Refine search
Actions for selected content:
53194 results in Statistics and Probability
Insurers’ hidden risk from reinsurance recaptures
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 09 September 2022, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nonparametric estimation of some dividend problems in the perturbed compound Poisson model
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 09 September 2022, pp. 418-441
-
- Article
-
- You have access
- HTML
- Export citation
Optimal multiple stopping problem under nonlinear expectation
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 08 September 2022, pp. 151-178
- Print publication:
- March 2023
-
- Article
- Export citation
On improved fail-safe sensor distributions for a structural health monitoring system
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 07 September 2022, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uniqueness of the Gibbs measure for the 4-state anti-ferromagnetic Potts model on the regular tree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 07 September 2022, pp. 158-182
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the
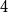 $4$-state anti-ferromagnetic Potts model with interaction parameter
$4$-state anti-ferromagnetic Potts model with interaction parameter 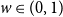 $w\in (0,1)$ on the infinite
$w\in (0,1)$ on the infinite 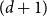 $(d+1)$-regular tree has a unique Gibbs measure if
$(d+1)$-regular tree has a unique Gibbs measure if 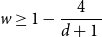 $w\geq 1-\dfrac{4}{d+1_{_{\;}}}$ for all
$w\geq 1-\dfrac{4}{d+1_{_{\;}}}$ for all 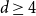 $d\geq 4$. This is tight since it is known that there are multiple Gibbs measures when
$d\geq 4$. This is tight since it is known that there are multiple Gibbs measures when 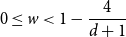 $0\leq w\lt 1-\dfrac{4}{d+1}$ and
$0\leq w\lt 1-\dfrac{4}{d+1}$ and 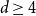 $d\geq 4$. We moreover give a new proof of the uniqueness of the Gibbs measure for the
$d\geq 4$. We moreover give a new proof of the uniqueness of the Gibbs measure for the 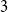 $3$-state Potts model on the
$3$-state Potts model on the 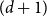 $(d+1)$-regular tree for
$(d+1)$-regular tree for 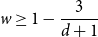 $w\geq 1-\dfrac{3}{d+1}$ when
$w\geq 1-\dfrac{3}{d+1}$ when 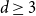 $d\geq 3$ and for
$d\geq 3$ and for 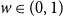 $w\in (0,1)$ when
$w\in (0,1)$ when 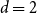 $d=2$.
$d=2$.
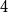
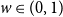
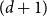
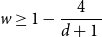
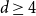
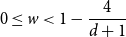
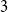
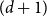
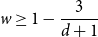
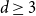
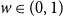
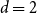
Connectivity-preserving distributed algorithms for removing links in directed networks
-
- Journal:
- Network Science / Volume 10 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 06 September 2022, pp. 215-233
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A journey toward an open data culture through transformation of shared data into a data resource
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 06 September 2022, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On connectivity and robustness of random graphs with inhomogeneity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 05 September 2022, pp. 284-294
- Print publication:
- March 2023
-
- Article
- Export citation
Application of offset estimator of differential entropy and mutual information with multivariate data
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 05 September 2022, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Matrix calculations for moments of Markov processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 126-150
- Print publication:
- March 2023
-
- Article
- Export citation
Fast mixing of a randomized shift-register Markov chain
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 253-266
- Print publication:
- March 2023
-
- Article
- Export citation
-
We present a Markov chain on the n-dimensional hypercube
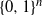 $\{0,1\}^n$ which satisfies
$\{0,1\}^n$ which satisfies 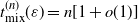 $t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
$t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most 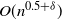 $O(n^{0.5+\delta})$, where
$O(n^{0.5+\delta})$, where 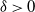 $\delta>0$. The deterministic moves correspond to a linear shift register.
$\delta>0$. The deterministic moves correspond to a linear shift register.
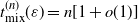
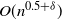
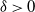
Renewal theory for iterated perturbed random walks on a general branching process tree: Early generations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 45-67
- Print publication:
- March 2023
-
- Article
- Export citation
-
Let
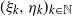 $(\xi_k,\eta_k)_{k\in\mathbb{N}}$ be independent identically distributed random vectors with arbitrarily dependent positive components. We call a (globally) perturbed random walk a random sequence
$(\xi_k,\eta_k)_{k\in\mathbb{N}}$ be independent identically distributed random vectors with arbitrarily dependent positive components. We call a (globally) perturbed random walk a random sequence 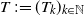 $T\,{:\!=}\, (T_k)_{k\in\mathbb{N}}$ defined by
$T\,{:\!=}\, (T_k)_{k\in\mathbb{N}}$ defined by 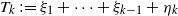 $T_k\,{:\!=}\, \xi_1+\cdots+\xi_{k-1}+\eta_k$ for
$T_k\,{:\!=}\, \xi_1+\cdots+\xi_{k-1}+\eta_k$ for 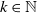 $k\in\mathbb{N}$. Consider a general branching process generated by T and let
$k\in\mathbb{N}$. Consider a general branching process generated by T and let 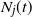 $N_j(t)$ denote the number of the jth generation individuals with birth times
$N_j(t)$ denote the number of the jth generation individuals with birth times 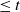 $\leq t$. We treat early generations, that is, fixed generations j which do not depend on t. In this setting we prove counterparts for
$\leq t$. We treat early generations, that is, fixed generations j which do not depend on t. In this setting we prove counterparts for 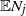 $\mathbb{E}N_j$ of the Blackwell theorem and the key renewal theorem, prove a strong law of large numbers for
$\mathbb{E}N_j$ of the Blackwell theorem and the key renewal theorem, prove a strong law of large numbers for 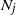 $N_j$, and find the first-order asymptotics for the variance of
$N_j$, and find the first-order asymptotics for the variance of 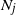 $N_j$. Also, we prove a functional limit theorem for the vector-valued process
$N_j$. Also, we prove a functional limit theorem for the vector-valued process 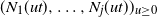 $(N_1(ut),\ldots, N_j(ut))_{u\geq0}$, properly normalized and centered, as
$(N_1(ut),\ldots, N_j(ut))_{u\geq0}$, properly normalized and centered, as 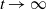 $t\to\infty$. The limit is a vector-valued Gaussian process whose components are integrated Brownian motions.
$t\to\infty$. The limit is a vector-valued Gaussian process whose components are integrated Brownian motions.
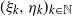
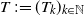
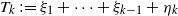
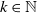
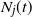
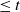
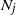
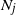
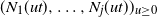
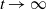
An adjacent-swap Markov chain on coalescent trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 02 September 2022, pp. 1243-1260
- Print publication:
- December 2022
-
- Article
- Export citation
-
The standard coalescent is widely used in evolutionary biology and population genetics to model the ancestral history of a sample of molecular sequences as a rooted and ranked binary tree. In this paper we present a representation of the space of ranked trees as a space of constrained ordered matched pairs. We use this representation to define ergodic Markov chains on labeled and unlabeled ranked tree shapes analogously to transposition chains on the space of permutations. We show that an adjacent-swap chain on labeled and unlabeled ranked tree shapes has a mixing time at least of order
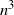 $n^3$, and at most of order
$n^3$, and at most of order 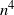 $n^{4}$. Bayesian inference methods rely on Markov chain Monte Carlo methods on the space of trees. Thus it is important to define good Markov chains which are easy to simulate and for which rates of convergence can be studied.
$n^{4}$. Bayesian inference methods rely on Markov chain Monte Carlo methods on the space of trees. Thus it is important to define good Markov chains which are easy to simulate and for which rates of convergence can be studied.
Log-normalization constant estimation using the ensemble Kalman–Bucy filter with application to high-dimensional models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 02 September 2022, pp. 1139-1163
- Print publication:
- December 2022
-
- Article
- Export citation
-
In this article we consider the estimation of the log-normalization constant associated to a class of continuous-time filtering models. In particular, we consider ensemble Kalman–Bucy filter estimates based upon several nonlinear Kalman–Bucy diffusions. Using new conditional bias results for the mean of the aforementioned methods, we analyze the empirical log-scale normalization constants in terms of their
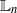 $\mathbb{L}_n$-errors and
$\mathbb{L}_n$-errors and 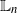 $\mathbb{L}_n$-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as
$\mathbb{L}_n$-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as 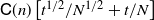 $\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$ or
$\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$ or 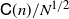 $\mathsf{C}(n)/N^{1/2}$ (
$\mathsf{C}(n)/N^{1/2}$ (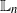 $\mathbb{L}_n$-errors) and
$\mathbb{L}_n$-errors) and 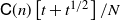 $\mathsf{C}(n)\left[t+t^{1/2}\right]/N$ or
$\mathsf{C}(n)\left[t+t^{1/2}\right]/N$ or 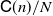 $\mathsf{C}(n)/N$ (
$\mathsf{C}(n)/N$ (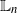 $\mathbb{L}_n$-conditional bias), where t is the time horizon, N is the ensemble size, and
$\mathbb{L}_n$-conditional bias), where t is the time horizon, N is the ensemble size, and 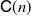 $\mathsf{C}(n)$ is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.
$\mathsf{C}(n)$ is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.
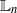
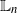
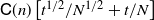
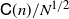
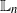
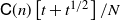
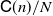
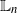
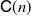
Supporting peace negotiations in the Yemen war through machine learning
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 02 September 2022, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On q-scale functions of spectrally negative Lévy processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 56-84
- Print publication:
- March 2023
-
- Article
- Export citation
EXTENDING THE LEE–CARTER MODEL WITH VARIATIONAL AUTOENCODER: A FUSION OF NEURAL NETWORK AND BAYESIAN APPROACH
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 12 September 2022, pp. 789-812
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APR volume 54 issue 3 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 18 October 2022, pp. f1-f2
- Print publication:
- September 2022
-
- Article
-
- You have access
- Export citation
ESTIMATION OF FUTURE DISCRETIONARY BENEFITS IN TRADITIONAL LIFE INSURANCE
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 06 September 2022, pp. 835-876
- Print publication:
- September 2022
-
- Article
- Export citation
APR volume 54 issue 3 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 18 October 2022, pp. b1-b2
- Print publication:
- September 2022
-
- Article
-
- You have access
- Export citation
