Refine search
Actions for selected content:
53194 results in Statistics and Probability
Negative attitudes toward older adults: Subjective time to become older and “stereotype embodiment theory”-based intervention
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 September 2022, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the study of the running maximum and minimum level of level-dependent quasi-birth–death processes and related models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 19 September 2022, pp. 14-29
- Print publication:
- March 2023
-
- Article
- Export citation
All that glitters is not gold: Relational events models with spurious events
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 16 September 2022, pp. 184-204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian assessments of aeroengine performance with transfer learning
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 15 September 2022, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Limit theory for U-statistics under geometric and topological constraints with rare events
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 14 September 2022, pp. 314-340
- Print publication:
- March 2023
-
- Article
- Export citation
-
We study the geometric and topological features of U-statistics of order k when the k-tuples satisfying geometric and topological constraints do not occur frequently. Using appropriate scaling, we establish the convergence of U-statistics in vague topology, while the structure of a non-degenerate limit measure is also revealed. Our general result shows various limit theorems for geometric and topological statistics, including persistent Betti numbers of Čech complexes, the volume of simplices, a functional of the Morse critical points, and values of the min-type distance function. The required vague convergence can be obtained as a result of the limit theorem for point processes induced by U-statistics. The latter convergence particularly occurs in the
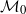 $\mathcal M_0$-topology.
$\mathcal M_0$-topology.
Trajectory design via unsupervised probabilistic learning on optimal manifolds – Corrigendum
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 14 September 2022, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Block dense weighted networks with augmented degree correction
-
- Journal:
- Network Science / Volume 10 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 14 September 2022, pp. 301-321
-
- Article
- Export citation
Strong and weak tie homophily in adolescent friendship networks: An analysis of same-race and same-gender ties
-
- Journal:
- Network Science / Volume 10 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 14 September 2022, pp. 283-300
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The impact of meteorological factors and PM2.5 on COVID-19 transmission – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 14 September 2022, e164
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal stopping under g-Expectation with
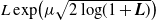 ${L}\exp\bigl(\mu\sqrt{2\log\!(1+\textbf{L})}\bigr)$-integrable reward process
${L}\exp\bigl(\mu\sqrt{2\log\!(1+\textbf{L})}\bigr)$-integrable reward process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 14 September 2022, pp. 241-252
- Print publication:
- March 2023
-
- Article
- Export citation
-
In this paper we study a class of optimal stopping problems under g-expectation, that is, the cost function is described by the solution of backward stochastic differential equations (BSDEs). Primarily, we assume that the reward process is
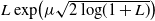 $L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$-integrable with
$L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$-integrable with 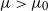 $\mu>\mu_0$ for some critical value
$\mu>\mu_0$ for some critical value 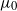 $\mu_0$. This integrability is weaker than
$\mu_0$. This integrability is weaker than 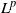 $L^p$-integrability for any
$L^p$-integrability for any 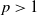 $p>1$, so it covers a comparatively wide class of optimal stopping problems. To reach our goal, we introduce a class of reflected backward stochastic differential equations (RBSDEs) with
$p>1$, so it covers a comparatively wide class of optimal stopping problems. To reach our goal, we introduce a class of reflected backward stochastic differential equations (RBSDEs) with 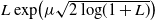 $L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$-integrable parameters. We prove the existence, uniqueness, and comparison theorem for these RBSDEs under Lipschitz-type assumptions on the coefficients. This allows us to characterize the value function of our optimal stopping problem as the unique solution of such RBSDEs.
$L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$-integrable parameters. We prove the existence, uniqueness, and comparison theorem for these RBSDEs under Lipschitz-type assumptions on the coefficients. This allows us to characterize the value function of our optimal stopping problem as the unique solution of such RBSDEs.
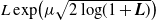
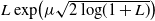
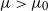
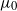
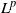
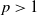
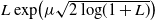
Caprylate/chromatography process to produce highly purified tetanus immune globulin from human plasma
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 13 September 2022, e172
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Critical cluster cascades
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 13 September 2022, pp. 357-381
- Print publication:
- June 2023
-
- Article
- Export citation
-
We consider a sequence of Poisson cluster point processes on
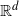 $\mathbb{R}^d$: at step
$\mathbb{R}^d$: at step 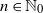 $n\in\mathbb{N}_0$ of the construction, the cluster centers have intensity
$n\in\mathbb{N}_0$ of the construction, the cluster centers have intensity 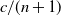 $c/(n+1)$ for some
$c/(n+1)$ for some 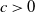 $c>0$, and each cluster consists of the particles of a branching random walk up to generation n—generated by a point process with mean 1. We show that this ‘critical cluster cascade’ converges weakly, and that either the limit point process equals the void process (extinction), or it has the same intensity c as the critical cluster cascade (persistence). We obtain persistence if and only if the Palm version of the outgrown critical branching random walk is locally almost surely finite. This result allows us to give numerous examples for persistent critical cluster cascades.
$c>0$, and each cluster consists of the particles of a branching random walk up to generation n—generated by a point process with mean 1. We show that this ‘critical cluster cascade’ converges weakly, and that either the limit point process equals the void process (extinction), or it has the same intensity c as the critical cluster cascade (persistence). We obtain persistence if and only if the Palm version of the outgrown critical branching random walk is locally almost surely finite. This result allows us to give numerous examples for persistent critical cluster cascades.
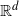
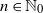
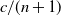
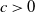
Evaluation of seed morphology, seedling genetic variation, and components for seed storage of Agave landraces of commercial interest
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 13 September 2022, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How teams adapt to exogenous shocks: Experimental evidence with node knockouts of central members
-
- Journal:
- Network Science / Volume 10 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 13 September 2022, pp. 261-282
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relaxation of the parameter independence assumption in the bootComb R package
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 13 September 2022, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Full classification of dynamics for one-dimensional continuous-time Markov chains with polynomial transition rates
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 12 September 2022, pp. 321-355
- Print publication:
- March 2023
-
- Article
- Export citation
Validity testing of the conspiratorial thinking and anti-expert sentiment scales during the COVID-19 pandemic across 24 languages from a large-scale global dataset
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 September 2022, e167
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measles epidemic in Southern Vietnam: an age-stratified spatio-temporal model for infectious disease counts
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 September 2022, e169
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A machine learning algorithm to analyse the effects of vaccination on COVID-19 mortality
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 September 2022, e168
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Social clustering of unvaccinated children in schools in the Netherlands
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 September 2022, e200
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
