Refine search
Actions for selected content:
49475 results in Computer Science

Basic Computation and Programming with C
-
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016
-
- Textbook
- Export citation
The effects of generative AI model type and visual stimuli type on design creativity
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Managing technical risks caused by indirect interactions: insights from tracking the use of risk assessment tools
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 17 July 2025, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tracing institutional change in the officer corps using textual data from a military school: promise, pitfalls, and ethical considerations
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 16 July 2025, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development of a comprehensive bilateral trade-flow dataset of the environmental pressures of global food production
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 16 July 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Open energy services: forecasting and optimization as a service for energy management applications at scale
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 14 July 2025, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Revisiting the assumptions of the data revolution as an accelerator of the sustainable development goals
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 14 July 2025, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Empowering designers to create life cycle informed products: heuristics for extracting insights from LCA reports
- Part of
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 14 July 2025, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-driven innovation: challenges and insights of engineering design
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 14 July 2025, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dialogue-based computer-assisted language learning systems for second language speaking development: A three-level meta-analysis
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PhD Abstracts
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 35 / 2026
- Published online by Cambridge University Press:
- 14 July 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Couplings and Poisson approximation for stabilising functionals of determinantal point processes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 5 / September 2025
- Published online by Cambridge University Press:
- 11 July 2025, pp. 635-648
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Questions in design computing research and ways for exploring them: a systematic review of the DCC conference
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 10 July 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Physics-constrained machine learning for reduced composition space chemical kinetics
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 July 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Computational synthetic cohomology theory in homotopy type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 10 July 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TOPICS, NON-UNIFORM SUBSTITUTIONS, AND VARIABLE SHARING
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 1090-1120
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The family of relevant logics can be faceted by a hierarchy of increasingly fine-grained variable sharing properties—requiring that in valid entailments
 $A\to B$, some atom must appear in both A and B with some additional condition (e.g., with the same sign or nested within the same number of conditionals). In this paper, we consider an incredibly strong variable sharing property of lericone relevance that takes into account the path of negations and conditionals in which an atom appears in the parse trees of the antecedent and consequent. We show that this property of lericone relevance holds of the relevant logic
$A\to B$, some atom must appear in both A and B with some additional condition (e.g., with the same sign or nested within the same number of conditionals). In this paper, we consider an incredibly strong variable sharing property of lericone relevance that takes into account the path of negations and conditionals in which an atom appears in the parse trees of the antecedent and consequent. We show that this property of lericone relevance holds of the relevant logic 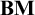 $\mathbf {BM}$ (and that a related property of faithful lericone relevance holds of
$\mathbf {BM}$ (and that a related property of faithful lericone relevance holds of 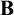 $\mathbf {B}$) and characterize the largest fragments of classical logic with these properties. Along the way, we consider the consequences for lericone relevance for the theory of subject-matter, for Logan’s notion of hyperformalism, and for the very definition of a relevant logic itself.
$\mathbf {B}$) and characterize the largest fragments of classical logic with these properties. Along the way, we consider the consequences for lericone relevance for the theory of subject-matter, for Logan’s notion of hyperformalism, and for the very definition of a relevant logic itself.

RNMATRICES FOR MODAL LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 10 July 2025, pp. 744-774
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
