Refine search
Actions for selected content:
6974 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Saturation in the Hypercube and Bootstrap Percolation
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 31 March 2016, pp. 78-98
-
- Article
- Export citation
Adding Edges to Increase the Chromatic Number of a Graph
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 31 March 2016, pp. 592-594
-
- Article
- Export citation
-
If n ⩾ k + 1 and G is a connected n-vertex graph, then one can add
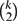 $\binom{k}{2}$ edges to G so that the resulting graph contains the complete graph K k+1. This yields that for any connected graph G with at least k + 1 vertices, one can add $\binom{k}{2}$ edges to G so that the resulting graph has chromatic number > k. A long time ago, Bollobás suggested that for every k ⩾ 3 there exists a k-chromatic graph Gk such that after adding to it any $\binom{k}{2}$ − 1 edges, the chromatic number of the resulting graph is still k. In this note we prove this conjecture.
$\binom{k}{2}$ edges to G so that the resulting graph contains the complete graph K k+1. This yields that for any connected graph G with at least k + 1 vertices, one can add $\binom{k}{2}$ edges to G so that the resulting graph has chromatic number > k. A long time ago, Bollobás suggested that for every k ⩾ 3 there exists a k-chromatic graph Gk such that after adding to it any $\binom{k}{2}$ − 1 edges, the chromatic number of the resulting graph is still k. In this note we prove this conjecture.
A Convexity Property of Discrete Random Walks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 31 March 2016, pp. 928-940
-
- Article
- Export citation
-
We establish a convexity property for the hitting probabilities of discrete random walks in
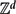 ${\mathbb Z}^d$ (discrete harmonic measures). For d = 2 this implies a recent result on the convexity of the density of certain harmonic measures.
${\mathbb Z}^d$ (discrete harmonic measures). For d = 2 this implies a recent result on the convexity of the density of certain harmonic measures.
Multivariate Eulerian Polynomials and Exclusion Processes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 18 March 2016, pp. 486-499
-
- Article
- Export citation
Marstrand-type Theorems for the Counting and Mass Dimensions in ℤ
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 16 March 2016, pp. 700-743
-
- Article
- Export citation
-
The counting and (upper) mass dimensions of a set A ⊆
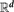 $\mathbb{R}^d$ arewhere ⌊A⌋ denotes the set of elements of A rounded down in each coordinate and where the limit supremum in the counting dimension is taken over cubes C ⊆
$\mathbb{R}^d$ arewhere ⌊A⌋ denotes the set of elements of A rounded down in each coordinate and where the limit supremum in the counting dimension is taken over cubes C ⊆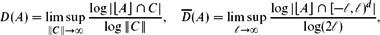 $$D(A) = \limsup_{\|C\| \to \infty} \frac{\log | \lfloor A \rfloor \cap C |}{\log \|C\|}, \quad \smash{\overline{D}}\vphantom{D}(A) = \limsup_{\ell \to \infty} \frac{\log | \lfloor A \rfloor \cap [-\ell,\ell)^d |}{\log (2 \ell)},$$ $\mathbb{R}^d$ with side length ‖C‖ → ∞. We give a characterization of the counting dimension via coverings:where
$$D(A) = \limsup_{\|C\| \to \infty} \frac{\log | \lfloor A \rfloor \cap C |}{\log \|C\|}, \quad \smash{\overline{D}}\vphantom{D}(A) = \limsup_{\ell \to \infty} \frac{\log | \lfloor A \rfloor \cap [-\ell,\ell)^d |}{\log (2 \ell)},$$ $\mathbb{R}^d$ with side length ‖C‖ → ∞. We give a characterization of the counting dimension via coverings:where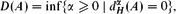 $$D(A) = \text{inf} \{ \alpha \geq 0 \mid {d_{H}^{\alpha}}(A) = 0 \},$$in which the infimum is taken over cubic coverings {Ci } of A ∩ C. Then we prove Marstrand-type theorems for both dimensions. For example, almost all images of A ⊆
$$D(A) = \text{inf} \{ \alpha \geq 0 \mid {d_{H}^{\alpha}}(A) = 0 \},$$in which the infimum is taken over cubic coverings {Ci } of A ∩ C. Then we prove Marstrand-type theorems for both dimensions. For example, almost all images of A ⊆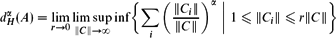 $${d_{H}^{\alpha}}(A) = \lim_{r \rightarrow 0} \limsup_{\|C\| \rightarrow \infty} \inf \biggl\{ \sum_i \biggl(\frac{\|C_i\|}{\|C\|} \biggr)^\alpha\ \bigg| \1 \leq \|C_i\| \leq r \|C\| \biggr\}$$ $\mathbb{R}^d$ under orthogonal projections with range of dimension k have counting dimension at least min(k, D(A)); if we assume D(A) = D (A), then the mass dimension of A under the typical orthogonal projection is equal to min(k, D(A)). This work extends recent work of Y. Lima and C. G. Moreira.
$${d_{H}^{\alpha}}(A) = \lim_{r \rightarrow 0} \limsup_{\|C\| \rightarrow \infty} \inf \biggl\{ \sum_i \biggl(\frac{\|C_i\|}{\|C\|} \biggr)^\alpha\ \bigg| \1 \leq \|C_i\| \leq r \|C\| \biggr\}$$ $\mathbb{R}^d$ under orthogonal projections with range of dimension k have counting dimension at least min(k, D(A)); if we assume D(A) = D (A), then the mass dimension of A under the typical orthogonal projection is equal to min(k, D(A)). This work extends recent work of Y. Lima and C. G. Moreira.
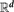
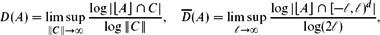
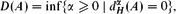
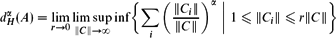
Tuza's Conjecture is Asymptotically Tight for Dense Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 14 March 2016, pp. 645-667
-
- Article
- Export citation
Cycles and Matchings in Randomly Perturbed Digraphs and Hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 14 March 2016, pp. 909-927
-
- Article
- Export citation
Comments on Y. O. Hamidoune's Paper ‘Adding Distinct Congruence Classes’
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 09 March 2016, pp. 641-644
-
- Article
- Export citation
Improved Bounds for the Ramsey Number of Tight Cycles Versus Cliques
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 08 March 2016, pp. 791-796
-
- Article
- Export citation
-
The 3-uniform tight cycle Cs 3 has vertex set
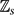 ${\mathbb Z}_s$ and edge set {{i, i + 1, i + 2}: i ∈ ${\mathbb Z}_s$ }. We prove that for every s ≢ 0 (mod 3) with s ⩾ 16 or s ∈ {8, 11, 14} there is a cs > 0 such that the 3-uniform hypergraph Ramsey number r(Cs 3, Kn 3) satisfiesThis answers in a strong form a question of the author and Rödl, who asked for an upper bound of the form
${\mathbb Z}_s$ and edge set {{i, i + 1, i + 2}: i ∈ ${\mathbb Z}_s$ }. We prove that for every s ≢ 0 (mod 3) with s ⩾ 16 or s ∈ {8, 11, 14} there is a cs > 0 such that the 3-uniform hypergraph Ramsey number r(Cs 3, Kn 3) satisfiesThis answers in a strong form a question of the author and Rödl, who asked for an upper bound of the form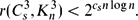 $$\begin{equation*}r(C_s^3, K_n^3)< 2^{c_s n \log n}.\\end{equation*}$$
$$\begin{equation*}r(C_s^3, K_n^3)< 2^{c_s n \log n}.\\end{equation*}$$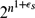 $2^{n^{1+\epsilon_s}}$ for each fixed s ⩾ 4, where εs → 0 as s → ∞ and n is sufficiently large. The result is nearly tight as the lower bound is known to be exponential in n.
$2^{n^{1+\epsilon_s}}$ for each fixed s ⩾ 4, where εs → 0 as s → ∞ and n is sufficiently large. The result is nearly tight as the lower bound is known to be exponential in n.
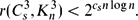
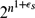
On the Normalized Shannon Capacity of a Union
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 03 March 2016, pp. 766-767
-
- Article
- Export citation
-
Let G 1 × G 2 denote the strong product of graphs G 1 and G 2, that is, the graph on V(G 1) × V(G 2) in which (u 1, u 2) and (v 1, v 2) are adjacent if for each i = 1, 2 we have ui = vi or u i v i ∈ E(G i ). The Shannon capacity of G is c(G) = limn → ∞ α(Gn )1/n , where Gn denotes the n-fold strong power of G, and α(H) denotes the independence number of a graph H. The normalized Shannon capacity of G is
Alon [1] asked whether for every ε < 0 there are graphs G and G′ satisfying C(G), C(G′) < ε but with C(G + G′) > 1 − ε. We show that the answer is no.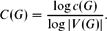 $$C(G) = \ffrac {\log c(G)}{\log |V(G)|}.$$
$$C(G) = \ffrac {\log c(G)}{\log |V(G)|}.$$
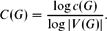
Coexistence in Preferential Attachment Networks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 09 February 2016, pp. 797-822
-
- Article
- Export citation
10 - Ranking Methods
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 563-616
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp xiii-xviii
-
- Chapter
- Export citation
9 - Rating Systems
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 501-562
-
- Chapter
- Export citation
4 - Smooth Allocation of Prizes
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 157-222
-
- Chapter
- Export citation
7 - Sequential Contests
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 359-442
-
- Chapter
- Export citation
Index
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 713-717
-
- Chapter
- Export citation
2 - Standard All-Pay Contest
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 41-94
-
- Chapter
- Export citation
11 - Appendix
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 617-680
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp i-iv
-
- Chapter
- Export citation
