Refine listing
Actions for selected content:
239 results in 65Cxx
Error Bounds and Normalising Constants for Sequential Monte Carlo Samplers in High Dimensions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 46 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 22 February 2016, pp. 279-306
- Print publication:
- March 2014
-
- Article
-
- You have access
- Export citation
-
In this paper we develop a collection of results associated to the analysis of the sequential Monte Carlo (SMC) samplers algorithm, in the context of high-dimensional independent and identically distributed target probabilities. The SMC samplers algorithm can be designed to sample from a single probability distribution, using Monte Carlo to approximate expectations with respect to this law. Given a target density in d dimensions our results are concerned with d → ∞, while the number of Monte Carlo samples, N, remains fixed. We deduce an explicit bound on the Monte-Carlo error for estimates derived using the SMC sampler and the exact asymptotic relative
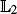 -error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is O(Nd 2).
-error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is O(Nd 2).
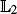 -error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is
-error of the estimate of the normalising constant associated to the target. We also establish marginal propagation of chaos properties of the algorithm. These results are deduced when the cost of the algorithm is Efficient Simulation of Large Deviation Events for Sums of Random Vectors Using Saddle-Point Representations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 50 / Issue 3 / September 2013
- Published online by Cambridge University Press:
- 30 January 2018, pp. 703-720
- Print publication:
- September 2013
-
- Article
-
- You have access
- Export citation
Overlap Problems on the Circle
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 45 / Issue 3 / September 2013
- Published online by Cambridge University Press:
- 04 January 2016, pp. 773-790
- Print publication:
- September 2013
-
- Article
-
- You have access
- Export citation
Corrigendum: On the use of a discrete form of the Itô formula in the article ‘Almost sure asymptotic stability analysis of the
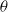 $\theta $ -Maruyama method applied to a test system with stabilising and destabilising stochastic perturbations’
$\theta $ -Maruyama method applied to a test system with stabilising and destabilising stochastic perturbations’
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 September 2013, pp. 366-372
-
- Article
-
- You have access
- Export citation
Improving the Asmussen–Kroese-Type Simulation Estimators
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 4 / December 2012
- Published online by Cambridge University Press:
- 30 January 2018, pp. 1188-1193
- Print publication:
- December 2012
-
- Article
-
- You have access
- Export citation
Optimal Design of Dynamic Default Risk Measures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 4 / December 2012
- Published online by Cambridge University Press:
- 30 January 2018, pp. 967-977
- Print publication:
- December 2012
-
- Article
-
- You have access
- Export citation
Rare-Event Simulation of Heavy-Tailed Random Walks by Sequential Importance Sampling and Resampling
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 4 / December 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 1173-1196
- Print publication:
- December 2012
-
- Article
-
- You have access
- Export citation
The Convergence Rate and Asymptotic Distribution of the Bootstrap Quantile Variance Estimator for Importance Sampling
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 815-841
- Print publication:
- September 2012
-
- Article
-
- You have access
- Export citation
Approximate Sampling Formulae for General Finite-Alleles Models of Mutation
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 408-428
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
Closed-Form Asymptotic Sampling Distributions under the Coalescent with Recombination for an Arbitrary Number of Loci
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 391-407
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
Almost sure asymptotic stability analysis of the θ-Maruyama method applied to a test system with stabilising and destabilising stochastic perturbations
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 15 / May 2012
- Published online by Cambridge University Press:
- 01 April 2012, pp. 71-83
-
- Article
-
- You have access
- Export citation
Numerical Methods for the Exit Time of a Piecewise-Deterministic Markov Process
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 1 / March 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 196-225
- Print publication:
- March 2012
-
- Article
-
- You have access
- Export citation
On the Monitoring Error of the Supremum of a Normal Jump Diffusion Process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1021-1034
- Print publication:
- December 2011
-
- Article
-
- You have access
- Export citation
Efficient Estimation of One-Dimensional Diffusion First Passage Time Densities via Monte Carlo Simulation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 3 / September 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 699-712
- Print publication:
- September 2011
-
- Article
-
- You have access
- Export citation
A comparison of cross-entropy and variance minimization strategies
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue A / August 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 183-194
- Print publication:
- August 2011
-
- Article
-
- You have access
- Export citation
Exact simulation of the stationary distribution of the FIFO M/G/c queue
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue A / August 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 209-213
- Print publication:
- August 2011
-
- Article
-
- You have access
- Export citation
On exact sampling of stochastic perpetuities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue A / August 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 165-182
- Print publication:
- August 2011
-
- Article
-
- You have access
- Export citation
Efficient Simulation for the Maximum of Infinite Horizon Discrete-Time Gaussian Processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 467-489
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Exact Monte Carlo simulation for fork-join networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 484-503
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Approximation of bounds on mixed-level orthogonal arrays
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 399-421
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
