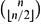Refine search
Actions for selected content:
6974 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
6 - Utility Sharing and Welfare
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 301-358
-
- Chapter
- Export citation
5 - Simultaneous Contests
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 223-300
-
- Chapter
- Export citation
References
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 681-708
-
- Chapter
- Export citation
1 - Introduction and Preview
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 1-40
-
- Chapter
- Export citation
8 - Tournaments
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 443-500
-
- Chapter
- Export citation
Contents
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp v-xii
-
- Chapter
- Export citation
3 - Rank-Order Allocation of Prizes
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 95-156
-
- Chapter
- Export citation
Index to Notations
-
- Book:
- Contest Theory
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016, pp 709-712
-
- Chapter
- Export citation
Inapproximability of the Partition Function for the Antiferromagnetic Ising and Hard-Core Models
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 02 February 2016, pp. 500-559
-
- Article
- Export citation
-
Recent inapproximability results of Sly (2010), together with an approximation algorithm presented by Weitz (2006), establish a beautiful picture of the computational complexity of approximating the partition function of the hard-core model. Let λc (
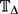 $\mathbb{T}_{\Delta}$ ) denote the critical activity for the hard-model on the infinite Δ-regular tree. Weitz presented an FPTAS for the partition function when λ < λc ( $\mathbb{T}_{\Delta}$ ) for graphs with constant maximum degree Δ. In contrast, Sly showed that for all Δ ⩾ 3, there exists εΔ > 0 such that (unless RP = NP) there is no FPRAS for approximating the partition function on graphs of maximum degree Δ for activities λ satisfying λc ( $\mathbb{T}_{\Delta}$ ) < λ < λc ( $\mathbb{T}_{\Delta}$ ) + εΔ.
$\mathbb{T}_{\Delta}$ ) denote the critical activity for the hard-model on the infinite Δ-regular tree. Weitz presented an FPTAS for the partition function when λ < λc ( $\mathbb{T}_{\Delta}$ ) for graphs with constant maximum degree Δ. In contrast, Sly showed that for all Δ ⩾ 3, there exists εΔ > 0 such that (unless RP = NP) there is no FPRAS for approximating the partition function on graphs of maximum degree Δ for activities λ satisfying λc ( $\mathbb{T}_{\Delta}$ ) < λ < λc ( $\mathbb{T}_{\Delta}$ ) + εΔ.We prove that a similar phenomenon holds for the antiferromagnetic Ising model. Sinclair, Srivastava and Thurley (2014) extended Weitz's approach to the antiferromagnetic Ising model, yielding an FPTAS for the partition function for all graphs of constant maximum degree Δ when the parameters of the model lie in the uniqueness region of the infinite Δ-regular tree. We prove the complementary result for the antiferromagnetic Ising model without external field, namely, that unless RP = NP, for all Δ ⩾ 3, there is no FPRAS for approximating the partition function on graphs of maximum degree Δ when the inverse temperature lies in the non-uniqueness region of the infinite tree
$\mathbb{T}_{\Delta}$ . Our proof works by relating certain second moment calculations for random Δ-regular bipartite graphs to the tree recursions used to establish the critical points on the infinite tree.
Nearly Optimal Bernoulli Factories for Linear Functions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 01 February 2016, pp. 577-591
-
- Article
- Export citation
-
Suppose that X 1, X 2, . . . are independent identically distributed Bernoulli random variables with mean p. A Bernoulli factory for a function f takes as input X 1, X 2, . . . and outputs a random variable that is Bernoulli with mean f(p). A fast algorithm is a function that only depends on the values of X 1, . . ., XT , where T is a stopping time with small mean. When f(p) is a real analytic function the problem reduces to being able to draw from linear functions Cp for a constant C > 1. Also it is necessary that Cp ⩽ 1 − ε for known ε > 0. Previous methods for this problem required extensive modification of the algorithm for every value of C and ε. These methods did not have explicit bounds on
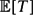 $\mathbb{E}[T]$ as a function of C and ε. This paper presents the first Bernoulli factory for f(p) = Cp with bounds on $\mathbb{E}[T]$ as a function of the input parameters. In fact, supp∈[0,(1−ε)/C] $\mathbb{E}[T]$ ≤ 9.5ε−1 C. In addition, this method is very simple to implement. Furthermore, a lower bound on the average running time of any Cp Bernoulli factory is shown. For ε ⩽ 1/2, supp∈[0,(1−ε)/C] $\mathbb{E}[T]$ ≥0.004Cε−1, so the new method is optimal up to a constant in the running time.
$\mathbb{E}[T]$ as a function of C and ε. This paper presents the first Bernoulli factory for f(p) = Cp with bounds on $\mathbb{E}[T]$ as a function of the input parameters. In fact, supp∈[0,(1−ε)/C] $\mathbb{E}[T]$ ≤ 9.5ε−1 C. In addition, this method is very simple to implement. Furthermore, a lower bound on the average running time of any Cp Bernoulli factory is shown. For ε ⩽ 1/2, supp∈[0,(1−ε)/C] $\mathbb{E}[T]$ ≥0.004Cε−1, so the new method is optimal up to a constant in the running time.
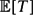
Probabilistic Divide-and-Conquer: A New Exact Simulation Method, With Integer Partitions as an Example
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 3 / May 2016
- Published online by Cambridge University Press:
- 22 January 2016, pp. 324-351
-
- Article
- Export citation
Minimum Degrees and Codegrees of Ramsey-Minimal 3-Uniform Hypergraphs* †
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 20 January 2016, pp. 850-869
-
- Article
- Export citation
The Inversion Number and the Major Index are Asymptotically Jointly Normally Distributed on Words
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 3 / May 2016
- Published online by Cambridge University Press:
- 14 January 2016, pp. 470-483
-
- Article
- Export citation

Contest Theory
- Incentive Mechanisms and Ranking Methods
-
- Published online:
- 05 January 2016
- Print publication:
- 04 February 2016
Counting Connected Hypergraphs via the Probabilistic Method
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 04 January 2016, pp. 21-75
-
- Article
- Export citation
Decomposition of Multiple Packings with Subquadratic Union Complexity
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 04 January 2016, pp. 145-153
-
- Article
- Export citation
-
Suppose k is a positive integer and
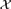 ${\cal X}$ is a k-fold packing of the plane by infinitely many arc-connected compact sets, which means that every point of the plane belongs to at most k sets. Suppose there is a function f(n) = o(n2) with the property that any n members of ${\cal X}$ determine at most f(n) holes, which means that the complement of their union has at most f(n) bounded connected components. We use tools from extremal graph theory and the topological Helly theorem to prove that ${\cal X}$ can be decomposed into at most p (1-fold) packings, where p is a constant depending only on k and f.
${\cal X}$ is a k-fold packing of the plane by infinitely many arc-connected compact sets, which means that every point of the plane belongs to at most k sets. Suppose there is a function f(n) = o(n2) with the property that any n members of ${\cal X}$ determine at most f(n) holes, which means that the complement of their union has at most f(n) bounded connected components. We use tools from extremal graph theory and the topological Helly theorem to prove that ${\cal X}$ can be decomposed into at most p (1-fold) packings, where p is a constant depending only on k and f.
On Active and Passive Testing
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 04 January 2016, pp. 1-20
-
- Article
- Export citation
-
Given a property of Boolean functions, what is the minimum number of queries required to determine with high probability if an input function satisfies this property or is ‘far’ from satisfying it? This is a fundamental question in property testing, where traditionally the testing algorithm is allowed to pick its queries among the entire set of inputs. Balcan, Blais, Blum and Yang have recently suggested restricting the tester to take its queries from a smaller random subset of polynomial size of the inputs. This model is called active testing, and in the extreme case when the size of the set we can query from is exactly the number of queries performed, it is known as passive testing.
We prove that passive or active testing of k-linear functions (that is, sums of k variables among n over
 $\mathbb{Z}$2) requires Θ(k log n) queries, assuming k is not too large. This extends the case k = 1, (that is, dictator functions), analysed by Balcan, Blais, Blum and Yang.
$\mathbb{Z}$2) requires Θ(k log n) queries, assuming k is not too large. This extends the case k = 1, (that is, dictator functions), analysed by Balcan, Blais, Blum and Yang.We also consider other classes of functions including low-degree polynomials, juntas, and partially symmetric functions. Our methods combine algebraic, combinatorial, and probabilistic techniques, including the Talagrand concentration inequality and the Erdős–Rado theorem on Δ-systems.

The Multiple-Orientability Thresholds for Random Hypergraphs†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 28 December 2015, pp. 870-908
-
- Article
- Export citation
Manipulative Waiters with Probabilistic Intuition
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 21 December 2015, pp. 823-849
-
- Article
- Export citation
-
For positive integers n and q and a monotone graph property
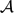 $\mathcal{A}$ , we consider the two-player, perfect information game WC(n, q, $\mathcal{A}$ ), which is defined as follows. The game proceeds in rounds. In each round, the first player, called Waiter, offers the second player, called Client, q + 1 edges of the complete graph Kn which have not been offered previously. Client then chooses one of these edges which he keeps and the remaining q edges go back to Waiter. If, at the end of the game, the graph which consists of the edges chosen by Client satisfies the property $\mathcal{A}$ , then Waiter is declared the winner; otherwise Client wins the game. In this paper we study such games (also known as Picker–Chooser games) for a variety of natural graph-theoretic parameters, such as the size of a largest component or the length of a longest cycle. In particular, we describe a phase transition type phenomenon which occurs when the parameter q is close to n and is reminiscent of phase transition phenomena in random graphs. Namely, we prove that if q ⩾ (1 + ϵ)n, then Client can avoid components of order cϵ−2 ln n for some absolute constant c > 0, whereas for q ⩽ (1 − ϵ)n, Waiter can force a giant, linearly sized component in Client's graph. In the second part of the paper, we prove that Waiter can force Client's graph to be pancyclic for every q ⩽ cn, where c > 0 is an appropriate constant. Note that this behaviour is in stark contrast to the threshold for pancyclicity and Hamiltonicity of random graphs.
$\mathcal{A}$ , we consider the two-player, perfect information game WC(n, q, $\mathcal{A}$ ), which is defined as follows. The game proceeds in rounds. In each round, the first player, called Waiter, offers the second player, called Client, q + 1 edges of the complete graph Kn which have not been offered previously. Client then chooses one of these edges which he keeps and the remaining q edges go back to Waiter. If, at the end of the game, the graph which consists of the edges chosen by Client satisfies the property $\mathcal{A}$ , then Waiter is declared the winner; otherwise Client wins the game. In this paper we study such games (also known as Picker–Chooser games) for a variety of natural graph-theoretic parameters, such as the size of a largest component or the length of a longest cycle. In particular, we describe a phase transition type phenomenon which occurs when the parameter q is close to n and is reminiscent of phase transition phenomena in random graphs. Namely, we prove that if q ⩾ (1 + ϵ)n, then Client can avoid components of order cϵ−2 ln n for some absolute constant c > 0, whereas for q ⩽ (1 − ϵ)n, Waiter can force a giant, linearly sized component in Client's graph. In the second part of the paper, we prove that Waiter can force Client's graph to be pancyclic for every q ⩽ cn, where c > 0 is an appropriate constant. Note that this behaviour is in stark contrast to the threshold for pancyclicity and Hamiltonicity of random graphs.
Local Maxima of Quadratic Boolean Functions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 21 December 2015, pp. 633-640
-
- Article
- Export citation
-
How many strict local maxima can a real quadratic function on {0, 1}n have? Holzman conjectured a maximum of
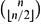 $\binom{n }{ \lfloor n/2 \rfloor}$ . The aim of this paper is to prove this conjecture. Our approach is via a generalization of Sperner's theorem that may be of independent interest.
$\binom{n }{ \lfloor n/2 \rfloor}$ . The aim of this paper is to prove this conjecture. Our approach is via a generalization of Sperner's theorem that may be of independent interest.