Refine search
Actions for selected content:
6974 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
6 - Polynomial Selection for the Number Field Sieve
-
-
- Book:
- Topics in Computational Number Theory Inspired by Peter L. Montgomery
- Published online:
- 25 October 2017
- Print publication:
- 12 October 2017, pp 161-174
-
- Chapter
- Export citation

Complex Networks
- Principles, Methods and Applications
-
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017
On Edge-Disjoint Spanning Trees in a Randomly Weighted Complete Graph
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 2 / March 2018
- Published online by Cambridge University Press:
- 09 October 2017, pp. 228-244
-
- Article
- Export citation
Uniformly Discrete Forests with Poor Visibility
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 09 October 2017, pp. 442-448
-
- Article
-
- You have access
- Export citation
Colourings of Uniform Hypergraphs with Large Girth and Applications
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 2 / March 2018
- Published online by Cambridge University Press:
- 09 October 2017, pp. 245-273
-
- Article
- Export citation
-
This paper deals with a combinatorial problem concerning colourings of uniform hypergraphs with large girth. We prove that if H is an n-uniform non-r-colourable simple hypergraph then its maximum edge degree Δ(H) satisfies the inequality
for some absolute constant c > 0.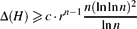 $$\Delta(H)\geqslant c\cdot r^{n-1}\ffrac{n(\ln\ln n)^2}{\ln n}$$
$$\Delta(H)\geqslant c\cdot r^{n-1}\ffrac{n(\ln\ln n)^2}{\ln n}$$ As an application of our probabilistic technique we establish a lower bound for the classical van der Waerden number W(n, r), the minimum natural N such that in an arbitrary colouring of the set of integers {1,. . .,N} with r colours there exists a monochromatic arithmetic progression of length n. We prove that
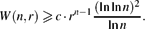 $$W(n,r)\geqslant c\cdot r^{n-1}\ffrac{(\ln\ln n)^2}{\ln n}.$$
$$W(n,r)\geqslant c\cdot r^{n-1}\ffrac{(\ln\ln n)^2}{\ln n}.$$
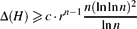
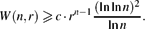
A Simple SVD Algorithm for Finding Hidden Partitions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 1 / January 2018
- Published online by Cambridge University Press:
- 09 October 2017, pp. 124-140
-
- Article
- Export citation

Geometry and Complexity Theory
-
- Published online:
- 03 October 2017
- Print publication:
- 28 September 2017
Epigraph
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp xxiii-xxiv
-
- Chapter
- Export citation
9 - The Chow Variety of Products of Linear Forms
-
- Book:
- Geometry and Complexity Theory
- Published online:
- 03 October 2017
- Print publication:
- 28 September 2017, pp 264-288
-
- Chapter
- Export citation
2 - The Complexity of Matrix Multiplication I: First Lower Bounds
-
- Book:
- Geometry and Complexity Theory
- Published online:
- 03 October 2017
- Print publication:
- 28 September 2017, pp 18-44
-
- Chapter
- Export citation
2 - Centrality Measures
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 31-68
-
- Chapter
- Export citation
3 - The Complexity of Matrix Multiplication II: Asymptotic Upper Bounds
-
- Book:
- Geometry and Complexity Theory
- Published online:
- 03 October 2017
- Print publication:
- 28 September 2017, pp 45-76
-
- Chapter
- Export citation
5 - The Complexity of Matrix Multiplication IV: The Complexity of Tensors and More Lower Bounds
-
- Book:
- Geometry and Complexity Theory
- Published online:
- 03 October 2017
- Print publication:
- 28 September 2017, pp 104-143
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp xi-xi
-
- Chapter
- Export citation
Bisections of Graphs Without Short Cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 1 / January 2018
- Published online by Cambridge University Press:
- 28 September 2017, pp. 44-59
-
- Article
- Export citation
4 - Small-World Networks
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 107-150
-
- Chapter
- Export citation
References
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 535-549
-
- Chapter
- Export citation
10 - Weighted Networks
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 374-409
-
- Chapter
- Export citation
7 - Degree Correlations
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 257-293
-
- Chapter
- Export citation
5 - Generalised Random Graphs
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 151-205
-
- Chapter
- Export citation
