Refine search
Actions for selected content:
52669 results in Statistics and Probability
On convex holes in d-dimensional point sets
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 18 June 2021, pp. 101-108
-
- Article
- Export citation
-
Given a finite set
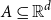 $A \subseteq \mathbb{R}^d$, points
$A \subseteq \mathbb{R}^d$, points 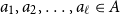 $a_1,a_2,\dotsc,a_{\ell} \in A$ form an
$a_1,a_2,\dotsc,a_{\ell} \in A$ form an 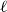 $\ell$-hole in A if they are the vertices of a convex polytope, which contains no points of A in its interior. We construct arbitrarily large point sets in general position in
$\ell$-hole in A if they are the vertices of a convex polytope, which contains no points of A in its interior. We construct arbitrarily large point sets in general position in 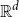 $\mathbb{R}^d$ having no holes of size
$\mathbb{R}^d$ having no holes of size 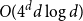 $O(4^dd\log d)$ or more. This improves the previously known upper bound of order
$O(4^dd\log d)$ or more. This improves the previously known upper bound of order 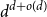 $d^{d+o(d)}$ due to Valtr. The basic version of our construction uses a certain type of equidistributed point sets, originating from numerical analysis, known as (t,m,s)-nets or (t,s)-sequences, yielding a bound of
$d^{d+o(d)}$ due to Valtr. The basic version of our construction uses a certain type of equidistributed point sets, originating from numerical analysis, known as (t,m,s)-nets or (t,s)-sequences, yielding a bound of 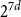 $2^{7d}$. The better bound is obtained using a variant of (t,m,s)-nets, obeying a relaxed equidistribution condition.
$2^{7d}$. The better bound is obtained using a variant of (t,m,s)-nets, obeying a relaxed equidistribution condition.
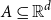
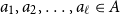
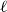
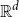
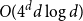
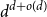
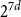
Clustered 3-colouring graphs of bounded degree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 18 June 2021, pp. 123-135
-
- Article
- Export citation
-
A (not necessarily proper) vertex colouring of a graph has clustering c if every monochromatic component has at most c vertices. We prove that planar graphs with maximum degree
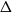 $\Delta$ are 3-colourable with clustering
$\Delta$ are 3-colourable with clustering 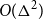 $O(\Delta^2)$. The previous best bound was
$O(\Delta^2)$. The previous best bound was 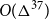 $O(\Delta^{37})$. This result for planar graphs generalises to graphs that can be drawn on a surface of bounded Euler genus with a bounded number of crossings per edge. We then prove that graphs with maximum degree
$O(\Delta^{37})$. This result for planar graphs generalises to graphs that can be drawn on a surface of bounded Euler genus with a bounded number of crossings per edge. We then prove that graphs with maximum degree  $\Delta$ that exclude a fixed minor are 3-colourable with clustering
$\Delta$ that exclude a fixed minor are 3-colourable with clustering 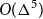 $O(\Delta^5)$. The best previous bound for this result was exponential in
$O(\Delta^5)$. The best previous bound for this result was exponential in  $\Delta$.
$\Delta$.
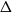
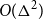
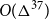
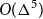
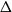

Statistics for Laboratory Scientists and Clinicians
- A Practical Guide
-
- Published online:
- 17 June 2021
- Print publication:
- 08 July 2021
6 - Range and Support of a Measure
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 123-137
-
- Chapter
- Export citation
12 - Convergence Theorems
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 235-246
-
- Chapter
- Export citation
Index
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 483-492
-
- Chapter
- Export citation
17 - Random Forests and Boosting
- from Part III - Twenty-First-Century Topics
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 335-362
-
- Chapter
- Export citation
14 - Integration and Differentiation
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 261-279
-
- Chapter
- Export citation
User’s Guide
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp xxv-xxvii
-
- Chapter
- Export citation
11 - Modes of Convergence
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 221-234
-
- Chapter
- Export citation
2 - Frequentist Inference
- from Part I - Classic Statistical Inference
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 13-22
-
- Chapter
- Export citation
List of Topics and Phenomena
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp xxviii-xxx
-
- Chapter
- Export citation
16 - Product Measures
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 295-316
-
- Chapter
- Export citation
3 - Riemann Is Not Enough
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 55-72
-
- Chapter
- Export citation
14 - Postwar Statistical Inference and Methodology
- from Part II - Early Computer-Age Methods
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 275-278
-
- Chapter
- Export citation
Dedication
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp vii-viii
-
- Chapter
- Export citation
Preface
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp xv-xvii
-
- Chapter
- Export citation
2 - A Refresher of Topology and Ordinal Numbers
-
- Book:
- Counterexamples in Measure and Integration
- Published online:
- 27 May 2021
- Print publication:
- 17 June 2021, pp 36-54
-
- Chapter
- Export citation
Part I - Classic Statistical Inference
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 1-2
-
- Chapter
- Export citation
11 - Bootstrap Confidence Intervals
- from Part II - Early Computer-Age Methods
-
- Book:
- Computer Age Statistical Inference, Student Edition
- Published online:
- 26 October 2021
- Print publication:
- 17 June 2021, pp 189-216
-
- Chapter
- Export citation
