Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
3 - Primal-Dual Splitting Methods
- from Part One: - Monotone OPerator Methods
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp 66-93
-
- Chapter
- Export citation
Index
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp 299-304
-
- Chapter
- Export citation
4 - Parallel Computing
- from Part One: - Monotone OPerator Methods
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp 94-104
-
- Chapter
- Export citation
9 - Duality in Splitting Methods
- from Part Two: - Additional Topics
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp 190-196
-
- Chapter
- Export citation
Dedication
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp v-vi
-
- Chapter
- Export citation
Part Two: - Additional Topics
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp 145-146
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Large-Scale Convex Optimization
- Published online:
- 12 December 2022
- Print publication:
- 01 December 2022, pp i-iv
-
- Chapter
- Export citation
On random walks and switched random walks on homogeneous spaces
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 28 November 2022, pp. 398-421
-
- Article
- Export citation
-
We prove new mixing rate estimates for the random walks on homogeneous spaces determined by a probability distribution on a finite group
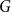 $G$. We introduce the switched random walk determined by a finite set of probability distributions on
$G$. We introduce the switched random walk determined by a finite set of probability distributions on 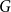 $G$, prove that its long-term behaviour is determined by the Fourier joint spectral radius of the distributions, and give Hermitian sum-of-squares algorithms for the effective estimation of this quantity.
$G$, prove that its long-term behaviour is determined by the Fourier joint spectral radius of the distributions, and give Hermitian sum-of-squares algorithms for the effective estimation of this quantity.
Supercritical site percolation on the hypercube: small components are small
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 25 November 2022, pp. 422-427
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider supercritical site percolation on the
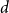 $d$-dimensional hypercube
$d$-dimensional hypercube 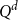 $Q^d$. We show that typically all components in the percolated hypercube, besides the giant, are of size
$Q^d$. We show that typically all components in the percolated hypercube, besides the giant, are of size 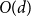 $O(d)$. This resolves a conjecture of Bollobás, Kohayakawa, and Łuczak from 1994.
$O(d)$. This resolves a conjecture of Bollobás, Kohayakawa, and Łuczak from 1994.
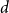
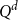
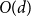
New upper bounds for the Erdős-Gyárfás problem on generalized Ramsey numbers
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 24 November 2022, pp. 349-362
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A
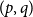 $(p,q)$-colouring of a graph
$(p,q)$-colouring of a graph 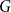 $G$ is an edge-colouring of
$G$ is an edge-colouring of 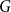 $G$ which assigns at least
$G$ which assigns at least 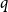 $q$ colours to each
$q$ colours to each 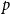 $p$-clique. The problem of determining the minimum number of colours,
$p$-clique. The problem of determining the minimum number of colours, 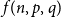 $f(n,p,q)$, needed to give a
$f(n,p,q)$, needed to give a 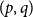 $(p,q)$-colouring of the complete graph
$(p,q)$-colouring of the complete graph 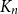 $K_n$ is a natural generalization of the well-known problem of identifying the diagonal Ramsey numbers
$K_n$ is a natural generalization of the well-known problem of identifying the diagonal Ramsey numbers 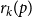 $r_k(p)$. The best-known general upper bound on
$r_k(p)$. The best-known general upper bound on 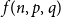 $f(n,p,q)$ was given by Erdős and Gyárfás in 1997 using a probabilistic argument. Since then, improved bounds in the cases where
$f(n,p,q)$ was given by Erdős and Gyárfás in 1997 using a probabilistic argument. Since then, improved bounds in the cases where 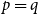 $p=q$ have been obtained only for
$p=q$ have been obtained only for 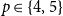 $p\in \{4,5\}$, each of which was proved by giving a deterministic construction which combined a
$p\in \{4,5\}$, each of which was proved by giving a deterministic construction which combined a 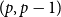 $(p,p-1)$-colouring using few colours with an algebraic colouring.
$(p,p-1)$-colouring using few colours with an algebraic colouring.In this paper, we provide a framework for proving new upper bounds on
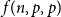 $f(n,p,p)$ in the style of these earlier constructions. We characterize all colourings of
$f(n,p,p)$ in the style of these earlier constructions. We characterize all colourings of 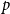 $p$-cliques with
$p$-cliques with 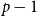 $p-1$ colours which can appear in our modified version of the
$p-1$ colours which can appear in our modified version of the 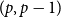 $(p,p-1)$-colouring of Conlon, Fox, Lee, and Sudakov. This allows us to greatly reduce the amount of case-checking required in identifying
$(p,p-1)$-colouring of Conlon, Fox, Lee, and Sudakov. This allows us to greatly reduce the amount of case-checking required in identifying 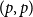 $(p,p)$-colourings, which would otherwise make this problem intractable for large values of
$(p,p)$-colourings, which would otherwise make this problem intractable for large values of 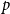 $p$. In addition, we generalize our algebraic colouring from the
$p$. In addition, we generalize our algebraic colouring from the 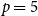 $p=5$ setting and use this to give improved upper bounds on
$p=5$ setting and use this to give improved upper bounds on 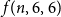 $f(n,6,6)$ and
$f(n,6,6)$ and 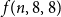 $f(n,8,8)$.
$f(n,8,8)$.
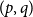
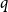
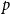
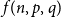
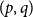
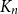
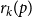
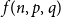
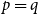
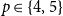
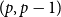
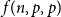
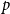
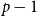
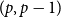
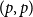
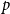
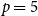
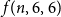
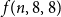
6 - Statistical Mechanics
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 110-162
-
- Chapter
- Export citation
13 - Tipping Points, Transitions and Forecasting
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 387-396
-
- Chapter
- Export citation
9 - Information Theory and Entropy
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 230-278
-
- Chapter
- Export citation
II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 87-400
-
- Chapter
- Export citation
11 - Agent-Based Modelling
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 324-355
-
- Chapter
- Export citation
10 - Stochastic Dynamics and Equations for the Probabilities
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 279-323
-
- Chapter
- Export citation
14 - Concluding Comments and a Look to the Future
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 397-400
-
- Chapter
- Export citation
4 - The Value of Prototypical Models of Emergence
- from I - Conceptual Foundation of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 75-86
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp iv-iv
-
- Chapter
- Export citation
Dedication
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp v-vi
-
- Chapter
- Export citation
