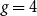Refine search
Actions for selected content:
52669 results in Statistics and Probability
9 - Applied Statistics for the Clinician
- from III - Applied Statistics
-
- Book:
- Statistics for Laboratory Scientists and Clinicians
- Published online:
- 17 June 2021
- Print publication:
- 08 July 2021, pp 135-142
-
- Chapter
- Export citation
Xanthene-stained nanoparticles for phosphorescence anisotropy measurements
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 07 July 2021, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Average-case complexity of the Euclidean algorithm with a fixed polynomial over a finite field
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 06 July 2021, pp. 166-183
-
- Article
- Export citation
-
We analyse the behaviour of the Euclidean algorithm applied to pairs (g,f) of univariate nonconstant polynomials over a finite field
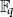 $\mathbb{F}_{q}$ of q elements when the highest degree polynomial g is fixed. Considering all the elements f of fixed degree, we establish asymptotically optimal bounds in terms of q for the number of elements f that are relatively prime with g and for the average degree of
$\mathbb{F}_{q}$ of q elements when the highest degree polynomial g is fixed. Considering all the elements f of fixed degree, we establish asymptotically optimal bounds in terms of q for the number of elements f that are relatively prime with g and for the average degree of 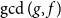 $\gcd(g,f)$. We also exhibit asymptotically optimal bounds for the average-case complexity of the Euclidean algorithm applied to pairs (g,f) as above.
$\gcd(g,f)$. We also exhibit asymptotically optimal bounds for the average-case complexity of the Euclidean algorithm applied to pairs (g,f) as above.
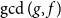
On directed analogues of expander and hyperfinite graph sequences
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 06 July 2021, pp. 184-197
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Continuous phase transitions on Galton–Watson trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 06 July 2021, pp. 198-228
-
- Article
- Export citation
-
Distinguishing between continuous and first-order phase transitions is a major challenge in random discrete systems. We study the topic for events with recursive structure on Galton–Watson trees. For example, let
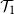 $\mathcal{T}_1$ be the event that a Galton–Watson tree is infinite and let
$\mathcal{T}_1$ be the event that a Galton–Watson tree is infinite and let 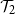 $\mathcal{T}_2$ be the event that it contains an infinite binary tree starting from its root. These events satisfy similar recursive properties:
$\mathcal{T}_2$ be the event that it contains an infinite binary tree starting from its root. These events satisfy similar recursive properties: 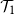 $\mathcal{T}_1$ holds if and only if
$\mathcal{T}_1$ holds if and only if 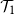 $\mathcal{T}_1$ holds for at least one of the trees initiated by children of the root, and
$\mathcal{T}_1$ holds for at least one of the trees initiated by children of the root, and 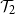 $\mathcal{T}_2$ holds if and only if
$\mathcal{T}_2$ holds if and only if 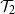 $\mathcal{T}_2$ holds for at least two of these trees. The probability of
$\mathcal{T}_2$ holds for at least two of these trees. The probability of 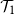 $\mathcal{T}_1$ has a continuous phase transition, increasing from 0 when the mean of the child distribution increases above 1. On the other hand, the probability of
$\mathcal{T}_1$ has a continuous phase transition, increasing from 0 when the mean of the child distribution increases above 1. On the other hand, the probability of 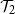 $\mathcal{T}_2$ has a first-order phase transition, jumping discontinuously to a non-zero value at criticality. Given the recursive property satisfied by the event, we describe the critical child distributions where a continuous phase transition takes place. In many cases, we also characterise the event undergoing the phase transition.
$\mathcal{T}_2$ has a first-order phase transition, jumping discontinuously to a non-zero value at criticality. Given the recursive property satisfied by the event, we describe the critical child distributions where a continuous phase transition takes place. In many cases, we also characterise the event undergoing the phase transition.
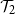
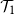
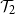
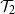
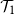
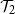
SARS-CoV-2 seroprevalence among employees of a university hospital in Belgium during the 2020 COVID-19 outbreak (COVEMUZ-study)
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 05 July 2021, e165
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The accuracy versus interpretability trade-off in fraud detection model
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 05 July 2021, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
DIVERSIFICATION IN CATASTROPHE INSURANCE MARKETS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 02 July 2021, pp. 753-778
- Print publication:
- September 2021
-
- Article
- Export citation
TAIL DEPENDENCE OF OLS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 02 July 2021, pp. 273-300
-
- Article
-
- You have access
- Open access
- Export citation
Team's seasonal win probabilities
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 02 July 2021, pp. 988-998
-
- Article
- Export citation
-
We consider a competition involving
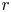 $r$ teams, where each individual game involves two teams, and where each game between teams
$r$ teams, where each individual game involves two teams, and where each game between teams 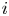 $i$ and
$i$ and 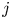 $j$ is won by
$j$ is won by 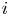 $i$ with probability
$i$ with probability 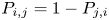 $P_{i,j} = 1 - P_{j,i}$. We suppose that
$P_{i,j} = 1 - P_{j,i}$. We suppose that 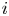 $i$ and
$i$ and 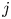 $j$ are scheduled to play
$j$ are scheduled to play 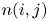 $n(i,j)$ games and say that the team that wins the most games is the winner of the competition. We show that the conditional probability that
$n(i,j)$ games and say that the team that wins the most games is the winner of the competition. We show that the conditional probability that 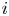 $i$ is the winner, given that
$i$ is the winner, given that 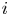 $i$ wins
$i$ wins 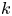 $k$ games, is increasing in
$k$ games, is increasing in 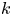 $k$. We bound the tail probability of the number of wins of the winning team. We consider the special case where
$k$. We bound the tail probability of the number of wins of the winning team. We consider the special case where 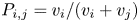 $P_{i,j} = {v_i}/{(v_i + v_j)}$, and obtain structural results on the probability that team
$P_{i,j} = {v_i}/{(v_i + v_j)}$, and obtain structural results on the probability that team 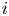 $i$ is the winner. We give efficient simulation approaches for computing the probability that team
$i$ is the winner. We give efficient simulation approaches for computing the probability that team  $i$ is the winner, and the conditional probability given the number of wins of
$i$ is the winner, and the conditional probability given the number of wins of 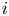 $i$.
$i$.
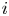
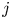
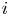
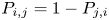
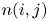
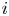
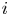
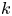
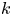
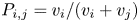
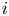
Prevalence and determinants of symptomatic COVID-19 infection among children and adolescents in Qatar: a cross-sectional analysis of 11 445 individuals
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 July 2021, e193
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AIDS-related deaths in Turkey between 2009 and 2018
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 July 2021, e191
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimation of delay-adjusted all-cause excess mortality in the USA: March–December 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 July 2021, e156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factors preventing SARS-CoV-2 transmission during unintentional exposure in a GP practice: a cohort study of patient contacts; Germany, 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 July 2021, e161
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development and validation of a clinical and genetic model for predicting risk of severe COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 July 2021, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 205-206
-
- Article
-
- You have access
- HTML
- Export citation
Large N behaviour of the two-dimensional Yang–Mills partition function
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 30 June 2021, pp. 144-165
-
- Article
- Export citation
-
We compute the large N limit of the partition function of the Euclidean Yang–Mills measure on orientable compact surfaces with genus
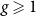 $g\geqslant 1$ and non-orientable compact surfaces with genus
$g\geqslant 1$ and non-orientable compact surfaces with genus 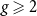 $g\geqslant 2$, with structure group the unitary group
$g\geqslant 2$, with structure group the unitary group 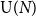 ${\mathrm U}(N)$ or special unitary group
${\mathrm U}(N)$ or special unitary group 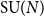 ${\mathrm{SU}}(N)$. Our proofs are based on asymptotic representation theory: more specifically, we control the dimension and Casimir number of irreducible representations of
${\mathrm{SU}}(N)$. Our proofs are based on asymptotic representation theory: more specifically, we control the dimension and Casimir number of irreducible representations of 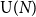 ${\mathrm U}(N)$ and
${\mathrm U}(N)$ and 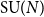 ${\mathrm{SU}}(N)$ when N tends to infinity. Our main technical tool, involving ‘almost flat’ Young diagram, makes rigorous the arguments used by Gross and Taylor (1993, Nuclear Phys. B 400(1–3) 181–208) in the setting of QCD, and in some cases, we recover formulae given by Douglas (1995, Quantum Field Theory and String Theory (Cargèse, 1993), Vol. 328 of NATO Advanced Science Institutes Series B: Physics, Plenum, New York, pp. 119–135) and Rusakov (1993, Phys. Lett. B 303(1) 95–98).
${\mathrm{SU}}(N)$ when N tends to infinity. Our main technical tool, involving ‘almost flat’ Young diagram, makes rigorous the arguments used by Gross and Taylor (1993, Nuclear Phys. B 400(1–3) 181–208) in the setting of QCD, and in some cases, we recover formulae given by Douglas (1995, Quantum Field Theory and String Theory (Cargèse, 1993), Vol. 328 of NATO Advanced Science Institutes Series B: Physics, Plenum, New York, pp. 119–135) and Rusakov (1993, Phys. Lett. B 303(1) 95–98).
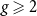
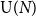
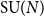
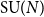
Data-based polyhedron model for optimization of engineering structures involving uncertainties
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 29 June 2021, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What is the status of nucleic acid contamination in 2019-nCOV vaccination sites? Can it be avoided?
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 29 June 2021, e155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Triangle-free subgraphs with large fractional chromatic number
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 29 June 2021, pp. 136-143
-
- Article
- Export citation
-
It is well known that for any integers k and g, there is a graph with chromatic number at least k and girth at least g. In 1960s, Erdös and Hajnal conjectured that for any k and g, there exists a number h(k,g), such that every graph with chromatic number at least h(k,g) contains a subgraph with chromatic number at least k and girth at least g. In 1977, Rödl proved the case when
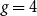 $g=4$, for arbitrary k. We prove the fractional chromatic number version of Rödl’s result.
$g=4$, for arbitrary k. We prove the fractional chromatic number version of Rödl’s result.