Refine search
Actions for selected content:
48287 results in Computer Science
Reimer's Inequality on a Finite Distributive Lattice
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. 612-621
-
- Article
- Export citation
Computability structures, simulations and realizability
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 05 June 2013, e240201
-
- Article
- Export citation

Noncommutative Rational Series with Applications
-
- Published online:
- 05 June 2013
- Print publication:
- 14 October 2010

Applied Combinatorics on Words
-
- Published online:
- 05 June 2013
- Print publication:
- 11 July 2005

Boolean Models and Methods in Mathematics, Computer Science, and Engineering
-
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010

Solving Polynomial Equation Systems II
- Macaulay's Paradigm and Gröbner Technology
-
- Published online:
- 05 June 2013
- Print publication:
- 05 May 2005

Systematic Program Design
- From Clarity to Efficiency
-
- Published online:
- 05 June 2013
- Print publication:
- 20 May 2013

Next Generation Wireless LANs
- 802.11n and 802.11ac
-
- Published online:
- 05 June 2013
- Print publication:
- 23 May 2013
Truth versus information in logic programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 03 June 2013, pp. 803-840
-
- Article
- Export citation
Complexity of OM factorizations of polynomials over local fields
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 June 2013, pp. 139-171
-
- Article
-
- You have access
- Export citation
-
Let
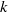 $k$ be a locally compact complete field with respect to a discrete valuation
$k$ be a locally compact complete field with respect to a discrete valuation  $v$ . Let
$v$ . Let 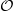 $ \mathcal{O} $ be the valuation ring,
$ \mathcal{O} $ be the valuation ring, 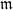 $\mathfrak{m}$ the maximal ideal and
$\mathfrak{m}$ the maximal ideal and 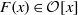 $F(x)\in \mathcal{O} [x] $ a monic separable polynomial of degree
$F(x)\in \mathcal{O} [x] $ a monic separable polynomial of degree  $n$ . Let
$n$ . Let 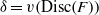 $\delta = v(\mathrm{Disc} (F))$ . The Montes algorithm computes an OM factorization of
$\delta = v(\mathrm{Disc} (F))$ . The Montes algorithm computes an OM factorization of 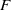 $F$ . The single-factor lifting algorithm derives from this data a factorization of
$F$ . The single-factor lifting algorithm derives from this data a factorization of 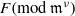 $F(\mathrm{mod~} {\mathfrak{m}}^{\nu } )$ , for a prescribed precision
$F(\mathrm{mod~} {\mathfrak{m}}^{\nu } )$ , for a prescribed precision  $\nu $ . In this paper we find a new estimate for the complexity of the Montes algorithm, leading to an estimation of
$\nu $ . In this paper we find a new estimate for the complexity of the Montes algorithm, leading to an estimation of 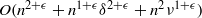 $O({n}^{2+ \epsilon } + {n}^{1+ \epsilon } {\delta }^{2+ \epsilon } + {n}^{2} {\nu }^{1+ \epsilon } )$ word operations for the complexity of the computation of a factorization of
$O({n}^{2+ \epsilon } + {n}^{1+ \epsilon } {\delta }^{2+ \epsilon } + {n}^{2} {\nu }^{1+ \epsilon } )$ word operations for the complexity of the computation of a factorization of 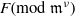 $F(\mathrm{mod~} {\mathfrak{m}}^{\nu } )$ , assuming that the residue field of
$F(\mathrm{mod~} {\mathfrak{m}}^{\nu } )$ , assuming that the residue field of 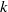 $k$ is small.
$k$ is small.

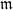
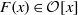

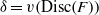
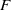
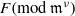

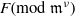
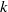
Acknowledgements
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp xiii-xiv
-
- Chapter
- Export citation
1 - Permutations
- from PART ONE - THEORY
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp 13-28
-
- Chapter
- Export citation
0 - Introduction
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp 1-10
-
- Chapter
- Export citation
A lexical semantic approach to interpreting and bracketing English noun compounds
-
- Journal:
- Natural Language Engineering / Volume 19 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 30 May 2013, pp. 385-407
-
- Article
- Export citation
