Refine listing
Actions for selected content:
144895 results in Open Access
Rotation to Sparse Loadings Using Lp\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
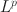 Losses and Related Inference Problems
Losses and Related Inference Problems
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 527-553
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Researchers have widely used exploratory factor analysis (EFA) to learn the latent structure underlying multivariate data. Rotation and regularised estimation are two classes of methods in EFA that they often use to find interpretable loading matrices. In this paper, we propose a new family of oblique rotations based on component-wise \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
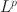 loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}
loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}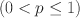 that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}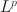 regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
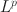
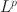
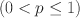
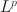
The Assumption of Proportional Components when Candecomp is Applied to Symmetric Matrices in the Context of Indscal
-
- Journal:
- Psychometrika / Volume 73 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 January 2025, pp. 303-307
-
- Article
-
- You have access
- Open access
- Export citation
Lessons from Anti-Poverty Action in Ireland: Flexibility, Failure and the Pitfalls of a ‘Fourth Branch’ Model
-
- Journal:
- Federal Law Review / Volume 51 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 333-346
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Damocles Delusion: The Sense of Power Inflates Threat Perception in World Politics
-
- Journal:
- International Organization / Volume 79 / Issue 1 / Winter 2025
- Published online by Cambridge University Press:
- 12 March 2025, pp. 1-35
- Print publication:
- Winter 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Butcher Medal Lecture
-
- Journal:
- Proceedings of the ASIL Annual Meeting / Volume 119 / 2025
- Published online by Cambridge University Press:
- 04 February 2026, pp. 63-71
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A unified model-implied instrumental variable approach for structural equation modeling with mixed variables
-
- Journal:
- Psychometrika / Volume 86 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 564-594
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ORX volume 59 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Open access
- Export citation
Mark’s Mothers and the Matronymic: Linking ‘The Son of Mary’ (Mk 6.3) to ‘The Daughter of Herodias’ (Mk 6.22)
-
- Journal:
- New Testament Studies / Volume 71 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 07 August 2025, pp. 92-104
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Does Democracy Exist?
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Longitudinal Modeling of Age-Dependent Latent Traits with Generalized Additive Latent and Mixed Models
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 456-486
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Note on Ising Network Analysis with Missing Data
-
- Journal:
- Psychometrika / Volume 89 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1186-1202
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factor Tree Copula Models for Item Response Data
-
- Journal:
- Psychometrika / Volume 88 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 776-802
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Art library collections at research universities: IDBEA in collection development
-
- Journal:
- Art Libraries Journal / Volume 50 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 April 2025, pp. 33-40
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
First density estimates of the Endangered Claire's mouse lemur Microcebus mamiratra and recommendations for its conservation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Commonwealth Power to Improve Access, Quality, and Efficiency of Medical Care: Does section 51 (xxiiiA) of the Constitution Limit Politically Feasible Health Policy Options Today?
-
- Journal:
- Federal Law Review / Volume 51 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 232-256
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ivory Towers and Concrete Flowers: On the Relationship between Political Philosophy and Activism
-
- Journal:
- Philosophy / Volume 100 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 50-75
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Note on the Usefulness of Constrained Fourth-Order Latent Differential Equation Models in the Case of Small T
-
- Journal:
- Psychometrika / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1016-1027
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Structural Equation Models: From Paths to Networks (Westland 2019)
-
- Journal:
- Psychometrika / Volume 85 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 841-844
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Two-Step Estimator for Multilevel Latent Class Analysis with Covariates
-
- Journal:
- Psychometrika / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1144-1170
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Export Controls and the Green Agenda in the European Union
-
- Journal:
- International & Comparative Law Quarterly / Volume 74 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 April 2025, pp. 205-224
- Print publication:
- January 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
