Refine listing
Actions for selected content:
144876 results in Open Access
Racial Tropes in the Foreign Policy Bureaucracy: A Computational Text Analysis—Corrigendum
-
- Journal:
- International Organization / Volume 79 / Issue 1 / Winter 2025
- Published online by Cambridge University Press:
- 12 March 2025, pp. 193-198
- Print publication:
- Winter 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Longitudinal Analysis of Patient-Reported Outcomes in Clinical Trials: Applications of Multilevel and Multidimensional Item Response Theory
-
- Journal:
- Psychometrika / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 754-777
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Creating Misspecified Models in Moment Structure Analysis
-
- Journal:
- Psychometrika / Volume 84 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 781-801
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
To understand how SEM methods perform in practice where models always have misfit, simulation studies often involve incorrect models. To create a wrong model, traditionally one specifies a perfect model first and then removes some paths. This approach becomes difficult or even impossible to implement in moment structure analysis and fails to control the amounts of misfit separately and precisely for the mean and covariance parts. Most importantly, this approach assumes a perfect model exists and wrong models can eventually be made perfect, whereas in practice models are all implausible if taken literally and at best provide approximations of the real world. To improve the traditional approach, we propose a more realistic and flexible way to create model misfit for multiple group moment structure analysis. Given (a) the model \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\upmu }}} (\cdot ) $$\end{document}
 and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{\Sigma }} (\cdot ) $$\end{document}
and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{\Sigma }} (\cdot ) $$\end{document}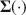 , (b) population model parameters \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\uptheta }}} _0$$\end{document}
, (b) population model parameters \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\uptheta }}} _0$$\end{document}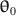 , and (c) \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}
, and (c) \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}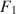 and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}
and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document} specified by the researcher, our method creates \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\upmu }}} ^*$$\end{document}
specified by the researcher, our method creates \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\upmu }}} ^*$$\end{document}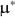 and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{\Sigma }} ^*$$\end{document}
and \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{\Sigma }} ^*$$\end{document}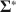 to simultaneously satisfy (a) \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\uptheta }}} _0 = \arg \min F[\varvec{{{\upmu }}} ^*, \varvec{{\Sigma }} ^*; \varvec{{{\upmu }}} (\cdot ), \varvec{{\Sigma }} (\cdot )]$$\end{document}
to simultaneously satisfy (a) \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{{{\uptheta }}} _0 = \arg \min F[\varvec{{{\upmu }}} ^*, \varvec{{\Sigma }} ^*; \varvec{{{\upmu }}} (\cdot ), \varvec{{\Sigma }} (\cdot )]$$\end{document}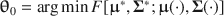 , (b) the mean structure’s misfit equals \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}
, (b) the mean structure’s misfit equals \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}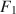 , and (c) the covariance structure’s misfit equals \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}
, and (c) the covariance structure’s misfit equals \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}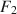 .
.

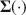
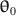
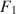

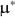
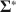
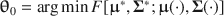
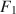
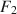
Ideal Point Discriminant Analysis Revisited with a Special Emphasis on Visualization
-
- Journal:
- Psychometrika / Volume 74 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 317-330
-
- Article
-
- You have access
- Open access
- Export citation
Articles with Franciscan Content in The Americas, 1944–2023
-
- Journal:
- The Americas / Volume 82 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 31 January 2025, pp. 113-127
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Solution Strategies and Achievement in Dutch Complex Arithmetic: Latent Variable Modeling of Change
-
- Journal:
- Psychometrika / Volume 74 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 331-350
-
- Article
-
- You have access
- Open access
- Export citation
ARTificial Intelligence: opportunities for art librarians to engage students’ critical thinking with AI image generators
-
- Journal:
- Art Libraries Journal / Volume 50 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 April 2025, pp. 2-5
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lord–Wingersky Algorithm Version 2.5 with Applications
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 973-993
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Accurate Confidence and Bayesian Interval Estimation for Non-centrality Parameters and Effect Size Indices
-
- Journal:
- Psychometrika / Volume 88 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 253-273
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Active Citizens and an Active State: Uncovering the ‘Positive’ Underpinnings of the Australian Constitution
-
- Journal:
- Federal Law Review / Volume 52 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 293-327
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Intra-EU Investment Contract Arbitration after Achmea
-
- Journal:
- International & Comparative Law Quarterly / Volume 74 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 08 May 2025, pp. 225-245
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An Academic Genealogy of Psychometric Society Presidents
-
- Journal:
- Psychometrika / Volume 84 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 562-588
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Advantages of Using Unweighted Approximation Error Measures for Model Fit Assessment
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 413-433
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction to TAM Vault Essays
-
- Journal:
- The Americas / Volume 82 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 24 February 2025, pp. 73-75
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Protein secondary structure determined from independent and integrated infra-red absorbance and circular dichroism data using the algorithm SELCON
- Part of
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 03 February 2025, e10
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Determining the Mental-to-Physical Relationship
-
- Journal:
- Philosophy / Volume 100 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 76-104
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using Threshold Autoregressive Models to Study Dyadic Interactions
-
- Journal:
- Psychometrika / Volume 74 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 727-745
-
- Article
-
- You have access
- Open access
- Export citation
Finite Mixture Multilevel Multidimensional Ordinal IRT Models for Large Scale Cross-Cultural Research
-
- Journal:
- Psychometrika / Volume 75 / Issue 1 / March 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 3-32
-
- Article
-
- You have access
- Open access
- Export citation
Inequalities Between Kappa and Kappa-Like Statistics for k × k Tables
-
- Journal:
- Psychometrika / Volume 75 / Issue 1 / March 2010
- Published online by Cambridge University Press:
- 01 January 2025, pp. 176-185
-
- Article
-
- You have access
- Open access
- Export citation
Measuring strength of altruistic motives
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 595-602
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
