztig's nonabelian Fourier transform on the space of unipotent representations of the (possibly disconnected) reductive quotients of maximal compact subgroups. We give evidence for the conjecture, including proofs for 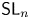 ${\mathsf {SL}}_n$ and
${\mathsf {SL}}_n$ and 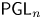 ${\mathsf {PGL}}_n$.
${\mathsf {PGL}}_n$.
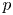
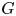
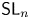
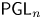
27th Annual Grotius Lecture on International Law
-
- Journal:
- Proceedings of the ASIL Annual Meeting / Volume 119 / 2025
- Published online by Cambridge University Press:
- 04 February 2026, pp. 125-143
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factor Uniqueness of the Structural Parafac Model
-
- Journal:
- Psychometrika / Volume 85 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 555-574
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cognitive ability and the house money effect in public goods games
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 393-414
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Constrained Dual Scaling for Detecting Response Styles in Categorical Data
-
- Journal:
- Psychometrika / Volume 80 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 968-994
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Probing DNA melting behaviour under vibrational strong coupling
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e13
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Continuous-time random walk model for the diffusive motion of helicases
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 09 October 2025, e26
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
State Immunity from Non-Judicial Measures of Constraint
-
- Journal:
- International & Comparative Law Quarterly / Volume 74 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 31 March 2025, pp. 179-204
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of the Weighted Kappa and Its Maximum with Markov Moves
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1270-1289
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The role of performance in the rituals of Išpuini and Minua: Religion, community and legitimacy in the formation of Urartu
-
- Journal:
- Anatolian Studies / Volume 75 / 2025
- Published online by Cambridge University Press:
- 28 August 2025, pp. 81-99
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- Export citation
Counting geodesics between surface triangulations
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 178 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 22 January 2025, pp. 45-63
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a surface
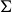 $\Sigma$ equipped with a set P of marked points, we consider the triangulations of
$\Sigma$ equipped with a set P of marked points, we consider the triangulations of 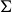 $\Sigma$ with vertex set P. The flip-graph of
$\Sigma$ with vertex set P. The flip-graph of 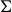 $\Sigma$ is the graph whose vertices are these triangulations, and whose edges correspond to flipping arcs in these triangulations. The flip-graph of a surface appears in the study of moduli spaces and mapping class groups. We consider the number of geodesics in the flip-graph of
$\Sigma$ is the graph whose vertices are these triangulations, and whose edges correspond to flipping arcs in these triangulations. The flip-graph of a surface appears in the study of moduli spaces and mapping class groups. We consider the number of geodesics in the flip-graph of 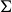 $\Sigma$ between two triangulations as a function of their distance. We show that this number grows exponentially provided the surface has enough topology, and that in the remaining cases the growth is polynomial.
$\Sigma$ between two triangulations as a function of their distance. We show that this number grows exponentially provided the surface has enough topology, and that in the remaining cases the growth is polynomial.
Factor analysis models via I-divergence optimization
-
- Journal:
- Psychometrika / Volume 81 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 702-726
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a positive definite covariance matrix \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{\Sigma }$$\end{document}
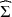 of dimension n, we approximate it with a covariance of the form \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$HH^\top +D$$\end{document}
of dimension n, we approximate it with a covariance of the form \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$HH^\top +D$$\end{document}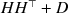 , where H has a prescribed number \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$k<n$$\end{document}
, where H has a prescribed number \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$k<n$$\end{document}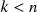 of columns and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$D>0$$\end{document}
of columns and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$D>0$$\end{document}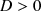 is diagonal. The quality of the approximation is gauged by the I-divergence between the zero mean normal laws with covariances \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{\Sigma }$$\end{document}
is diagonal. The quality of the approximation is gauged by the I-divergence between the zero mean normal laws with covariances \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{\Sigma }$$\end{document}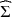 and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$HH^\top +D$$\end{document}
and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$HH^\top +D$$\end{document}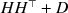 , respectively. To determine a pair (H, D) that minimizes the I-divergence we construct, by lifting the minimization into a larger space, an iterative alternating minimization algorithm (AML) à la Csiszár–Tusnády. As it turns out, the proper choice of the enlarged space is crucial for optimization. The convergence of the algorithm is studied, with special attention given to the case where D is singular. The theoretical properties of the AML are compared to those of the popular EM algorithm for exploratory factor analysis. Inspired by the ECME (a Newton–Raphson variation on EM), we develop a similar variant of AML, called ACML, and in a few numerical experiments, we compare the performances of the four algorithms.
, respectively. To determine a pair (H, D) that minimizes the I-divergence we construct, by lifting the minimization into a larger space, an iterative alternating minimization algorithm (AML) à la Csiszár–Tusnády. As it turns out, the proper choice of the enlarged space is crucial for optimization. The convergence of the algorithm is studied, with special attention given to the case where D is singular. The theoretical properties of the AML are compared to those of the popular EM algorithm for exploratory factor analysis. Inspired by the ECME (a Newton–Raphson variation on EM), we develop a similar variant of AML, called ACML, and in a few numerical experiments, we compare the performances of the four algorithms.
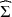
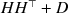
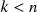
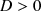
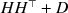
Full Poissonian local statistics of slowly growing sequences
- Part of
-
- Journal:
- Compositio Mathematica / Volume 161 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 24 March 2025, pp. 148-180
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fix
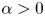 $\alpha >0$. Then by Fejér's theorem
$\alpha >0$. Then by Fejér's theorem 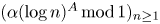 $(\alpha (\log n)^{A}\,\mathrm {mod}\,1)_{n\geq 1}$ is uniformly distributed if and only if
$(\alpha (\log n)^{A}\,\mathrm {mod}\,1)_{n\geq 1}$ is uniformly distributed if and only if 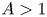 $A>1$. We sharpen this by showing that all correlation functions, and hence the gap distribution, are Poissonian provided
$A>1$. We sharpen this by showing that all correlation functions, and hence the gap distribution, are Poissonian provided 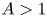 $A>1$. This is the first example of a deterministic sequence modulo
$A>1$. This is the first example of a deterministic sequence modulo 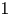 $1$ whose gap distribution and all of whose correlations are proven to be Poissonian. The range of
$1$ whose gap distribution and all of whose correlations are proven to be Poissonian. The range of  $A$ is optimal and complements a result of Marklof and Strömbergsson who found the limiting gap distribution of
$A$ is optimal and complements a result of Marklof and Strömbergsson who found the limiting gap distribution of 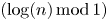 $(\log (n)\, \mathrm {mod}\,1)$, which is necessarily not Poissonian.
$(\log (n)\, \mathrm {mod}\,1)$, which is necessarily not Poissonian.