Refine listing
Actions for selected content:
144895 results in Open Access
Overlapping maritime networks of Patara in the fourth and third centuries BC: Evidence of bronze coinage and transport amphora
-
- Journal:
- Anatolian Studies / Volume 75 / 2025
- Published online by Cambridge University Press:
- 28 August 2025, pp. 125-149
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- Export citation
A Robust Effect Size Index
-
- Journal:
- Psychometrika / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 232-246
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Effect size indices are useful tools in study design and reporting because they are unitless measures of association strength that do not depend on sample size. Existing effect size indices are developed for particular parametric models or population parameters. Here, we propose a robust effect size index based on M-estimators. This approach yields an index that is very generalizable because it is unitless across a wide range of models. We demonstrate that the new index is a function of Cohen’s d, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$R^2$$\end{document}
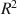 , and standardized log odds ratio when each of the parametric models is correctly specified. We show that existing effect size estimators are biased when the parametric models are incorrect (e.g., under unknown heteroskedasticity). We provide simple formulas to compute power and sample size and use simulations to assess the bias and standard error of the effect size estimator in finite samples. Because the new index is invariant across models, it has the potential to make communication and comprehension of effect size uniform across the behavioral sciences.
, and standardized log odds ratio when each of the parametric models is correctly specified. We show that existing effect size estimators are biased when the parametric models are incorrect (e.g., under unknown heteroskedasticity). We provide simple formulas to compute power and sample size and use simulations to assess the bias and standard error of the effect size estimator in finite samples. Because the new index is invariant across models, it has the potential to make communication and comprehension of effect size uniform across the behavioral sciences.
Populism in Power and Different Models of Democracy
-
- Journal:
- PS: Political Science & Politics / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 January 2025, pp. 87-90
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Frontiers in integrative structural modeling of macromolecular assemblies
- Part of
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 22 January 2025, e3
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Populism and Democracy: Mapping the Field
-
- Journal:
- PS: Political Science & Politics / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 January 2025, pp. 69-71
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Get Over It! A Multilevel Threshold Autoregressive Model for State-Dependent Affect Regulation
-
- Journal:
- Psychometrika / Volume 81 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 01 January 2025, pp. 217-241
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Response-Time-Based Latent Response Mixture Model for Identifying and Modeling Careless and Insufficient Effort Responding in Survey Data
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 593-619
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rejoinder: The Future of Reliability
-
- Journal:
- Psychometrika / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 887-892
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Frontier Pushes Back: From Local Languages to Imperial Substrate(s) in Scribal Practices in 8th-century Central Asia
-
- Journal:
- Iranian Studies / Volume 58 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 03 February 2025, pp. 50-64
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perspectives on Psychometrics Interviews with 20 Past Psychometric Society Presidents
-
- Journal:
- Psychometrika / Volume 86 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 327-343
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
New records of the clouded leopard Neofelis nebulosa in the Qomolangma National Nature Reserve, Tibet
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Flexible Utility Function Approximation via Cubic Bezier Splines
-
- Journal:
- Psychometrika / Volume 85 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 716-737
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Forecasting emotions: exploring the relationship between self-control, affective forecasting, and self-regulatory behavior
-
- Journal:
- Journal of the Economic Science Association / Volume 10 / Issue 2 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 472-484
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Eels: uncertain impacts of proposed CITES listings
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Continuous-Time Dynamic Choice Measurement Model for Problem-Solving Process Data
-
- Journal:
- Psychometrika / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1052-1075
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Dirichlet Dual Response Model: An Item Response Model for Continuous Bounded Interval Responses
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 888-916
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Gibbs Sampler for the (Extended) Marginal Rasch Model
-
- Journal:
- Psychometrika / Volume 80 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 859-879
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The case of the missing antipharos from ancient Patara’s port
-
- Journal:
- Anatolian Studies / Volume 75 / 2025
- Published online by Cambridge University Press:
- 23 April 2025, pp. 151-164
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- Export citation
The Dependence of Chance-Corrected Weighted Agreement Coefficients on the Power Parameter of the Weighting Scheme: Analysis and Measurement
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 554-579
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Association Coefficients for 2×2 Tables and Properties That Do Not Depend on the Marginal Distributions
-
- Journal:
- Psychometrika / Volume 73 / Issue 4 / December 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 777-789
-
- Article
-
- You have access
- Open access
- Export citation
