Refine search
Actions for selected content:
525 results
3 - Class: stratification and disparity
-
- Book:
- An Introduction to Japanese Society
- Print publication:
- 31 July 2026, pp 58-81
-
- Chapter
- Export citation
6 - Selection
- from Part II - Efficiency, Competence and Geographic Diversity
-
- Book:
- Employment Law at International Organizations
- Print publication:
- 23 July 2026, pp 81-98
-
- Chapter
- Export citation
Chapter 32 - Versions of Disorders We Aspire to Explain
- from Section 11
-
-
- Book:
- Causal Concepts in Psychopathology
- Published online:
- 11 May 2026
- Print publication:
- 16 July 2026, pp 349-366
-
- Chapter
- Export citation
Chapter 23 - Mechanism Matters
- from Section 8
-
-
- Book:
- Causal Concepts in Psychopathology
- Published online:
- 11 May 2026
- Print publication:
- 16 July 2026, pp 240-274
-
- Chapter
- Export citation
13 - Genres Local and Global
- from Part IV - Culture and Aesthetics
-
-
- Book:
- The Cambridge Companion to Romanticism and World Literature
- Published online:
- 11 June 2026
- Print publication:
- 02 July 2026, pp 229-244
-
- Chapter
- Export citation
8 - All in the Family
-
- Book:
- The Secret History of Language
- Published online:
- 28 May 2026
- Print publication:
- 18 June 2026, pp 115-137
-
- Chapter
- Export citation
3 - Strong Regularity
-
- Book:
- Spectra of Signed Graphs
- Published online:
- 15 May 2026
- Print publication:
- 11 June 2026, pp 64-94
-
- Chapter
- Export citation
9 - Classification
-
- Book:
- All of Regression
- Published online:
- 08 May 2026
- Print publication:
- 04 June 2026, pp 117-138
-
- Chapter
- Export citation
Functional neurological symptoms occur commonly in healthy adults: implications for the pathophysiology of FND
-
- Journal:
- CNS Spectrums / Volume 31 / Issue 1 / 2026
- Published online by Cambridge University Press:
- 20 May 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The DSM needs more than revision: five blind spots and a case for dialogical redesign
-
- Journal:
- Psychological Medicine / Volume 56 / 2026
- Published online by Cambridge University Press:
- 14 May 2026, e153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
10 - Large Language Models
- from Part II - Data and Methods
-
-
- Book:
- Empirical Legal Studies in EU Law
- Published online:
- 08 April 2026
- Print publication:
- 07 May 2026, pp 209-223
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Chapter 8 - Bias in the Study Conduct
-
- Book:
- Bias!
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 68-78
-
- Chapter
- Export citation
Frabjous: Deep learning Fast Radio Burst morphologies
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 43 / 2026
- Published online by Cambridge University Press:
- 22 April 2026, e062
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CLASSIFICATION COMPLEXITY OF CHAOTIC SYSTEMS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 17 April 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this article, we deal with the classification complexity of continuous (Devaney) chaotic systems in dimensions
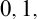 $0,1,$ and
$0,1,$ and 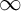 $\infty $ using the framework of invariant descriptive set theory. We identify the complexity in dimensions
$\infty $ using the framework of invariant descriptive set theory. We identify the complexity in dimensions 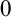 $0$ and
$0$ and 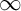 $\infty $, while in dimension
$\infty $, while in dimension 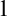 $1$ we get some partial results.
$1$ we get some partial results.More precisely, we prove the topological conjugacy relation of invertible chaotic systems on the Hilbert cube (resp. on all compact metric spaces) has the same complexity as (i.e., is Borel bireducible with) the universal orbit relation induced by a Polish group. As a consequence, this answers a recent question asked by L. Ding. We also prove that the topological conjugacy relation of invertible chaotic systems on the Cantor space has the same complexity as the universal relation induced by the group
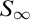 $S_\infty $. This answers a recent question by M. Foreman. Some non-trivial bounds on the classification complexity of chaotic systems on the interval and on the circle are also obtained. Namely, the lower bound is the Vitali equivalence relation, and the upper bound is the equality of countable sets of reals. This especially implies that the relation is Borel. However, the exact complexity remains unknown.
$S_\infty $. This answers a recent question by M. Foreman. Some non-trivial bounds on the classification complexity of chaotic systems on the interval and on the circle are also obtained. Namely, the lower bound is the Vitali equivalence relation, and the upper bound is the equality of countable sets of reals. This especially implies that the relation is Borel. However, the exact complexity remains unknown.
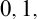
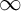
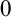
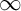
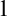
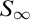
2 - Mapping Ethnic Territory
-
- Book:
- Knowing Ethnicity
- Published online:
- 02 March 2026
- Print publication:
- 09 April 2026, pp 60-105
-
- Chapter
- Export citation
24 - Notes on Teaching Concept Analysis
- from Part VI - Teaching
-
-
- Book:
- Working with Concepts
- Published online:
- 22 April 2026
- Print publication:
- 09 April 2026, pp 465-472
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Conclusion
-
- Book:
- Knowing Ethnicity
- Published online:
- 02 March 2026
- Print publication:
- 09 April 2026, pp 193-205
-
- Chapter
- Export citation
25 - Conclusion
- from Part VII - Conclusion
-
-
- Book:
- Working with Concepts
- Published online:
- 22 April 2026
- Print publication:
- 09 April 2026, pp 475-482
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Introduction
-
- Book:
- Knowing Ethnicity
- Published online:
- 02 March 2026
- Print publication:
- 09 April 2026, pp 1-21
-
- Chapter
- Export citation
Interpretation and Characterisation of Contracts in the New Belgian Civil Code
-
- Journal:
- Cambridge Yearbook of European Legal Studies , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
