Refine search
Actions for selected content:
52669 results in Statistics and Probability
Housing, sanitation and living conditions affecting SARS-CoV-2 prevention interventions in 54 African countries
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 23 July 2021, e183
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IN-SAMPLE ASYMPTOTICS AND ACROSS-SAMPLE EFFICIENCY GAINS FOR HIGH FREQUENCY DATA STATISTICS
-
- Journal:
- Econometric Theory / Volume 39 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 23 July 2021, pp. 70-106
-
- Article
- Export citation
Isolation thresholds for curbing SARS-CoV-2 resurgence
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 22 July 2021, e168
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic model for COVID-19 in slums: interaction between biology and public policies
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 21 July 2021, e206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Food recalls associated with foodborne disease outbreaks, United States, 2006–2016
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 19 July 2021, e190
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the Case Fatality Ratio for COVID-19 using a Time-Shifted Distribution Analysis
-
- Journal:
- Epidemiology & Infection / Accepted manuscript
- Published online by Cambridge University Press:
- 19 July 2021, pp. 1-34
-
- Article
-
- You have access
- Open access
- Export citation
Perfect matchings, rank of connection tensors and graph homomorphisms
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 19 July 2021, pp. 268-303
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the case fatality ratio for COVID-19 using a time-shifted distribution analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 19 July 2021, e197
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring city digital twins as policy tools: A task-based approach to generating synthetic data on urban mobility
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 16 July 2021, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Notes on the Hodge conjecture for Fermat varieties
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 16 July 2021, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We review a combinatoric approach to the Hodge conjecture for Fermat varieties and announce new cases where the conjecture is true. We show the Hodge conjecture for Fermat fourfolds
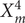 $ {X}_m^4 $ of degree m ≤ 100 coprime to 6, and also prove the conjecture for
$ {X}_m^4 $ of degree m ≤ 100 coprime to 6, and also prove the conjecture for 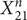 $ {X}_{21}^n $ and
$ {X}_{21}^n $ and 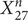 $ {X}_{27}^n $, for all n.
$ {X}_{27}^n $, for all n.
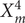
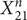
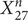
Stochastic properties of generalized finite α-mixtures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 15 July 2021, pp. 1055-1079
-
- Article
-
- You have access
- HTML
- Export citation
A closed-form pricing formula for catastrophe equity options
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 15 July 2021, pp. 1103-1115
-
- Article
- Export citation
-
In this article, we derive a closed-form pricing formula for catastrophe equity put options under a stochastic interest rate framework. A distinguishing feature of the proposed solution is its simplified form in contrast to several recently published formulae that require evaluating several layers of infinite sums of
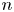 $n$-fold convoluted distribution functions. As an application of the proposed formula, we consider two different frameworks and obtain the closed-form formula for the joint characteristic function of the asset price and the losses, which is the only required ingredient in our pricing formula. The prices obtained by the newly derived formula are compared with those obtained using Monte-Carlo simulations to show the accuracy of our formula.
$n$-fold convoluted distribution functions. As an application of the proposed formula, we consider two different frameworks and obtain the closed-form formula for the joint characteristic function of the asset price and the losses, which is the only required ingredient in our pricing formula. The prices obtained by the newly derived formula are compared with those obtained using Monte-Carlo simulations to show the accuracy of our formula.
Radiation dose to the heart with hypofractionation in patients with left breast cancer
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 14 July 2021, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Equivalency in joint signatures for binary/multi-state systems of different sizes
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 14 July 2021, pp. 1027-1054
-
- Article
- Export citation
Rethinking digital identity for post-COVID-19 societies: Data privacy and human rights considerations
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 14 July 2021, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian model uncertainty quantification for hyperelastic soft tissue models
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 13 July 2021, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TAIL BEHAVIOR OF STOPPED LÉVY PROCESSES WITH MARKOV MODULATION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 13 July 2021, pp. 986-1013
-
- Article
- Export citation
Temporal concatenation for Markov decision processes
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 13 July 2021, pp. 999-1026
-
- Article
- Export citation
Research directions in policy modeling: Insights from comparative analysis of recent projects
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 13 July 2021, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How data governance technologies can democratize data sharing for community well-being
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 13 July 2021, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
