Refine listing
Actions for selected content:
239 results in 65Cxx
Approximations of geometrically ergodic reversible markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 November 2021, pp. 981-1022
- Print publication:
- December 2021
-
- Article
- Export citation
-
A common tool in the practice of Markov chain Monte Carlo (MCMC) is to use approximating transition kernels to speed up computation when the desired kernel is slow to evaluate or is intractable. A limited set of quantitative tools exists to assess the relative accuracy and efficiency of such approximations. We derive a set of tools for such analysis based on the Hilbert space generated by the stationary distribution we intend to sample,
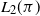 $L_2(\pi)$. Our results apply to approximations of reversible chains which are geometrically ergodic, as is typically the case for applications to MCMC. The focus of our work is on determining whether the approximating kernel will preserve the geometric ergodicity of the exact chain, and whether the approximating stationary distribution will be close to the original stationary distribution. For reversible chains, our results extend the results of Johndrow et al. (2015) from the uniformly ergodic case to the geometrically ergodic case, under some additional regularity conditions. We then apply our results to a number of approximate MCMC algorithms.
$L_2(\pi)$. Our results apply to approximations of reversible chains which are geometrically ergodic, as is typically the case for applications to MCMC. The focus of our work is on determining whether the approximating kernel will preserve the geometric ergodicity of the exact chain, and whether the approximating stationary distribution will be close to the original stationary distribution. For reversible chains, our results extend the results of Johndrow et al. (2015) from the uniformly ergodic case to the geometrically ergodic case, under some additional regularity conditions. We then apply our results to a number of approximate MCMC algorithms.
WEIGHTED INTER-RATER AGREEMENT MEASURES FOR ORDINAL OUTCOMES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 01 October 2021, pp. 173-174
- Print publication:
- February 2022
-
- Article
-
- You have access
- HTML
- Export citation
Diffusion approximation of multi-class Hawkes processes: Theoretical and numerical analysis
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 716-756
- Print publication:
- September 2021
-
- Article
- Export citation
Rejection- and importance-sampling-based perfect simulation for Gibbs hard-sphere models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 839-885
- Print publication:
- September 2021
-
- Article
- Export citation
Exact simulation of Ornstein–Uhlenbeck tempered stable processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 347-371
- Print publication:
- June 2021
-
- Article
- Export citation
Markov chain approximation of one-dimensional sticky diffusions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 335-369
- Print publication:
- June 2021
-
- Article
- Export citation
Solving high-dimensional optimal stopping problems using deep learning
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 32 / Issue 3 / June 2021
- Published online by Cambridge University Press:
- 27 April 2021, pp. 470-514
-
- Article
-
- You have access
- Open access
- Export citation
Modelling Burglary in Chicago using a self-exciting point process with isotropic triggering
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 33 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 08 April 2021, pp. 369-391
-
- Article
- Export citation
Simple conditions for metastability of continuous Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 83-105
- Print publication:
- March 2021
-
- Article
- Export citation
-
A family
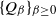 $\{Q_{\beta}\}_{\beta \geq 0}$ of Markov chains is said to exhibit metastable mixing with modes
$\{Q_{\beta}\}_{\beta \geq 0}$ of Markov chains is said to exhibit metastable mixing with modes 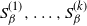 $S_{\beta}^{(1)},\ldots,S_{\beta}^{(k)}$ if its spectral gap (or some other mixing property) is very close to the worst conductance
$S_{\beta}^{(1)},\ldots,S_{\beta}^{(k)}$ if its spectral gap (or some other mixing property) is very close to the worst conductance 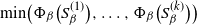 $\min\!\big(\Phi_{\beta}\big(S_{\beta}^{(1)}\big), \ldots, \Phi_{\beta}\big(S_{\beta}^{(k)}\big)\big)$ of its modes for all large values of
$\min\!\big(\Phi_{\beta}\big(S_{\beta}^{(1)}\big), \ldots, \Phi_{\beta}\big(S_{\beta}^{(k)}\big)\big)$ of its modes for all large values of 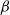 $\beta$. We give simple sufficient conditions for a family of Markov chains to exhibit metastability in this sense, and verify that these conditions hold for a prototypical Metropolis–Hastings chain targeting a mixture distribution. The existing metastability literature is large, and our present work is aimed at filling the following small gap: finding sufficient conditions for metastability that are easy to verify for typical examples from statistics using well-studied methods, while at the same time giving an asymptotically exact formula for the spectral gap (rather than a bound that can be very far from sharp). Our bounds from this paper are used in a companion paper (O. Mangoubi, N. S. Pillai, and A. Smith, arXiv:1808.03230) to compare the mixing times of the Hamiltonian Monte Carlo algorithm and a random walk algorithm for multimodal target distributions.
$\beta$. We give simple sufficient conditions for a family of Markov chains to exhibit metastability in this sense, and verify that these conditions hold for a prototypical Metropolis–Hastings chain targeting a mixture distribution. The existing metastability literature is large, and our present work is aimed at filling the following small gap: finding sufficient conditions for metastability that are easy to verify for typical examples from statistics using well-studied methods, while at the same time giving an asymptotically exact formula for the spectral gap (rather than a bound that can be very far from sharp). Our bounds from this paper are used in a companion paper (O. Mangoubi, N. S. Pillai, and A. Smith, arXiv:1808.03230) to compare the mixing times of the Hamiltonian Monte Carlo algorithm and a random walk algorithm for multimodal target distributions.
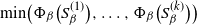
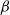
Exact simulation for multivariate Itô diffusions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 03 December 2020, pp. 1003-1034
- Print publication:
- December 2020
-
- Article
- Export citation
Central limit theorems for coupled particle filters
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 September 2020, pp. 942-1001
- Print publication:
- September 2020
-
- Article
- Export citation
-
In this article we prove new central limit theorems (CLTs) for several coupled particle filters (CPFs). CPFs are used for the sequential estimation of the difference of expectations with respect to filters which are in some sense close. Examples include the estimation of the filtering distribution associated to different parameters (finite difference estimation) and filters associated to partially observed discretized diffusion processes (PODDP) and the implementation of the multilevel Monte Carlo (MLMC) identity. We develop new theory for CPFs, and based upon several results, we propose a new CPF which approximates the maximal coupling (MCPF) of a pair of predictor distributions. In the context of ML estimation associated to PODDP with time-discretization
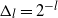 $\Delta_l=2^{-l}$,
$\Delta_l=2^{-l}$, 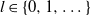 $l\in\{0,1,\dots\}$, we show that the MCPF and the approach of Jasra, Ballesio, et al. (2018) have, under certain assumptions, an asymptotic variance that is bounded above by an expression that is of (almost) the order of
$l\in\{0,1,\dots\}$, we show that the MCPF and the approach of Jasra, Ballesio, et al. (2018) have, under certain assumptions, an asymptotic variance that is bounded above by an expression that is of (almost) the order of 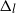 $\Delta_l$ (
$\Delta_l$ (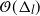 $\mathcal{O}(\Delta_l)$), uniformly in time. The
$\mathcal{O}(\Delta_l)$), uniformly in time. The 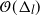 $\mathcal{O}(\Delta_l)$ bound preserves the so-called forward rate of the diffusion in some scenarios, which is not the case for the CPF in Jasra et al. (2017).
$\mathcal{O}(\Delta_l)$ bound preserves the so-called forward rate of the diffusion in some scenarios, which is not the case for the CPF in Jasra et al. (2017).
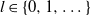
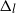
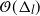
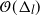
Limit theorems for sequential MCMC methods
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 15 July 2020, pp. 377-403
- Print publication:
- June 2020
-
- Article
- Export citation
-
Both sequential Monte Carlo (SMC) methods (a.k.a. ‘particle filters’) and sequential Markov chain Monte Carlo (sequential MCMC) methods constitute classes of algorithms which can be used to approximate expectations with respect to (a sequence of) probability distributions and their normalising constants. While SMC methods sample particles conditionally independently at each time step, sequential MCMC methods sample particles according to a Markov chain Monte Carlo (MCMC) kernel. Introduced over twenty years ago in [6], sequential MCMC methods have attracted renewed interest recently as they empirically outperform SMC methods in some applications. We establish an
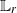 $\mathbb{L}_r$-inequality (which implies a strong law of large numbers) and a central limit theorem for sequential MCMC methods and provide conditions under which errors can be controlled uniformly in time. In the context of state-space models, we also provide conditions under which sequential MCMC methods can indeed outperform standard SMC methods in terms of asymptotic variance of the corresponding Monte Carlo estimators.
$\mathbb{L}_r$-inequality (which implies a strong law of large numbers) and a central limit theorem for sequential MCMC methods and provide conditions under which errors can be controlled uniformly in time. In the context of state-space models, we also provide conditions under which sequential MCMC methods can indeed outperform standard SMC methods in terms of asymptotic variance of the corresponding Monte Carlo estimators.
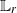
Mean reflected stochastic differential equations with jumps
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 15 July 2020, pp. 523-562
- Print publication:
- June 2020
-
- Article
- Export citation
Thinning and multilevel Monte Carlo methods for piecewise deterministic (Markov) processes with an application to a stochastic Morris–Lecar model
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 29 April 2020, pp. 138-172
- Print publication:
- March 2020
-
- Article
- Export citation
Simulation of elliptic and hypo-elliptic conditional diffusions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 29 April 2020, pp. 173-212
- Print publication:
- March 2020
-
- Article
- Export citation
-
Suppose X is a multidimensional diffusion process. Assume that at time zero the state of X is fully observed, but at time
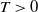 $T>0$ only linear combinations of its components are observed. That is, one only observes the vector
$T>0$ only linear combinations of its components are observed. That is, one only observes the vector 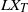 $L X_T$ for a given matrix L. In this paper we show how samples from the conditioned process can be generated. The main contribution of this paper is to prove that guided proposals, introduced in [35], can be used in a unified way for both uniformly elliptic and hypo-elliptic diffusions, even when L is not the identity matrix. This is illustrated by excellent performance in two challenging cases: a partially observed twice-integrated diffusion with multiple wells and the partially observed FitzHugh–Nagumo model.
$L X_T$ for a given matrix L. In this paper we show how samples from the conditioned process can be generated. The main contribution of this paper is to prove that guided proposals, introduced in [35], can be used in a unified way for both uniformly elliptic and hypo-elliptic diffusions, even when L is not the identity matrix. This is illustrated by excellent performance in two challenging cases: a partially observed twice-integrated diffusion with multiple wells and the partially observed FitzHugh–Nagumo model.
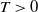
CONTRIBUTIONS TO COMPUTATIONAL BAYESIAN STATISTICS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 101 / Issue 2 / April 2020
- Published online by Cambridge University Press:
- 05 February 2020, pp. 348-349
- Print publication:
- April 2020
-
- Article
-
- You have access
- Export citation
Monte Carlo integration with a growing number of control variates
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 11 December 2019, pp. 1168-1186
- Print publication:
- December 2019
-
- Article
- Export citation
Exact simulation of the extrema of stable processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 15 November 2019, pp. 967-993
- Print publication:
- December 2019
-
- Article
- Export citation
Exact sampling for some multi-dimensional queueing models with renewal input
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 15 November 2019, pp. 1179-1208
- Print publication:
- December 2019
-
- Article
- Export citation
-
Using a result of Blanchet and Wallwater (2015) for exactly simulating the maximum of a negative drift random walk queue endowed with independent and identically distributed (i.i.d.) increments, we extend it to a multi-dimensional setting and then we give a new algorithm for simulating exactly the stationary distribution of a first-in–first-out (FIFO) multi-server queue in which the arrival process is a general renewal process and the service times are i.i.d.: the FIFO GI/GI/c queue with
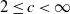 $ 2 \leq c \lt \infty$ . Our method utilizes dominated coupling from the past (DCFP) as well as the random assignment (RA) discipline, and complements the earlier work in which Poisson arrivals were assumed, such as the recent work of Connor and Kendall (2015). We also consider the models in continuous time, and show that with mild further assumptions, the exact simulation of those stationary distributions can also be achieved. We also give, using our FIFO algorithm, a new exact simulation algorithm for the stationary distribution of the infinite server case, the GI/GI/
$ 2 \leq c \lt \infty$ . Our method utilizes dominated coupling from the past (DCFP) as well as the random assignment (RA) discipline, and complements the earlier work in which Poisson arrivals were assumed, such as the recent work of Connor and Kendall (2015). We also consider the models in continuous time, and show that with mild further assumptions, the exact simulation of those stationary distributions can also be achieved. We also give, using our FIFO algorithm, a new exact simulation algorithm for the stationary distribution of the infinite server case, the GI/GI/ $\infty$ model. Finally, we even show how to handle fork–join queues, in which each arriving customer brings c jobs, one for each server.
$\infty$ model. Finally, we even show how to handle fork–join queues, in which each arriving customer brings c jobs, one for each server.
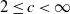
Efficient simulation of Lévy-driven point processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 51 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 15 November 2019, pp. 927-966
- Print publication:
- December 2019
-
- Article
- Export citation
