Refine search
Actions for selected content:
48579 results in Computer Science
Best parse parsing with Earley's and Inside algorithms on probabilistic RTN
-
- Journal:
- Natural Language Engineering / Volume 1 / Issue 2 / June 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 147-161
-
- Article
- Export citation
How Do Read-Once Formulae Shrink?
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 4 / December 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. 455-469
-
- Article
- Export citation
-
Let f be a de Morgan read-once function of n variables. Let fε be the random restriction obtained by independently assigning to each variable of f, the value 0 with probability (1 -ε)/2, the value 1 with the same probability, and leaving it unassigned with probability ε. We show that fε depends, on the average, on only O(εαn + εn1/α) variables, where
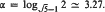 . This result is asymptotically the tightest possible. It improves a similar result obtained recently by Håstad, Razborov and Yao.
. This result is asymptotically the tightest possible. It improves a similar result obtained recently by Håstad, Razborov and Yao.
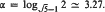 . This result is asymptotically the tightest possible. It improves a similar result obtained recently by Håstad, Razborov and Yao.
. This result is asymptotically the tightest possible. It improves a similar result obtained recently by Håstad, Razborov and Yao.t-Covering Arrays: Upper Bounds and Poisson Approximations
-
- Journal:
- Combinatorics, Probability and Computing / Volume 5 / Issue 2 / June 1996
- Published online by Cambridge University Press:
- 12 September 2008, pp. 105-117
-
- Article
- Export citation
Editorial: Issues Dedicated to Paul Erdős
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 12 September 2008, p. i
-
- Article
-
- You have access
- Export citation
A Combinatorial Approach to Complexity Theory via Ordinal Hierarchies
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. 177-190
-
- Article
- Export citation
On a Correlation Inequality of Farr
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 2 / June 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 157-160
-
- Article
- Export citation
Nearly Equal Distances in the Plane
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 4 / December 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 401-408
-
- Article
- Export citation
-
For any positive integer k and ε > 0, there exist nk,ε, ck, e > 0 with the following property. Given any system of n > nk,ε points in the plane with minimal distance at least 1 and any t1, t2…, tk ≥ 1, the number of those pairs of points whose distance is between ti and
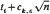 for some 1 ≤ i ≤ k, is at most (n2/2) (1 − 1/(k+1)+ε). This bound is asymptotically tight.
for some 1 ≤ i ≤ k, is at most (n2/2) (1 − 1/(k+1)+ε). This bound is asymptotically tight.
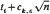 for some 1 ≤
for some 1 ≤ A Characterization of Almost-Planar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 5 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 12 September 2008, pp. 227-245
-
- Article
- Export citation
Sign-Coherent Identities for Characteristic Polynomials of Matroids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 1 / March 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 33-51
-
- Article
- Export citation
Substitution Method Critical Probability Bounds for the Square Lattice Site Percolation Model
-
- Journal:
- Combinatorics, Probability and Computing / Volume 4 / Issue 2 / June 1995
- Published online by Cambridge University Press:
- 12 September 2008, pp. 181-188
-
- Article
- Export citation
Large Induced Subgraphs with All Degrees Odd
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 335-349
-
- Article
- Export citation
An Upper Bound on Zarankiewicz' Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 5 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 12 September 2008, pp. 29-33
-
- Article
- Export citation
-
Let ex(n, K3,3) denote the maximum number of edges of a K3,3-free graph on n vertices. Improving earlier results of Kővári, T. Sós and Turán on Zarankiewicz' problem, we obtain that Brown's example for a maximal K3,3-free graph is asymptotically optimal. Hence
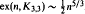 .
.
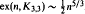 .
.Lattice Points of Cut Cones
-
- Journal:
- Combinatorics, Probability and Computing / Volume 3 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 12 September 2008, pp. 191-214
-
- Article
- Export citation
-
Let ℝ+(ℋn),ℤ(ℋn),ℤ+(ℋn) be, respectively, the cone over ℝ, the lattice and the cone over ℤ, generated by all cuts of the complete graph on n nodes. For i ≥ 0, let
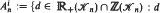 has exactly i realizations in ℤ+(ℋn)}. We show that
has exactly i realizations in ℤ+(ℋn)}. We show that 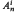 is infinite, except for the undecided case
is infinite, except for the undecided case 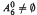 and empty
and empty 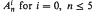 and for i = 0, n ≤ 5 and for i ≥ 2, n ≤ 3. The set contains 0,1,∞ nonsimplicial points for n ≤ 4, n = 5, n ≥ 6, respectively. On the other hand, there exists a finite number t(n) such that t(n)d ∈ ℤ+(ℋn) for any
and for i = 0, n ≤ 5 and for i ≥ 2, n ≤ 3. The set contains 0,1,∞ nonsimplicial points for n ≤ 4, n = 5, n ≥ 6, respectively. On the other hand, there exists a finite number t(n) such that t(n)d ∈ ℤ+(ℋn) for any 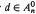 ; we also estimate such scales for classes of points. We construct families of points of
; we also estimate such scales for classes of points. We construct families of points of 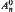 and ℤ+(ℋn), especially on a 0-lifting of a simplicial facet, and points d ∈ ℝ+(ℋn) with di, n = t for 1 ≤ i ≤ n − 1.
and ℤ+(ℋn), especially on a 0-lifting of a simplicial facet, and points d ∈ ℝ+(ℋn) with di, n = t for 1 ≤ i ≤ n − 1.
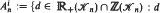 has exactly
has exactly 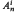 is infinite, except for the undecided case
is infinite, except for the undecided case 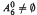 and empty
and empty 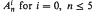 and for
and for 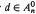 ; we also estimate such scales for classes of points. We construct families of points of
; we also estimate such scales for classes of points. We construct families of points of 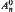 and ℤ
and ℤRecognizing Polymatroids Associated with Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 4 / December 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 519-530
-
- Article
- Export citation
Using the Perceptron Algorithm to Find Consistent Hypotheses
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 4 / December 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 385-387
-
- Article
- Export citation
Optimal Strategy for the First Player in the Penney Ante Game
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 311-321
-
- Article
- Export citation
A Group-Theoretic Setting for Some Intersecting Sperner Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 323-334
-
- Article
- Export citation
A Mildly Exponential Time Algorithm for Approximating the Number of Solutions to a Multidimensional Knapsack Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 3 / September 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. 271-284
-
- Article
- Export citation
-
We describe a
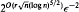 time randomized algorithm that estimates the number of feasible solutions of a multidimensional knapsack problem within 1 ± ε of the exact number. (Here r is the number of constraints and n is the number of integer variables.) The algorithm uses a Markov chain to generate an almost uniform random solution to the problem.
time randomized algorithm that estimates the number of feasible solutions of a multidimensional knapsack problem within 1 ± ε of the exact number. (Here r is the number of constraints and n is the number of integer variables.) The algorithm uses a Markov chain to generate an almost uniform random solution to the problem.
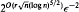 time randomized algorithm that estimates the number of feasible solutions of a multidimensional knapsack problem within 1 ±
time randomized algorithm that estimates the number of feasible solutions of a multidimensional knapsack problem within 1 ± CPC volume 2 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 2 / Issue 3 / September 1993
- Published online by Cambridge University Press:
- 12 September 2008, pp. b1-b2
-
- Article
-
- You have access
- Export citation
An Expanded Set of Correlation Tests for Linear Congruential Random Number Generators*
-
- Journal:
- Combinatorics, Probability and Computing / Volume 1 / Issue 2 / June 1992
- Published online by Cambridge University Press:
- 12 September 2008, pp. 161-168
-
- Article
- Export citation
