Refine search
Actions for selected content:
49475 results in Computer Science
The Biophilic Instrument Pavilion: Spatialisation across disciplines
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 08 October 2025, pp. 125-135
- Print publication:
- August 2025
-
- Article
- Export citation
OTTOsonics: Designing and implementing an open and affordable 3D spatial audio system
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 01 October 2025, pp. 191-203
- Print publication:
- August 2025
-
- Article
- Export citation
Double Extension: Henri Chopin’s audiopoem performances
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 03 October 2025, pp. 221-228
- Print publication:
- August 2025
-
- Article
- Export citation
Understanding and Analysing ‘Organised Space’
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 10 September 2025, pp. 108-115
- Print publication:
- August 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Externalising Psychological Spaces in Spatial Music through Gestural Mediation
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 30 October 2025, pp. 179-190
- Print publication:
- August 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Consolidation and change: Exploring the impact of anger and network dynamics on inequality belief systems
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 01 August 2025, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial: More-than-human, more-than-music – CORRIGENDUM
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 13 February 2026, p. 229
- Print publication:
- August 2025
-
- Article
-
- You have access
- HTML
- Export citation
The Emergence of Spaces: Openness and identity/ies
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 06 October 2025, pp. 164-178
- Print publication:
- August 2025
-
- Article
- Export citation
Editorial: Perspectives and trajectories in spatial music and sonic art
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 22 January 2026, pp. 87-88
- Print publication:
- August 2025
-
- Article
-
- You have access
- HTML
- Export citation
Experience of Space in Sound: Perceptions, concepts and methods
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 11 December 2025, pp. 98-107
- Print publication:
- August 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Aural Aesthetics of Modernity: From the Philips Pavilion to EMPAC
-
- Journal:
- Organised Sound / Volume 30 / Issue 2 / August 2025
- Published online by Cambridge University Press:
- 04 September 2025, pp. 136-142
- Print publication:
- August 2025
-
- Article
- Export citation
Design knowledge for digital health implementation: a scoping review based on citation analysis
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 31 July 2025, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Notes
-
- Book:
- Onlife Criminology
- Published by:
- Bristol University Press
- Published online:
- 05 February 2026
- Print publication:
- 31 July 2025, pp 129-131
-
- Chapter
- Export citation
Generalized equilibrium distributions
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 31 July 2025, pp. 63-89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We define the generalized equilibrium distribution, that is the equilibrium distribution of a random variable with support in
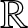 $\mathbb{R}$. This concept allows us to prove a new probabilistic generalization of Taylor’s theorem. Then, the generalized equilibrium distribution of two ordered random variables is considered and a probabilistic analog of the mean value theorem is proved. Results regarding distortion-based models and mean-median-mode relations are illustrated as well. Conditions for the unimodality of such distributions are obtained. We show that various stochastic orders and aging classes are preserved through the proposed equilibrium transformations. Further applications are provided in actuarial science, aiming to employ the new unimodal equilibrium distributions for some risk measures, such as Value-at-Risk and Conditional Tail Expectation.
$\mathbb{R}$. This concept allows us to prove a new probabilistic generalization of Taylor’s theorem. Then, the generalized equilibrium distribution of two ordered random variables is considered and a probabilistic analog of the mean value theorem is proved. Results regarding distortion-based models and mean-median-mode relations are illustrated as well. Conditions for the unimodality of such distributions are obtained. We show that various stochastic orders and aging classes are preserved through the proposed equilibrium transformations. Further applications are provided in actuarial science, aiming to employ the new unimodal equilibrium distributions for some risk measures, such as Value-at-Risk and Conditional Tail Expectation.
6 - Toxic Onlife Infowarfare
-
- Book:
- Onlife Criminology
- Published by:
- Bristol University Press
- Published online:
- 05 February 2026
- Print publication:
- 31 July 2025, pp 75-92
-
- Chapter
- Export citation
2 - Enter the Captaverse: An Epistemological Analysis of Data and Harm
-
- Book:
- Onlife Criminology
- Published by:
- Bristol University Press
- Published online:
- 05 February 2026
- Print publication:
- 31 July 2025, pp 16-23
-
- Chapter
- Export citation
Knowledge graph-assisted design-by-analogy: promoting product innovation through structured analogical knowledge retrieval
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - The Smart Surveillance of All
-
- Book:
- Onlife Criminology
- Published by:
- Bristol University Press
- Published online:
- 05 February 2026
- Print publication:
- 31 July 2025, pp 24-41
-
- Chapter
- Export citation
