Refine listing
Actions for selected content:
239 results in 65Cxx
Conditional sampling for spectrally discrete max-stable random fields
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 461-483
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Large deviations for a feed-forward network
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 545-571
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
A Technique for Computing the PDFs and CDFs of Nonnegative Infinitely Divisible Random Variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 217-237
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
A Markov Chain Analysis of Genetic Algorithms: Large Deviation Principle Approach
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 47 / Issue 4 / December 2010
- Published online by Cambridge University Press:
- 14 July 2016, pp. 967-975
- Print publication:
- December 2010
-
- Article
-
- You have access
- Export citation
Application of the Kusuoka approximation with a tree-based branching algorithm to the pricing of interest-rate derivatives under the HJM model
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 13 / January 2010
- Published online by Cambridge University Press:
- 01 July 2010, pp. 208-221
-
- Article
-
- You have access
- Export citation
Geometric Convergence of Genetic Algorithms Under Tempered Random Restart
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 46 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 14 July 2016, pp. 960-974
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
Likelihood-based inference for Matérn type-III repulsive point processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 41 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 01 July 2016, pp. 958-977
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
Does Waste Recycling Really Improve the Multi-Proposal Metropolis–Hastings algorithm? an Analysis Based on Control Variates
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 46 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 14 July 2016, pp. 938-959
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
ADVANCES IN CROSS-ENTROPY METHODS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 80 / Issue 3 / December 2009
- Published online by Cambridge University Press:
- 02 October 2009, pp. 521-522
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
Importance Sampling for Failure Probabilities in Computing and Data Transmission
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 46 / Issue 3 / September 2009
- Published online by Cambridge University Press:
- 14 July 2016, pp. 768-790
- Print publication:
- September 2009
-
- Article
-
- You have access
- Export citation
Fixed Precision MCMC Estimation by Median of Products of Averages
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 46 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 14 July 2016, pp. 309-329
- Print publication:
- June 2009
-
- Article
-
- You have access
- Export citation
-
The standard Markov chain Monte Carlo method of estimating an expected value is to generate a Markov chain which converges to the target distribution and then compute correlated sample averages. In many applications the quantity of interest θ is represented as a product of expected values, θ = µ 1 ⋯ µ k , and a natural estimator is a product of averages. To increase the confidence level, we can compute a median of independent runs. The goal of this paper is to analyze such an estimator
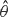 , i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for to have fixed relative precision at a given level of confidence, that is, to satisfy
, i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for to have fixed relative precision at a given level of confidence, that is, to satisfy 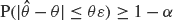 . Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
. Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
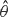 , i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for
, i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for 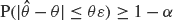 . Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
. Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.A discrete-time approximation for doubly reflected BSDEs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 41 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 July 2016, pp. 101-130
- Print publication:
- March 2009
-
- Article
-
- You have access
- Export citation
Monte Carlo methods for backward equations in nonlinear filtering
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 41 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 July 2016, pp. 63-100
- Print publication:
- March 2009
-
- Article
-
- You have access
- Export citation
THE BEST LEAST ABSOLUTE DEVIATIONS LINE – PROPERTIES AND TWO EFFICIENT METHODS FOR ITS DERIVATION
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 50 / Issue 2 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 185-198
-
- Article
-
- You have access
- Export citation
Perfect sampling methods for random forests
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 3 / September 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 897-917
- Print publication:
- September 2008
-
- Article
-
- You have access
- Export citation
Using systematic sampling selection for Monte Carlo solutions of Feynman-Kac equations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 454-472
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
Monte Carlo methods for sensitivity analysis of Poisson-driven stochastic systems, and applications
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 293-320
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
Large deviation estimates of the crossing probability for pinned Gaussian processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 424-453
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
A Variable Step Size Riemannian Sum for an Itô Integral
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 45 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 14 July 2016, pp. 551-567
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
A characterization of the first hitting time of double integral processes to curved boundaries
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 501-528
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
