Refine search
Actions for selected content:
53182 results in Statistics and Probability
Part III - Methodological Challenges of Experimentation in Sociology
-
- Book:
- Experimental Sociology
- Published online:
- 23 November 2024
- Print publication:
- 21 November 2024, pp 117-158
-
- Chapter
- Export citation
7 - Statistical Analysis
- from Part II - Evaluation for Classification
-
- Book:
- Machine Learning Evaluation
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 154-208
-
- Chapter
- Export citation
10 - Wiener Measure and Partial Differential Equations
-
- Book:
- Probability Theory, An Analytic View
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 334-383
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Machine Learning Evaluation
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp i-iv
-
- Chapter
- Export citation
8 - Vignette Experiments
- from Part II - The Practice of Experimentation in Sociology
-
- Book:
- Experimental Sociology
- Published online:
- 23 November 2024
- Print publication:
- 21 November 2024, pp 95-105
-
- Chapter
- Export citation
Identifying risk factors for clinical Lassa fever in Sierra Leone, 2019–2021
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 20 November 2024, e177
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between age of paediatric index cases and household SARS-CoV-2 transmission
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 20 November 2024, e145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of foodborne outbreaks in Wenzhou City, China, 2012–2022
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 19 November 2024, e175
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Long induced paths in expanders
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 19 November 2024, pp. 276-282
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Noisy group testing via spatial coupling
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 19 November 2024, pp. 210-258
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the problem of identifying a small number
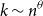 $k\sim n^\theta$,
$k\sim n^\theta$, 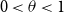 $0\lt \theta \lt 1$, of infected individuals within a large population of size
$0\lt \theta \lt 1$, of infected individuals within a large population of size  $n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to
$n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to 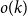 $o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.
$o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.
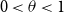

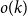
The health and demographic impacts of the “Russian flu” pandemic in Switzerland in 1889/1890 and in the years thereafter
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 19 November 2024, e174
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
FSBrick: an information model for representing fault-symptom relationships in heating, ventilation, and air conditioning systems
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic behavior of bond yields and volatilities for the extended 3/2 model under the real-world measure
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 18 November 2024, pp. 96-125
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The extended
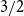 $3/2$ short rate model is a mean reverting model of the short rate which, for suitably chosen parameters, permits a sensible term structure of bond yields and closed-form valuation formulae of zero-coupon bonds and options. This article supplies proofs of the formulae for the expected present values of future cash flows under the real-world probability measure, known as actuarial valuation. Finally, we give formulae for asymptotic levels of bond yields and formulae for bond option prices for the extended
$3/2$ short rate model is a mean reverting model of the short rate which, for suitably chosen parameters, permits a sensible term structure of bond yields and closed-form valuation formulae of zero-coupon bonds and options. This article supplies proofs of the formulae for the expected present values of future cash flows under the real-world probability measure, known as actuarial valuation. Finally, we give formulae for asymptotic levels of bond yields and formulae for bond option prices for the extended 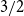 $3/2$ model, under particular conditions on its parameters.
$3/2$ model, under particular conditions on its parameters.
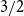
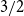
Increasing data sharing and use for social good: Lessons from Africa’s data-sharing practices during the COVID-19 response
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Outbreak of the novel Cryptosporidium parvum IIγA11 linked to salad bars in Sweden, December 2023
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e140
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction of SARS-CoV-2 infection cases based on the meta-SEIRS model
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e144
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Increased measles and rubella seroprevalence in children using residual blood samples from health facilities and household serosurveys after supplementary immunization activities in two districts in India
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sex differences in response to COVID-19 mRNA vaccines in Italian population
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e139
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adenovirus 41 diversity in Arizona (USA) using wastewater-based epidemiology, long-range PCR, and pathogen sequencing between October 2019 and March 2020
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-driven optimization of a gas turbine combustor: A Bayesian approach addressing NOx emissions, lean extinction limits, and thermoacoustic stability
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
