Refine listing
Actions for selected content:
144876 results in Open Access
Item Response Thresholds Models: A General Class of Models for Varying Types of Items
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1238-1269
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Populism and Democracy on the Individual Level: Building on, Yet Moving Beyond the Supply Side
-
- Journal:
- PS: Political Science & Politics / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 15 January 2025, pp. 82-86
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discounting in finite-time bargaining experiments
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 504-518
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Part II: On the Use, the Misuse, and the Very Limited Usefulness of Cronbach’s Alpha: Discussing Lower Bounds and Correlated Errors
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 843-860
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Prior to discussing and challenging two criticisms on coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
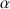 , the well-known lower bound to test-score reliability, we discuss classical test theory and the theory of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
, the well-known lower bound to test-score reliability, we discuss classical test theory and the theory of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}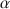 . The first criticism expressed in the psychometrics literature is that coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
. The first criticism expressed in the psychometrics literature is that coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}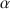 is only useful when the model of essential \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
is only useful when the model of essential \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document} -equivalence is consistent with the item-score data. Because this model is highly restrictive, coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
-equivalence is consistent with the item-score data. Because this model is highly restrictive, coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}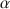 is smaller than test-score reliability and one should not use it. We argue that lower bounds are useful when they assess product quality features, such as a test-score’s reliability. The second criticism expressed is that coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
is smaller than test-score reliability and one should not use it. We argue that lower bounds are useful when they assess product quality features, such as a test-score’s reliability. The second criticism expressed is that coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}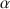 incorrectly ignores correlated errors. If correlated errors would enter the computation of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
incorrectly ignores correlated errors. If correlated errors would enter the computation of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}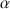 , theoretical values of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
, theoretical values of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}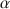 could be greater than the test-score reliability. Because quality measures that are systematically too high are undesirable, critics dismiss coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
could be greater than the test-score reliability. Because quality measures that are systematically too high are undesirable, critics dismiss coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}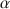 . We argue that introducing correlated errors is inconsistent with the derivation of the lower bound theorem and that the properties of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
. We argue that introducing correlated errors is inconsistent with the derivation of the lower bound theorem and that the properties of coefficient \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}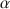 remain intact when data contain correlated errors.
remain intact when data contain correlated errors.

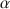
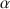
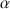
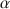
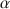
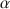
A major victory in the effort to end the online, ornamental trade in bats
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unraveling the nature of physicochemical and biological processes underlying vesicular exocytotic release events through modeling of amperometric current spikes
- Part of
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 24 July 2025, e21
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Use of Behavioral Science in International Law and Policymaking
-
- Journal:
- Proceedings of the ASIL Annual Meeting / Volume 119 / 2025
- Published online by Cambridge University Press:
- 04 February 2026, pp. 25-34
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Internet “piracy” and book sales: a field experiment
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 457-471
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability Beyond Theory and Into Practice
-
- Journal:
- Psychometrika / Volume 74 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 January 2025, pp. 169-173
-
- Article
-
- You have access
- Open access
- Export citation
The Heat is on in the German Bundestag: Coalitions, Conflicts, and Consequences of “Hot Politics”
-
- Journal:
- PS: Political Science & Politics / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 31 January 2025, pp. 110-111
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Traversing Uncharted Territory? The Legislative and Regulatory Landscape of Heritable Human Genome Editing in Australia
-
- Journal:
- Federal Law Review / Volume 52 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 75-102
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the possibility of carbon-free heteropolymers on Venus: a computational astrobiology study
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 25 September 2025, e23
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Objective Bayesian Edge Screening and Structure Selection for Ising Networks
-
- Journal:
- Psychometrika / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 47-82
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Erratum to: Within-Person Variability Score-Based Causal Inference: A Two-Step Estimation for Joint Effects of Time-Varying Treatments
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, p. 1590
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measuring Agreement Using Guessing Models and Knowledge Coefficients
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1002-1025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Several measures of agreement, such as the Perreault–Leigh coefficient, the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textsc {AC}_{1}$$\end{document}
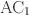 , and the recent coefficient of van Oest, are based on explicit models of how judges make their ratings. To handle such measures of agreement under a common umbrella, we propose a class of models called guessing models, which contains most models of how judges make their ratings. Every guessing model have an associated measure of agreement we call the knowledge coefficient. Under certain assumptions on the guessing models, the knowledge coefficient will be equal to the multi-rater Cohen’s kappa, Fleiss’ kappa, the Brennan–Prediger coefficient, or other less-established measures of agreement. We provide several sample estimators of the knowledge coefficient, valid under varying assumptions, and their asymptotic distributions. After a sensitivity analysis and a simulation study of confidence intervals, we find that the Brennan–Prediger coefficient typically outperforms the others, with much better coverage under unfavorable circumstances.
, and the recent coefficient of van Oest, are based on explicit models of how judges make their ratings. To handle such measures of agreement under a common umbrella, we propose a class of models called guessing models, which contains most models of how judges make their ratings. Every guessing model have an associated measure of agreement we call the knowledge coefficient. Under certain assumptions on the guessing models, the knowledge coefficient will be equal to the multi-rater Cohen’s kappa, Fleiss’ kappa, the Brennan–Prediger coefficient, or other less-established measures of agreement. We provide several sample estimators of the knowledge coefficient, valid under varying assumptions, and their asymptotic distributions. After a sensitivity analysis and a simulation study of confidence intervals, we find that the Brennan–Prediger coefficient typically outperforms the others, with much better coverage under unfavorable circumstances.
On Similarity Coefficients for 2×2 Tables and Correction for Chance
-
- Journal:
- Psychometrika / Volume 73 / Issue 3 / September 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 487-502
-
- Article
-
- You have access
- Open access
- Export citation
An Unreasonable Assumption: A Reply to Strudler
-
- Journal:
- Business Ethics Quarterly / Volume 35 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 27 February 2025, pp. 115-123
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximum Augmented Empirical Likelihood Estimation of Categorical Marginal Models for Large Sparse Contingency Tables
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1228-1248
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sarruma and his skirt of many patterns: Notes on the signs SARMA1–3
-
- Journal:
- Anatolian Studies / Volume 75 / 2025
- Published online by Cambridge University Press:
- 28 August 2025, pp. 47-57
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- Export citation
Sociocognitive and Argumentation Perspectives on Psychometric Modeling in Educational Assessment
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 64-83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
