Refine search
Actions for selected content:
52669 results in Statistics and Probability
Poisson CNN: Convolutional neural networks for the solution of the Poisson equation on a Cartesian mesh
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 29 June 2021, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Poisson equation is commonly encountered in engineering, for instance, in computational fluid dynamics (CFD) where it is needed to compute corrections to the pressure field to ensure the incompressibility of the velocity field. In the present work, we propose a novel fully convolutional neural network (CNN) architecture to infer the solution of the Poisson equation on a 2D Cartesian grid with different resolutions given the right-hand side term, arbitrary boundary conditions, and grid parameters. It provides unprecedented versatility for a CNN approach dealing with partial differential equations. The boundary conditions are handled using a novel approach by decomposing the original Poisson problem into a homogeneous Poisson problem plus four inhomogeneous Laplace subproblems. The model is trained using a novel loss function approximating the continuous
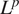 $ {L}^p $ norm between the prediction and the target. Even when predicting on grids denser than previously encountered, our model demonstrates encouraging capacity to reproduce the correct solution profile. The proposed model, which outperforms well-known neural network models, can be included in a CFD solver to help with solving the Poisson equation. Analytical test cases indicate that our CNN architecture is capable of predicting the correct solution of a Poisson problem with mean percentage errors below 10%, an improvement by comparison to the first step of conventional iterative methods. Predictions from our model, used as the initial guess to iterative algorithms like Multigrid, can reduce the root mean square error after a single iteration by more than 90% compared to a zero initial guess.
$ {L}^p $ norm between the prediction and the target. Even when predicting on grids denser than previously encountered, our model demonstrates encouraging capacity to reproduce the correct solution profile. The proposed model, which outperforms well-known neural network models, can be included in a CFD solver to help with solving the Poisson equation. Analytical test cases indicate that our CNN architecture is capable of predicting the correct solution of a Poisson problem with mean percentage errors below 10%, an improvement by comparison to the first step of conventional iterative methods. Predictions from our model, used as the initial guess to iterative algorithms like Multigrid, can reduce the root mean square error after a single iteration by more than 90% compared to a zero initial guess.
Anytime Monte Carlo
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 29 June 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Monte Carlo algorithms simulates some prescribed number of samples, taking some random real time to complete the computations necessary. This work considers the converse: to impose a real-time budget on the computation, which results in the number of samples simulated being random. To complicate matters, the real time taken for each simulation may depend on the sample produced, so that the samples themselves are not independent of their number, and a length bias with respect to compute time is apparent. This is especially problematic when a Markov chain Monte Carlo (MCMC) algorithm is used and the final state of the Markov chain—rather than an average over all states—is required, which is the case in parallel tempering implementations of MCMC. The length bias does not diminish with the compute budget in this case. It also occurs in sequential Monte Carlo (SMC) algorithms, which is the focus of this paper. We propose an anytime framework to address the concern, using a continuous-time Markov jump process to study the progress of the computation in real time. We first show that for any MCMC algorithm, the length bias of the final state’s distribution due to the imposed real-time computing budget can be eliminated by using a multiple chain construction. The utility of this construction is then demonstrated on a large-scale SMC
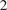 $ {}^2 $ implementation, using four billion particles distributed across a cluster of 128 graphics processing units on the Amazon EC2 service. The anytime framework imposes a real-time budget on the MCMC move steps within the SMC
$ {}^2 $ implementation, using four billion particles distributed across a cluster of 128 graphics processing units on the Amazon EC2 service. The anytime framework imposes a real-time budget on the MCMC move steps within the SMC $ {}^2 $ algorithm, ensuring that all processors are simultaneously ready for the resampling step, demonstrably reducing idleness to due waiting times and providing substantial control over the total compute budget.
$ {}^2 $ algorithm, ensuring that all processors are simultaneously ready for the resampling step, demonstrably reducing idleness to due waiting times and providing substantial control over the total compute budget.
Re: George et al. High seroprevalence of COVID-19 infection in a large slum in South India; what does it tell us about managing a pandemic and beyond?
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e152
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The contribution of telco data to fight the COVID-19 pandemic: Experience of Telefonica throughout its footprint
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the use of data from multiple mobile network operators in Europe to fight COVID-19
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development and evaluation of an outbreak surveillance system integrating whole genome sequencing data for non-typhoidal Salmonella in London and South East of England, 2016–17
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e164
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RE: George et al. ‘High seroprevalence of COVID-19 infection in a large slum in South India; what does it tell us about managing a pandemic and beyond?’
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e151
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Seroprevalence and risk factors of antibodies against Coxiella burnetii among dog owners in southwestern Québec, Canada
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 28 June 2021, e163
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
QUANTILE DOUBLE AUTOREGRESSION
-
- Journal:
- Econometric Theory / Volume 38 / Issue 4 / August 2022
- Published online by Cambridge University Press:
- 25 June 2021, pp. 793-839
-
- Article
- Export citation
The hidden potential of call detail records in The Gambia
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 25 June 2021, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
BOOTSTRAP INFERENCE FOR MULTIPLE CHANGE-POINTS IN TIME SERIES
-
- Journal:
- Econometric Theory / Volume 38 / Issue 4 / August 2022
- Published online by Cambridge University Press:
- 25 June 2021, pp. 752-792
-
- Article
- Export citation
-
In this paper, we propose two bootstrap procedures, namely parametric and block bootstrap, to approximate the finite sample distribution of change-point estimators for piecewise stationary time series. The bootstrap procedures are then used to develop a generalized likelihood ratio scan method (GLRSM) for multiple change-point inference in piecewise stationary time series, which estimates the number and locations of change-points and provides a confidence interval for each change-point. The computational complexity of using GLRSM for multiple change-point detection is as low as
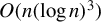 $O(n(\log n)^{3})$ for a series of length n. Extensive simulation studies are provided to demonstrate the effectiveness of the proposed methodology under different scenarios. Applications to financial time series are also illustrated.
$O(n(\log n)^{3})$ for a series of length n. Extensive simulation studies are provided to demonstrate the effectiveness of the proposed methodology under different scenarios. Applications to financial time series are also illustrated.
SARS-CoV-2 outbreak in a synagogue community: longevity and strength of anti-SARS-CoV-2 IgG responses
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 24 June 2021, e153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The French official statistics strategy: Combining signaling data from various mobile network operators for documenting COVID-19 crisis effects on population movements and economic outlook
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 24 June 2021, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Detection and viral RNA shedding of SARS-CoV-2 in respiratory specimens relative to symptom onset among COVID-19 patients in Bavaria, Germany
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 23 June 2021, e150
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of call detail records to inform the COVID-19 response in Ghana—opportunities and challenges
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 23 June 2021, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PES volume 35 issue 3 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Bridging the gaps in test interpretation of SARS-CoV-2 through Bayesian network modelling
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 23 June 2021, e166
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PES volume 35 issue 3 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Enhanced melioidosis surveillance in patients attending four tertiary hospitals in Yangon, Myanmar
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 22 June 2021, e154
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An experimental study measuring human annotator categorization agreement on commonsense sentences
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 18 June 2021, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
