Refine search
Actions for selected content:
48287 results in Computer Science
Preface
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 2 / February 2022
- Published online by Cambridge University Press:
- 15 November 2022, pp. 125-126
-
- Article
-
- You have access
- HTML
- Export citation
Unifying Framework for Optimizations in Non-Boolean Formalisms
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 15 November 2022, pp. 1248-1280
-
- Article
- Export citation
Measuring the risk of corruption in Latin American political parties. De jure analysis of institutions
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 15 November 2022, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Autonomous robot navigation based on a hierarchical cognitive model
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An approach for system analysis with model-based systems engineering and graph data engineering
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Migration data collection and management in a changing Latin American landscape
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Govtech against corruption: What are the integrity dividends of government digitalization?
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A framework for ‘configuring participation’ in living labs
-
- Journal:
- Design Science / Volume 8 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting politicians’ misconduct: Evidence from Colombia
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Statistical mechanics in climate emulation: Challenges and perspectives
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 11 November 2022, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Resolving an open problem on the hazard rate ordering of p-spacings
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1020-1028
-
- Article
- Export citation
-
Let
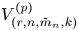 $V_{(r,n,\tilde {m}_n,k)}^{(p)}$ and
$V_{(r,n,\tilde {m}_n,k)}^{(p)}$ and 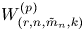 $W_{(r,n,\tilde {m}_n,k)}^{(p)}$ be the
$W_{(r,n,\tilde {m}_n,k)}^{(p)}$ be the 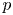 $p$-spacings of generalized order statistics based on absolutely continuous distribution functions
$p$-spacings of generalized order statistics based on absolutely continuous distribution functions 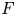 $F$ and
$F$ and 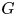 $G$, respectively. Imposing some conditions on
$G$, respectively. Imposing some conditions on 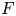 $F$ and
$F$ and 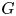 $G$ and assuming that
$G$ and assuming that 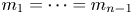 $m_1=\cdots =m_{n-1}$, Hu and Zhuang (2006. Stochastic orderings between p-spacings of generalized order statistics from two samples. Probability in the Engineering and Informational Sciences 20: 475) established
$m_1=\cdots =m_{n-1}$, Hu and Zhuang (2006. Stochastic orderings between p-spacings of generalized order statistics from two samples. Probability in the Engineering and Informational Sciences 20: 475) established 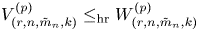 $V_{(r,n,\tilde {m}_n,k)}^{(p)} \leq _{{\rm hr}} W_{(r,n,\tilde {m}_n,k)}^{(p)}$ for
$V_{(r,n,\tilde {m}_n,k)}^{(p)} \leq _{{\rm hr}} W_{(r,n,\tilde {m}_n,k)}^{(p)}$ for 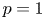 $p=1$ and left the case
$p=1$ and left the case 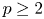 $p\geq 2$ as an open problem. In this article, we not only resolve it but also give the result for unequal
$p\geq 2$ as an open problem. In this article, we not only resolve it but also give the result for unequal 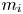 $m_i$'s. It is worth mentioning that this problem has not been proved even for ordinary order statistics so far.
$m_i$'s. It is worth mentioning that this problem has not been proved even for ordinary order statistics so far.
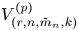
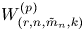
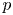
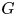
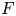
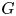
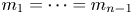
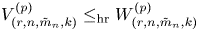
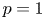
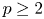
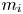

A Comparison Process for Mouse Pairs
-
- Published online:
- 10 November 2022
- Print publication:
- 24 November 2022
Analyzing a single hyper-exponential working vacation queue from its governing difference equation
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 10 November 2022, pp. 997-1019
-
- Article
- Export citation
Swift Markov Logic for Probabilistic Reasoning on Knowledge Graphs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 09 November 2022, pp. 507-534
-
- Article
- Export citation
ROB volume 40 issue 12 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ROB volume 40 issue 12 Cover and Front matter
-
- Article
-
- You have access
- Export citation
RSL volume 15 issue 4 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 07 November 2022, pp. b1-b5
- Print publication:
- December 2022
-
- Article
-
- You have access
- Export citation
